
In today’s blog post, we are going to implement our first Convolutional Neural Network (CNN) — LeNet — using Python and the Keras deep learning package.
The LeNet architecture was first introduced by LeCun et al. in their 1998 paper, Gradient-Based Learning Applied to Document Recognition. As the name of the paper suggests, the authors’ implementation of LeNet was used primarily for OCR and character recognition in documents.
The LeNet architecture is straightforward and small, (in terms of memory footprint), making it perfect for teaching the basics of CNNs — it can even run on the CPU (if your system does not have a suitable GPU), making it a great “first CNN”.
However, if you do have GPU support and can access your GPU via Keras, you will enjoy extremely fast training times (in the order of 3-10 seconds per epoch, depending on your GPU).
In the remainder of this post, I’ll be demonstrating how to implement the LeNet Convolutional Neural Network architecture using Python and Keras.
From there, I’ll show you how to train LeNet on the MNIST dataset for digit recognition.
To learn how to train your first Convolutional Neural Network, keep reading.
LeNet – Convolutional Neural Network in Python
This tutorial will be primarily code oriented and meant to help you get your feet wet with Deep Learning and Convolutional Neural Networks. Because of this intention, I am not going to spend a lot of time discussing activation functions, pooling layers, or dense/fully-connected layers — there will be plenty of tutorials on the PyImageSearch blog in the future that will cover each of these layer types/concepts in lots of detail.
Again, this tutorial is meant to be your first end-to-end example where you get to train a real-life CNN (and see it in action). We’ll get to the gory details of activation functions, pooling layers, and fully-connected layers later in this series of posts (although you should already know the basics of how convolution operations work); but in the meantime, simply follow along, enjoy the lesson, and learn how to implement your first Convolutional Neural Network with Python and Keras.
The MNIST dataset

You’ve likely already seen the MNIST dataset before, either here on the PyImageSearch blog, or elsewhere in your studies. In either case, I’ll go ahead and quickly review the dataset to ensure you know exactly what data we’re working with.
The MNIST dataset is arguably the most well-studied, most understood dataset in the computer vision and machine learning literature, making it an excellent “first dataset” to use on your deep learning journey.
Note: As we’ll find out, it’s also quite easy to get > 98% classification accuracy on this dataset with minimal training time, even on the CPU.
The goal of this dataset is to classify the handwritten digits 0-9. We’re given a total of 70,000 images, with (normally) 60,000 images used for training and 10,000 used for evaluation; however, we’re free to split this data as we see fit. Common splits include the standard 60,000/10,000, 75%/25%, and 66.6%/33.3%. I’ll be using 2/3 of the data for training and 1/3 of the data for testing later in the blog post.
Each digit is represented as a 28 x 28 grayscale image (examples from the MNIST dataset can be seen in the figure above). These grayscale pixel intensities are unsigned integers, with the values of the pixels falling in the range [0, 255]. All digits are placed on a black background with a light foreground (i.e., the digit itself) being white and various shades of gray.
It’s worth noting that many libraries (such as scikit-learn) have built-in helper methods to download the MNIST dataset, cache it locally to disk, and then load it. These helper methods normally represent each image as a 784-d vector.
Where does the number 784 come from?
Simple. It’s just the flattened 28 x 28 = 784 image.
To recover our original image from the 784-d vector, we simply reshape the array into a 28 x 28 image.
In the context of this blog post, our goal is to train LeNet such that we maximize accuracy on our testing set.
The LeNet architecture
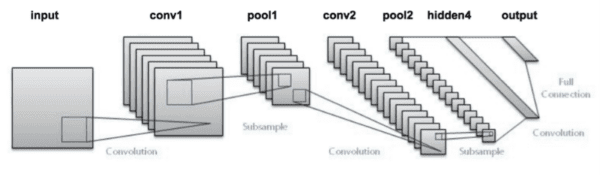
The LeNet architecture is an excellent “first architecture” for Convolutional Neural Networks (especially when trained on the MNIST dataset, an image dataset for handwritten digit recognition).
LeNet is small and easy to understand — yet large enough to provide interesting results. Furthermore, the combination of LeNet + MNIST is able to run on the CPU, making it easy for beginners to take their first step in Deep Learning and Convolutional Neural Networks.
In many ways, LeNet + MNIST is the “Hello, World” equivalent of Deep Learning for image classification.
The LeNet architecture consists of the following layers:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC => RELU => FC
Instead of explaining the number of convolution filters per layer, the size of the filters themselves, and the number of fully-connected nodes right now, I’m going to save this discussion until our “Implementing LeNet with Python and Keras” section of the blog post where the source code will serve as an aid in the explantation.
In the meantime, let’s took at our project structure — a structure that we are going to reuse many times in future PyImageSearch blog posts.
Note: The original LeNet architecture used TANH activation functions rather than RELU . The reason we use RELU here is because it tends to give much better classification accuracy due to a number of nice, desirable properties (which I’ll discuss in a future blog post). If you run into any other discussions on LeNet, you might see that they use TANH instead — again, just something to keep in mind.
Our CNN project structure
Before we dive into any code, let’s first review our project structure:
|--- output |--- pyimagesearch | |--- __init__.py | |--- cnn | | |--- __init__.py | | |--- networks | | | |--- __init__.py | | | |--- lenet.py |--- lenet_mnist.py
To keep our code organized, we’ll define a package named pyimagesearch . And within the pyimagesearch module, we’ll create a cnn sub-module — this is where we’ll store our Convolutional Neural Network implementations, along with any helper utilities related to CNNs.
