Last week we discussed how to use OpenCV and Python to perform pedestrian detection.
To accomplish this, we leveraged the built-in HOG + Linear SVM detector that OpenCV ships with, allowing us to detect people in images.
However, one aspect of the HOG person detector we did not discuss in detail is the detectMultiScale function; specifically, how the parameters of this function can:
- Increase the number of false-positive detections (i.e., reporting that a location in an image contains a person, but when in reality it does not).
- Result in missing a detection entirely.
- Dramatically affect the speed of the detection process.
In the remainder of this blog post I am going to breakdown each of the detectMultiScale parameters to the Histogram of Oriented Gradients descriptor and SVM detector.
I’ll also explain the trade-off between speed and accuracy that we must make if we want our pedestrian detector to run in real-time. This tradeoff is especially important if you want to run the pedestrian detector in real-time on resource constrained devices such as the Raspberry Pi.
Accessing the HOG detectMultiScale parameters
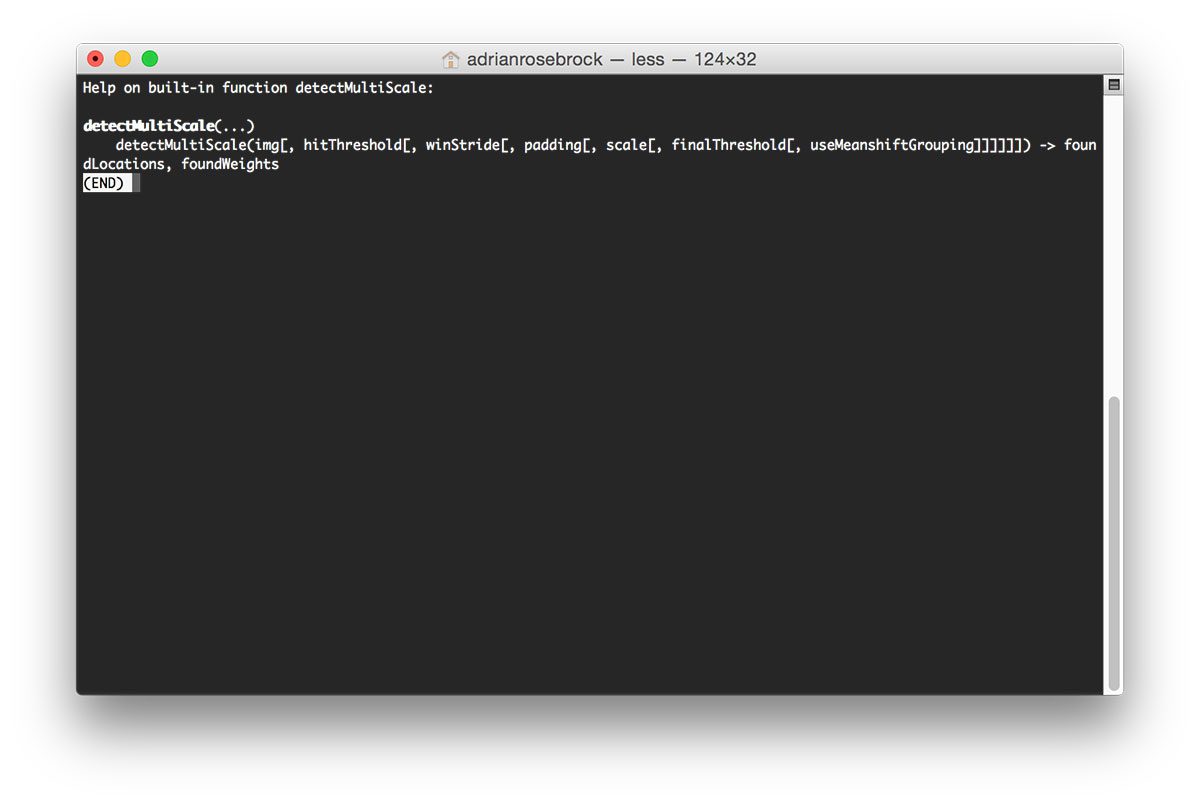
To view the parameters to the detectMultiScale function, just fire up a shell, import OpenCV, and use the help function:
$ python >>> import cv2 >>> help(cv2.HOGDescriptor().detectMultiScale)
You can use the built-in Python help method on any OpenCV function to get a full listing of parameters and returned values.
HOG detectMultiScale parameters explained
Before we can explore the detectMultiScale parameters, let’s first create a simple Python script (based on our pedestrian detector from last week) that will allow us to easily experiment:
# import the necessary packages
from __future__ import print_function
import argparse
import datetime
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-w", "--win-stride", type=str, default="(8, 8)",
help="window stride")
ap.add_argument("-p", "--padding", type=str, default="(16, 16)",
help="object padding")
ap.add_argument("-s", "--scale", type=float, default=1.05,
help="image pyramid scale")
ap.add_argument("-m", "--mean-shift", type=int, default=-1,
help="whether or not mean shift grouping should be used")
args = vars(ap.parse_args())
Since most of this script is based on last week’s post, I’ll do a more quick overview of the code.
