So in last week’s blog post we discovered how to construct an image pyramid.
And in today’s article, we are going to extend that example and introduce the concept of a sliding window. Sliding windows play an integral role in object classification, as they allow us to localize exactly “where” in an image an object resides.
Utilizing both a sliding window and an image pyramid we are able to detect objects in images at various scales and locations.
In fact, both sliding windows and image pyramids are both used in my 6-step HOG + Linear SVM object classification framework!
To learn more about the role sliding windows play in object classification and image classification, read on. By the time you are done reading this blog post, you’ll have an excellent understanding on how image pyramids and sliding windows are used for classification.
What is a sliding window?
In the context of computer vision (and as the name suggests), a sliding window is a rectangular region of fixed width and height that “slides” across an image, such as in the following figure:

For each of these windows, we would normally take the window region and apply an image classifier to determine if the window has an object that interests us — in this case, a face.
Combined with image pyramids we can create image classifiers that can recognize objects at varying scales and locations in the image.
These techniques, while simple, play an absolutely critical role in object detection and image classification.
Sliding Windows for Object Detection with Python and OpenCV
Let’s go ahead and build on your image pyramid example from last week.
But first ensure that you have OpenCV and imutils installed:
- Install OpenCV with one of my guides
- To install
imutils, use pip:pip install --upgrade imutils
Remember the helpers.py file? Open it back up and insert the sliding_window function:
# import the necessary packages import imutils def pyramid(image, scale=1.5, minSize=(30, 30)): # yield the original image yield image # keep looping over the pyramid while True: # compute the new dimensions of the image and resize it w = int(image.shape[1] / scale) image = imutils.resize(image, width=w) # if the resized image does not meet the supplied minimum # size, then stop constructing the pyramid if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]: break # yield the next image in the pyramid yield image def sliding_window(image, stepSize, windowSize): # slide a window across the image for y in range(0, image.shape[0], stepSize): for x in range(0, image.shape[1], stepSize): # yield the current window yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
The sliding_window function requires three arguments. The first is the image that we are going to loop over. The second argument is the stepSize .
The stepSize indicates how many pixels we are going to “skip” in both the (x, y) direction. Normally, we would not want to loop over each and every pixel of the image (i.e. stepSize=1 ) as this would be computationally prohibitive if we were applying an image classifier at each window.
Instead, the stepSize is determined on a per-dataset basis and is tuned to give optimal performance based on your dataset of images. In practice, it’s common to use a stepSize of 4 to 8 pixels. Remember, the smaller your step size is, the more windows you’ll need to examine.
The last argument windowSize defines the width and height (in terms of pixels) of the window we are going to extract from our image .
Lines 24-27 are fairly straightforward and handle the actual “sliding” of the window.
Lines 24-26 define two for loops that loop over the (x, y) coordinates of the image, incrementing their respective x and y counters by the provided step size.
Then, Line 27 returns a tuple containing the x and y coordinates of the sliding window, along with the window itself.
To see the sliding window in action, we’ll have to write a driver script for it. Create a new file, name it sliding_window.py , and we’ll finish up this example:
# import the necessary packages
from pyimagesearch.helpers import pyramid
from pyimagesearch.helpers import sliding_window
import argparse
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
# load the image and define the window width and height
image = cv2.imread(args["image"])
(winW, winH) = (128, 128)
On Lines 2-6 we import our necessary packages. We’ll use our pyramid function from last week to construct our image pyramid. We’ll also use the sliding_window function we just defined. Finally we import argparse for parsing command line arguments and cv2 for our OpenCV bindings.
Lines 9-12 handle parsing our command line arguments. We only need a single switch here, the --image that we want to process.
From there, Line 14 loads our image off disk and Line 15 defines our window width and height to be 128 pixels, respectfully.
Now, let’s go ahead and combine our image pyramid and sliding window:
# loop over the image pyramid
for resized in pyramid(image, scale=1.5):
# loop over the sliding window for each layer of the pyramid
for (x, y, window) in sliding_window(resized, stepSize=32, windowSize=(winW, winH)):
# if the window does not meet our desired window size, ignore it
if window.shape[0] != winH or window.shape[1] != winW:
continue
# THIS IS WHERE YOU WOULD PROCESS YOUR WINDOW, SUCH AS APPLYING A
# MACHINE LEARNING CLASSIFIER TO CLASSIFY THE CONTENTS OF THE
# WINDOW
# since we do not have a classifier, we'll just draw the window
clone = resized.copy()
cv2.rectangle(clone, (x, y), (x + winW, y + winH), (0, 255, 0), 2)
cv2.imshow("Window", clone)
cv2.waitKey(1)
time.sleep(0.025)
We start by looping over each layer of the image pyramid on Line 18.
For each layer of the image pyramid, we’ll also loop over each window in the sliding_window on Line 20. We also make a check on Lines 22-23 to ensure that our sliding window has met the minimum size requirements.
If we were applying an image classifier to detect objects, we would do this on Lines 25-27 by extracting features from the window and passing them on to our classifier (which is done in our 6-step HOG + Linear SVM object detection framework).
But since we do not have an image classifier, we’ll just visualize the sliding window results instead by drawing a rectangle on the image indicating where the sliding window is on Lines 30-34.
Results
To see our image pyramid and sliding window in action, open up a terminal and execute the following command:
$ python sliding_window.py --image images/adrian_florida.jpg
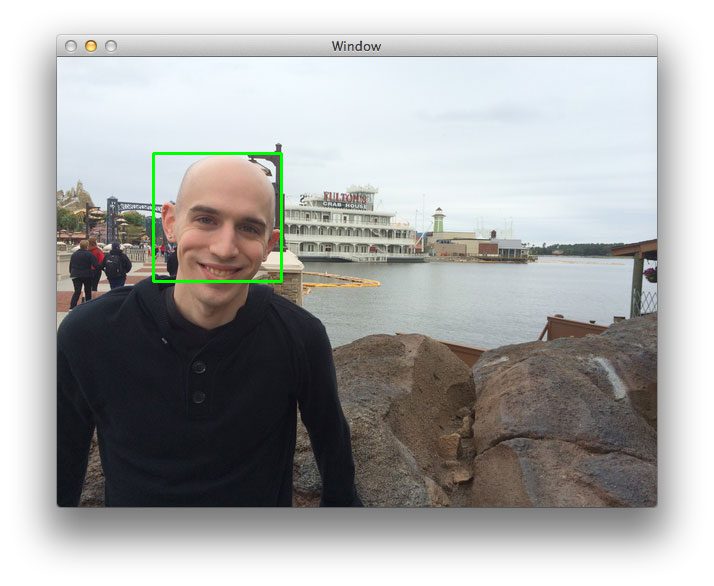
If all goes well you should see the following results:

Here you can see that for each of the layers in the pyramid a window is “slid” across it. And again, if we had an image classifier ready to go, we could take each of these windows and classify the contents of the window. An example could be “does this window contain a face or not?”
Here’s another example with a different image:
$ python sliding_window.py --image images/stick_of_truth.jpg.jpg

Once again, we can see that the sliding window is slid across the image at each level of the pyramid. High levels of the pyramid (and thus smaller layers) have fewer windows that need to be examined.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post, we learned all about sliding windows and their application to object detection and image classification.
By combining a sliding window with an image pyramid we are able to localize and detect objects in images at multiple scales and locations.
While both sliding windows and image pyramids are very simple techniques, they are absolutely critical in object detection.
You can learn more about the more global role they play in this blog post, where I detail my framework on how to use the Histogram of Oriented Gradients image descriptor and a Linear SVM classifier to build a custom object detector.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