Lines 9-20 handle parsing our command line arguments The --image switch is the path to our input image that we want to detect pedestrians in. The --win-stride is the step size in the x and y direction of our sliding window. The --padding switch controls the amount of pixels the ROI is padded with prior to HOG feature vector extraction and SVM classification. To control the scale of the image pyramid (allowing us to detect people in images at multiple scales), we can use the --scale argument. And finally, --mean-shift can be specified if we want to apply mean-shift grouping to the detected bounding boxes.
# evaluate the command line arguments (using the eval function like # this is not good form, but let's tolerate it for the example) winStride = eval(args["win_stride"]) padding = eval(args["padding"]) meanShift = True if args["mean_shift"] > 0 else False # initialize the HOG descriptor/person detector hog = cv2.HOGDescriptor() hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()) # load the image and resize it image = cv2.imread(args["image"]) image = imutils.resize(image, width=min(400, image.shape[1]))
Now that we have our command line arguments parsed, we need to extract their tuple and boolean values respectively on Lines 24-26. Using the eval function, especially on command line arguments, is not good practice, but let’s tolerate it for the sake of this example (and for the ease of allowing us to play with different --win-stride and --padding values).
Lines 29 and 30 initialize the Histogram of Oriented Gradients detector and sets the Support Vector Machine detector to be the default pedestrian detector included with OpenCV.
From there, Lines 33 and 34 load our image and resize it to have a maximum width of 400 pixels — the smaller our image is, the faster it will be to process and detect people in it.
# detect people in the image
start = datetime.datetime.now()
(rects, weights) = hog.detectMultiScale(image, winStride=winStride,
padding=padding, scale=args["scale"], useMeanshiftGrouping=meanShift)
print("[INFO] detection took: {}s".format(
(datetime.datetime.now() - start).total_seconds()))
# draw the original bounding boxes
for (x, y, w, h) in rects:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Detections", image)
cv2.waitKey(0)
Lines 37-41 detect pedestrians in our image using the detectMultiScale function and the parameters we supplied via command line arguments. We’ll start and stop a timer on Line 37 and 41 allowing us to determine how long it takes a single image to process for a given set of parameters.
Finally, Lines 44-49 draw the bounding box detections on our image and display the output to our screen.
To get a default baseline in terms of object detection timing, just execute the following command:
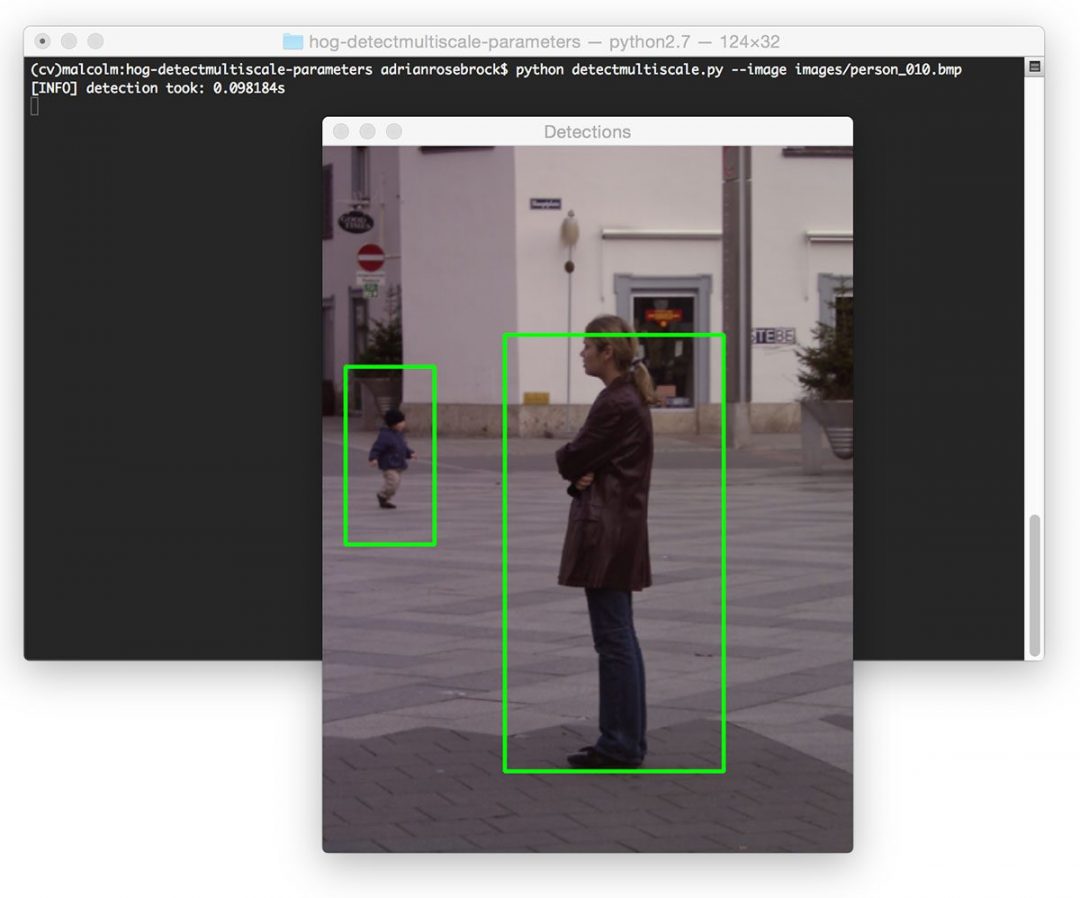
$ python detectmultiscale.py --image images/person_010.bmp
On my MacBook Pro, the detection process takes a total of 0.09s, implying that I can process approximately 10 images per second:
In the rest of this lesson we’ll explore the parameters to detectMultiScale in detail, along with the implications these parameters have on detection timing.
img (required)
This parameter is pretty obvious — it’s the image that we want to detect objects (in this case, people) in. This is the only required argument to the detectMultiScale function. The image we pass in can either be color or grayscale.
hitThreshold (optional)
The hitThreshold parameter is optional and is not used by default in the detectMultiScale function.
When I looked at the OpenCV documentation for this function and the only description for the parameter is: “Threshold for the distance between features and SVM classifying plane”.
Given the sparse documentation of the parameter (and the strange behavior of it when I was playing around with it for pedestrian detection), I believe that this parameter controls the maximum Euclidean distance between the input HOG features and the classifying plane of the SVM. If the Euclidean distance exceeds this threshold, the detection is rejected. However, if the distance is below this threshold, the detection is accepted.
My personal opinion is that you shouldn’t bother playing around this parameter unless you are seeing an extremely high rate of false-positive detections in your image. In that case, it might be worth trying to set this parameter. Otherwise, just let non-maxima suppression take care of any overlapping bounding boxes, as we did in the previous lesson.
winStride (optional)
The winStride parameter is a 2-tuple that dictates the “step size” in both the x and y location of the sliding window.
Both winStride and scale are extremely important parameters that need to be set properly. These parameter have tremendous implications on not only the accuracy of your detector, but also the speed in which your detector runs.
In the context of object detection, a sliding window is a rectangular region of fixed width and height that “slides” across an image, just like in the following figure:

At each stop of the sliding window (and for each level of the image pyramid, discussed in the scale section below), we (1) extract HOG features and (2) pass these features on to our Linear SVM for classification. The process of feature extraction and classifier decision is an expensive one, so we would prefer to evaluate as little windows as possible if our intention is to run our Python script in near real-time.
The smaller winStride is, the more windows need to be evaluated (which can quickly turn into quite the computational burden):
$ python detectmultiscale.py --image images/person_010.bmp --win-stride="(4, 4)"
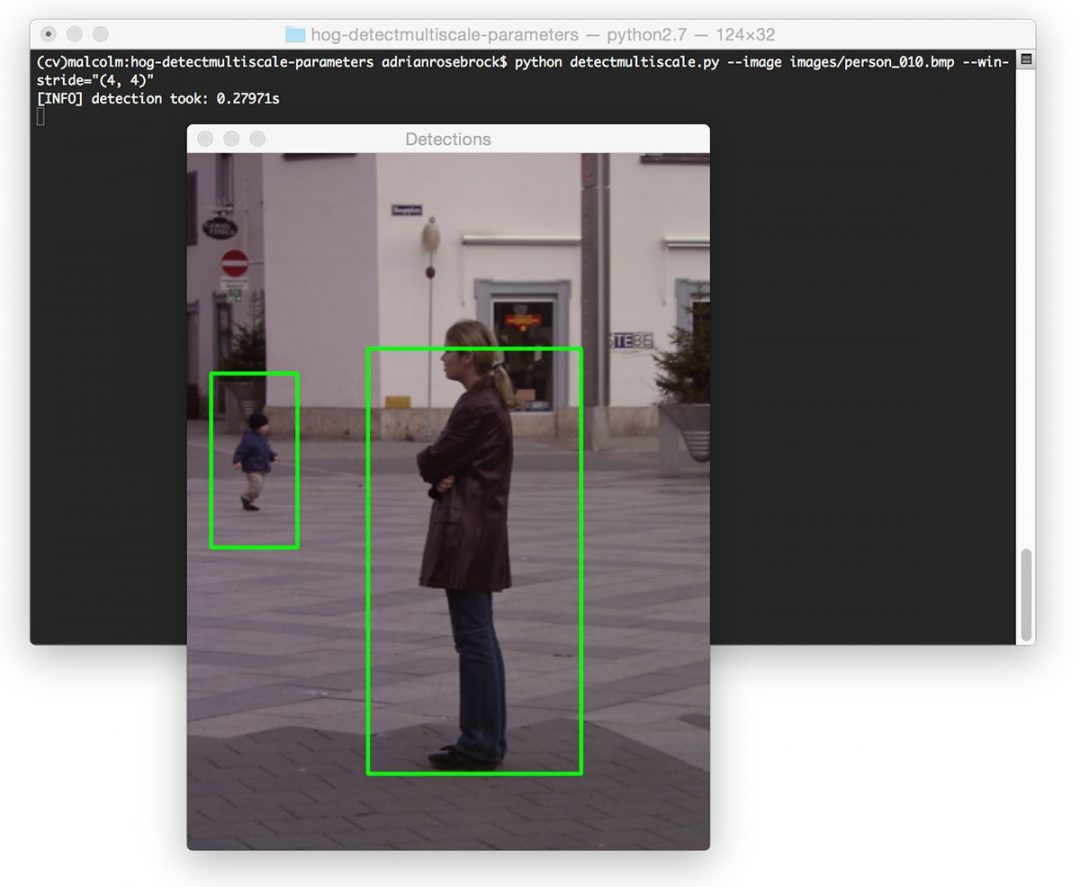
Here we can see that decreasing the winStride to (4, 4) has actually increased our detection time substantially to 0.27s.
Similarly, the larger winStride is the less windows need to be evaluated (allowing us to dramatically speed up our detector). However, if winStride gets too large, then we can easily miss out on detections entirely:
$ python detectmultiscale.py --image images/person_010.bmp --win-stride="(16, 16)"
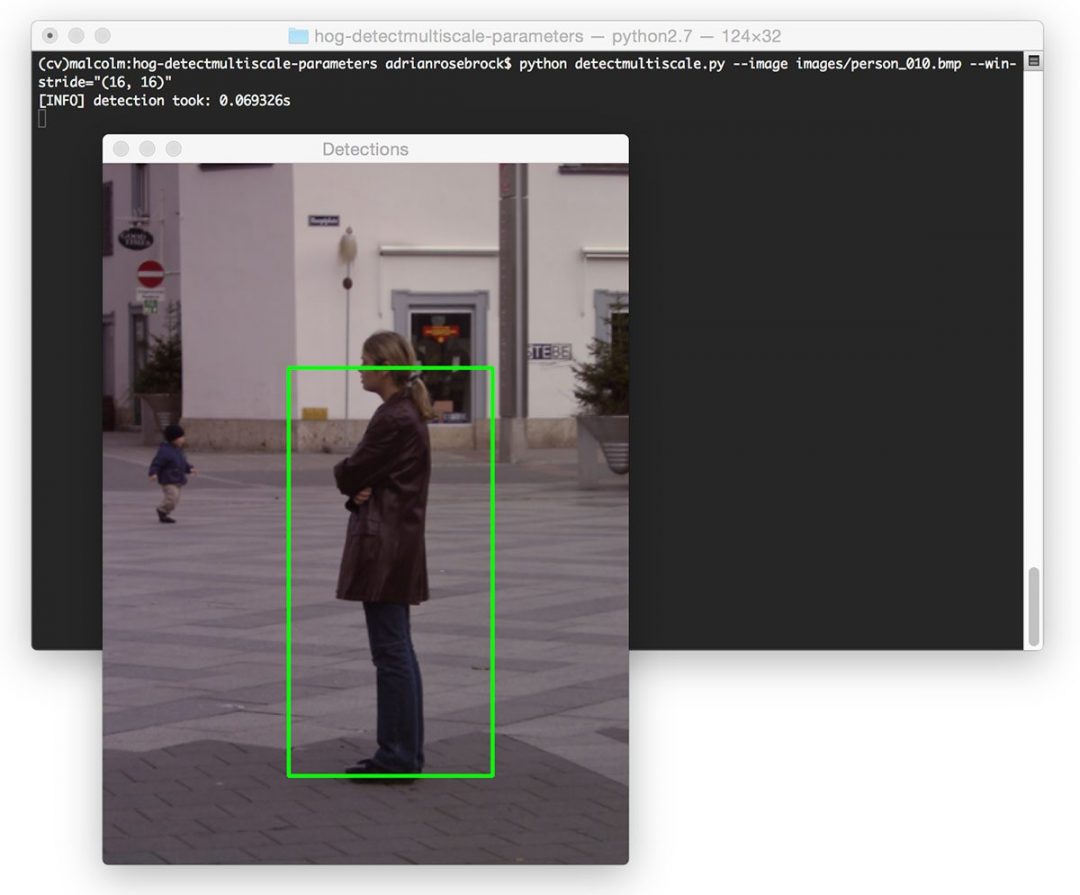
I tend to start off using a winStride value of (4, 4) and increase the value until I obtain a reasonable trade-off between speed and detection accuracy.
padding (optional)
The padding parameter is a tuple which indicates the number of pixels in both the x and y direction in which the sliding window ROI is “padded” prior to HOG feature extraction.
As suggested by Dalal and Triggs in their 2005 CVPR paper, Histogram of Oriented Gradients for Human Detection, adding a bit of padding surrounding the image ROI prior to HOG feature extraction and classification can actually increase the accuracy of your detector.
Typical values for padding include (8, 8), (16, 16), (24, 24), and (32, 32).
scale (optional)
An image pyramid is a multi-scale representation of an image:
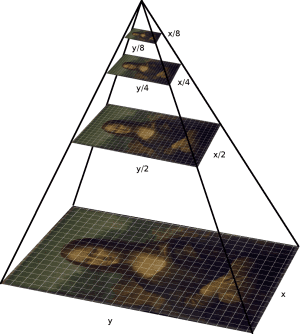
At each layer of the image pyramid the image is downsized and (optionally) smoothed via a Gaussian filter.
This scale parameter controls the factor in which our image is resized at each layer of the image pyramid, ultimately influencing the number of levels in the image pyramid.
A smaller scale will increase the number of layers in the image pyramid and increase the amount of time it takes to process your image:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.01
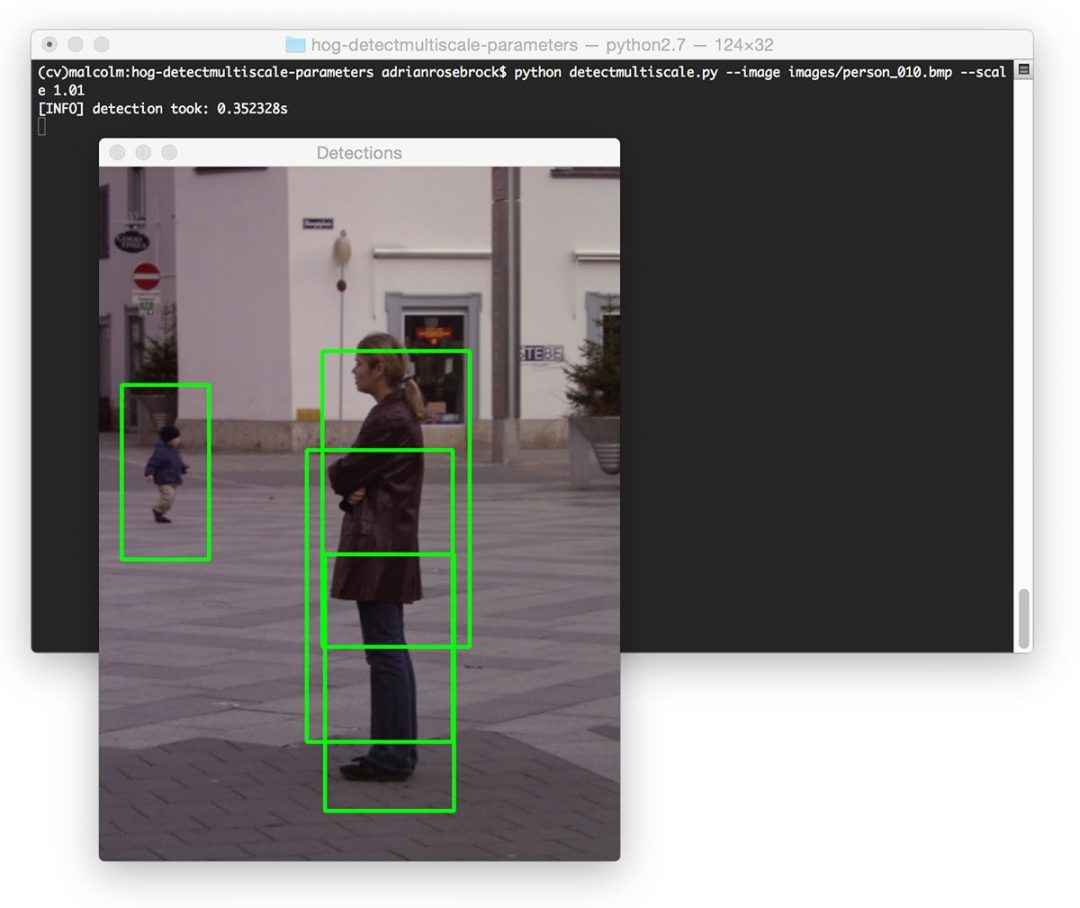
The amount of time it takes to process our image has significantly jumped to 0.3s. We also now have an issue of overlapping bounding boxes. However, that issue can be easily remedied using non-maxima suppression.
Meanwhile a larger scale will decrease the number of layers in the pyramid as well as decrease the amount of time it takes to detect objects in an image:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.5
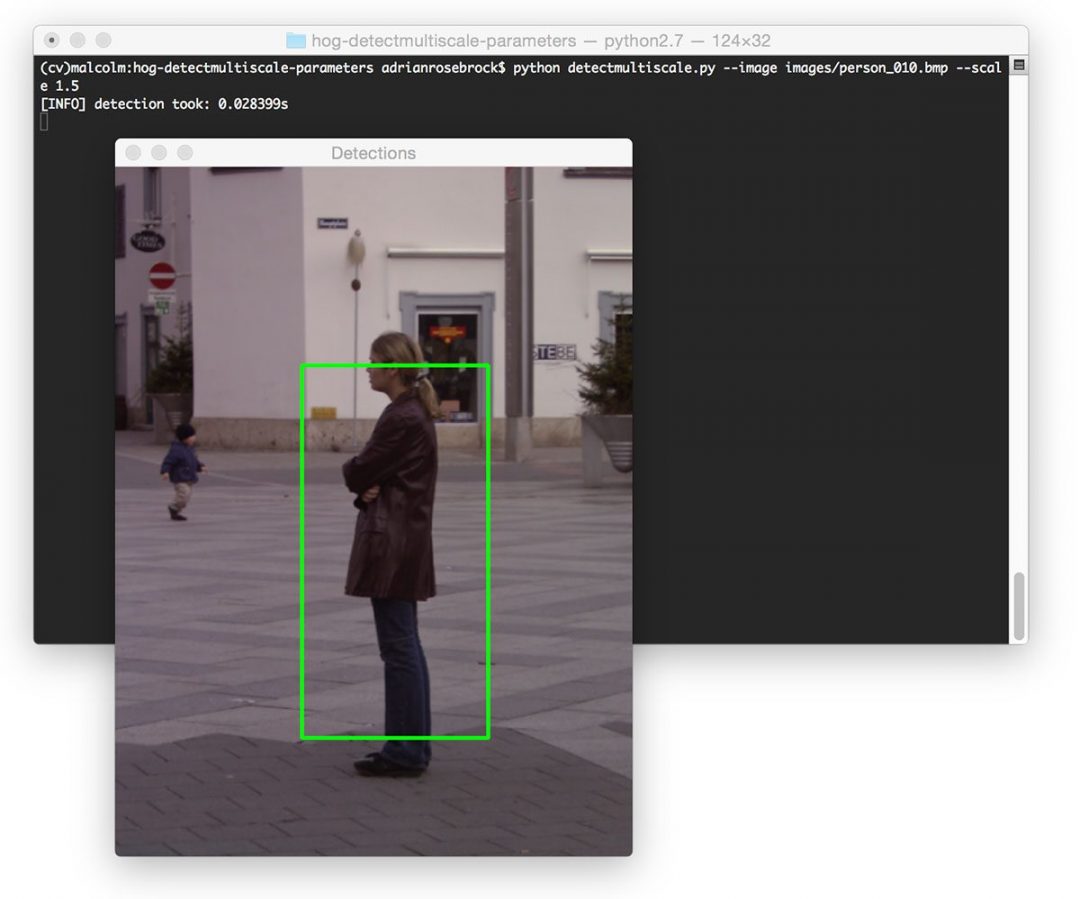
Here we can see that we performed pedestrian detection in only 0.02s, implying that we can process nearly 50 images per second. However, this comes at the expense of missing some detections, as evidenced by the figure above.
Finally, if you decrease both winStride and scale at the same time, you’ll dramatically increase the amount of time it takes to perform object detection:
$ python detectmultiscale.py --image images/person_010.bmp --scale 1.03 \ --win-stride="(4, 4)"
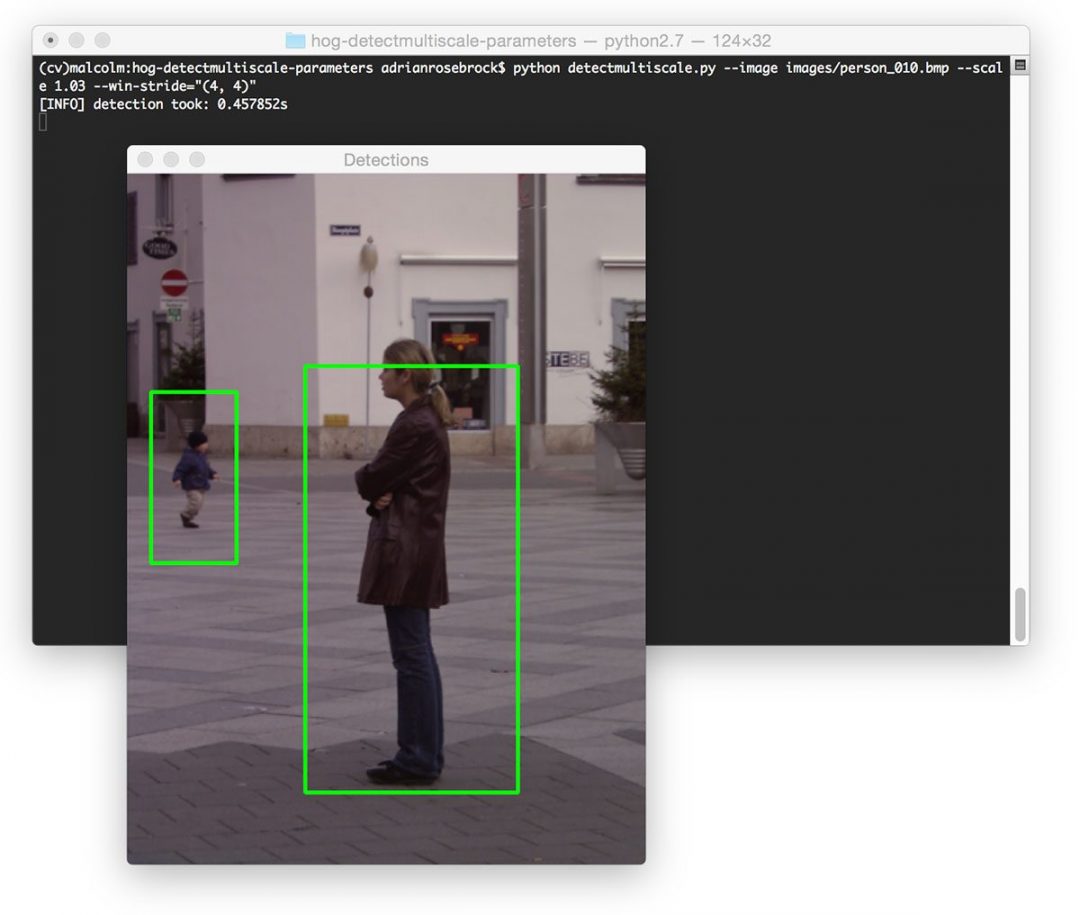
We are able to detect both people in the image — but it’s taken almost half a second to perform this detection, which is absolutely not suitable for real-time applications.
Keep in mind that for each layer of the pyramid a sliding window with winStride steps is moved across the entire layer. While it’s important to evaluate multiple layers of the image pyramid, allowing us to find objects in our image at different scales, it also adds a significant computational burden since each layer also implies a series of sliding windows, HOG feature extractions, and decisions by our SVM must be performed.
Typical values for scale are normally in the range [1.01, 1.5]. If you intend on running detectMultiScale in real-time, this value should be as large as possible without significantly sacrificing detection accuracy.
Again, along with the winStride , the scale is the most important parameter for you to tune in terms of detection speed.
finalThreshold (optional)
I honestly can’t even find finalThreshold inside the OpenCV documentation (specifically for the Python bindings) and I have no idea what it does. I assume it has some relation to the hitThreshold , allowing us to apply a “final threshold” to the potential hits, weeding out potential false-positives, but again, that’s simply speculation based on the argument name.
If anyone knows what this parameter controls, please leave a comment at the bottom of this post.
useMeanShiftGrouping (optional)
The useMeanShiftGrouping parameter is a boolean indicating whether or not mean-shift grouping should be performed to handle potential overlapping bounding boxes. This value defaults to False and in my opinion, should never be set to True — use non-maxima suppression instead; you’ll get much better results.
When using HOG + Linear SVM object detectors you will undoubtably run into the issue of multiple, overlapping bounding boxes where the detector has fired numerous times in regions surrounding the object we are trying to detect:
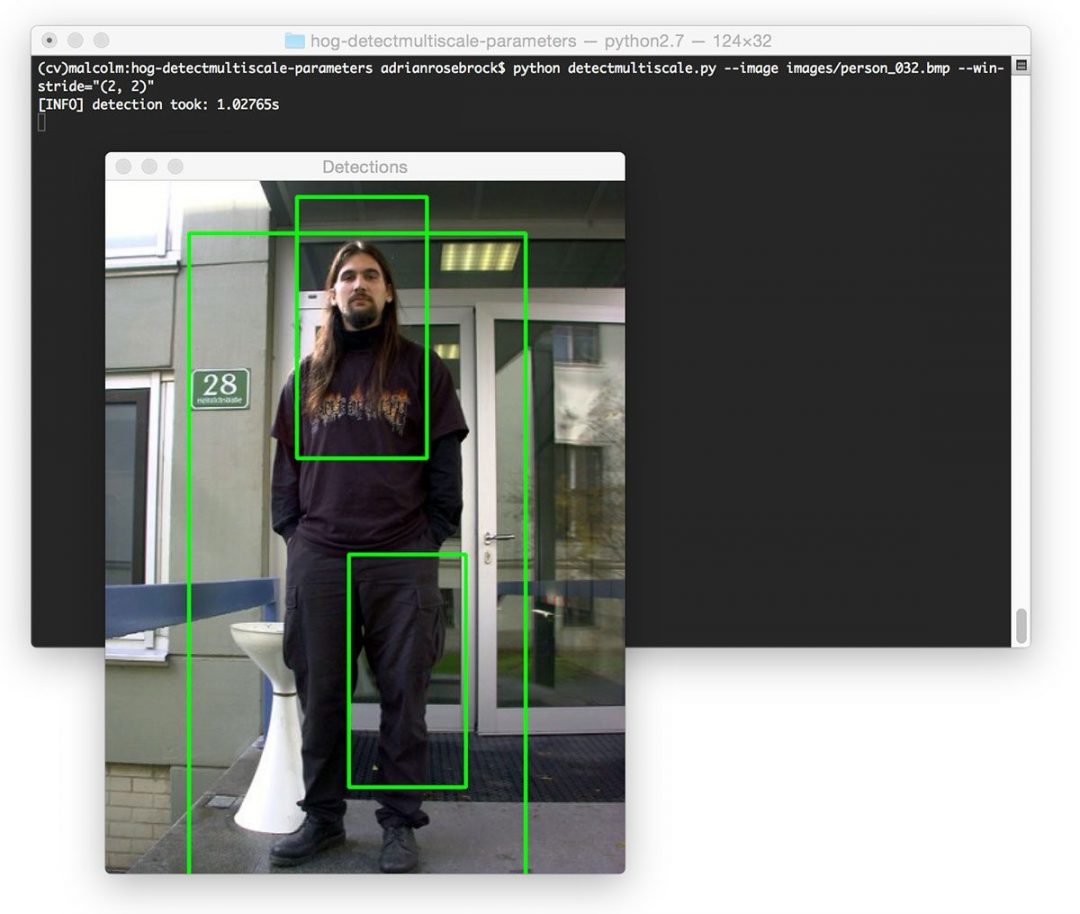
To suppress these multiple bounding boxes, Dalal suggested using mean shift (Slide 18). However, in my experience mean shift performs sub-optimally and should not be used as a method of bounding box suppression, as evidenced by the image below:
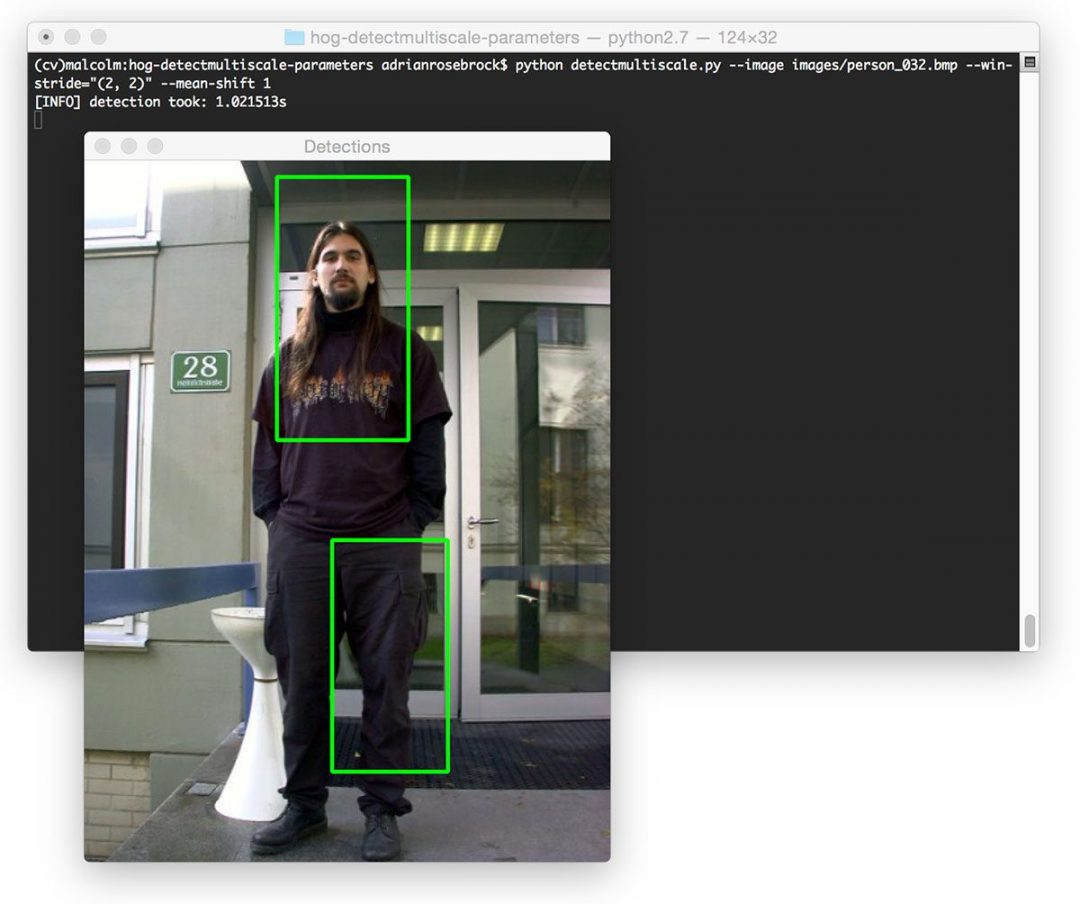
Instead, utilize non-maxima suppression (NMS). Not only is NMS faster, but it obtains much more accurate final detections:

Tips on speeding up the object detection process
Whether you’re batch processing a dataset of images or looking to get your HOG detector to run in real-time (or as close to real-time as feasible), these three tips should help you milk as much performance out of your detector as possible:
- Resize your image or frame to be as small as possible without sacrificing detection accuracy. Prior to calling the
detectMultiScalefunction, reduce the width and height of your image. The smaller your image is, the less data there is to process, and thus the detector will run faster. - Tune your
scaleandwinStrideparameters. These two arguments have a tremendous impact on your object detector speed. BothscaleandwinStrideshould be as large as possible, again, without sacrificing detector accuracy. - If your detector still is not fast enough…you might want to look into re-implementing your program in C/C++. Python is great and you can do a lot with it. But sometimes you need the compiled binary speed of C or C++ — this is especially true for resource constrained environments.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson we reviewed the parameters to the detectMultiScale function of the HOG descriptor and SVM detector. Specifically, we examined these parameter values in context of pedestrian detection. We also discussed the speed and accuracy tradeoffs you must consider when utilizing HOG detectors.
If your goal is to apply HOG + Linear SVM in (near) real-time applications, you’ll first want to start by resizing your image to be as small as possible without sacrificing detection accuracy: the smaller the image is, the less data there is to process. You can always keep track of your resizing factor and multiply the returned bounding boxes by this factor to obtain the bounding box sizes in relation to the original image size.
Secondly, be sure to play with your scale and winStride parameters. This values can dramatically affect the detection accuracy (as well as false-positive rate) of your detector.
Finally, if you still are not obtaining your desired frames per second (assuming you are working on a real-time application), you might want to consider re-implementing your program in C/C++. While Python is very fast (all things considered), there are times you cannot beat the speed of a binary executable.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