Taking a look inside cnn , you’ll see the networks sub-module: this is where the network implementations themselves will be stored. As the name suggests, the lenet.py file will define a class named LeNet , which is our actual LeNet implementation in Python + Keras.
The lenet_mnist.py script will be our driver program used to instantiate the LeNet network architecture, train the model (or load the model, if our network is pre-trained), and then evaluate the network performance on the MNIST dataset.
Finally, the output directory will store our LeNet model after it has been trained, allowing us to classify digits in subsequent calls to lenet_mnist.py without having to re-train the network.
I personally have been using this project structure (or a project structure very similar to it) over the past year. I’ve found it well organized and easy to extend — this will become more evident in future blog posts as we add to this library with more network architectures and helper functions.
Implementing LeNet with Python and Keras
To start, I am going to assume that you already have Keras, scikit-learn, and OpenCV installed on your system (and optionally, have GPU-support enabled). If you do not, please refer to this blog post to help you get your system configured properly.
Otherwise, open up the lenet.py file and insert the following code:
# import the necessary packages from keras.models import Sequential from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.layers.core import Activation from keras.layers.core import Flatten from keras.layers.core import Dense from keras import backend as K class LeNet: @staticmethod def build(numChannels, imgRows, imgCols, numClasses, activation="relu", weightsPath=None): # initialize the model model = Sequential() inputShape = (imgRows, imgCols, numChannels) # if we are using "channels first", update the input shape if K.image_data_format() == "channels_first": inputShape = (numChannels, imgRows, imgCols)
Lines 2-8 handle importing the required functions/classes from the keras library.
The LeNet class is defined on Line 10, followed by the build method on Line 12. Whenever I define a new network architecture, I always place it in its own class (mainly for namespace and organization purposes) — followed by creating a static build function.
The build method, as the name suggests, takes any supplied parameters, which at a bare minimum include:
- The width of our input images.
- The height of our input images.
- The depth (i.e., number of channels) of our input images.
- And the number of classes (i.e., unique number of class labels) in our dataset.
I also normally include a weightsPath which can be used to load a pre-trained model. Given these parameters, the build function is responsible for constructing the network architecture.
Speaking of building the LeNet architecture, Line 15 instantiates a Sequential class which we’ll use to construct the network.
Then, we handle whether we’re working with “channels last” or “channels first” tensors on Lines 16-20. Tensorflow’s default is “channels last”.
Now that the model has been initialized, we can start adding layers to it:
# define the first set of CONV => ACTIVATION => POOL layers model.add(Conv2D(20, 5, padding="same", input_shape=inputShape)) model.add(Activation(activation)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
On Lines 23-26 we create our first set of CONV => RELU => POOL layer sets.
Our CONV layer will learn 20 convolution filters, where each filter is of size 5 x 5. The input dimensions of this value are the same width, height, and depth as our input images — in this case, the MNIST dataset, so we’ll have 28 x 28 inputs with a single channel for depth (grayscale).
We’ll then apply the ReLU activation function followed by 2 x 2 max-pooling in both the x and y direction with a stride of 2 (imagine a 2 x 2 sliding window that “slides” across the activation volume, taking the max operation of each region, while taking a step of 2 pixels in both the horizontal and vertical direction).
Note: This tutorial is primarily code based and is meant to be your first exposure to implementing a Convolutional Neural Network — I’ll be going into lots more detail regarding convolutional layers, activation functions, and max-pooling layers in future blog posts. In the meantime, simply try to follow along with the code.
We are now ready to apply our second set of CONV => RELU => POOL layers:
# define the second set of CONV => ACTIVATION => POOL layers model.add(Conv2D(50, 5, padding="same")) model.add(Activation(activation)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
This time we’ll be learning 50 convolutional filters rather than the 20 convolutional filters as in the previous layer set.
It’s common to see the number of CONV filters learned increase in deeper layers of the network.
Next, we come to the fully-connected layers (often called “dense” layers) of the LeNet architecture:
# define the first FC => ACTIVATION layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation(activation))
# define the second FC layer
model.add(Dense(numClasses))
# lastly, define the soft-max classifier
model.add(Activation("softmax"))
On Line 34 we take the output of the preceding MaxPooling2D layer and flatten it into a single vector, allowing us to apply dense/fully-connected layers. If you have any prior experience with neural networks, then you’ll know that a dense/fully-connected layer is a “standard” type of layer in a network, where every node in the preceding layer connects to every node in the next layer (hence the term, “fully-connected”).
Our fully-connected layer will contain 500 units (Line 35) which we pass through another nonlinear ReLU activation.
Line 39 is very important, although it’s easy to overlook — this line defines another Dense class, but accepts a variable (i.e., not hardcoded) size. This size is the number of class labels represented by the classes variable. In the case of the MNIST dataset, we have 10 classes (one for each of the ten digits we are trying to learn to recognize).
Finally, we apply a softmax classifier (multinomial logistic regression) that will return a list of probabilities, one for each of the 10 class labels (Line 42). The class label with the largest probability will be chosen as the final classification from the network.
Our last code block handles loading a pre-existing weightsPath (if such a file exists) and returning the constructed model to the calling function:
# if a weights path is supplied (inicating that the model was # pre-trained), then load the weights if weightsPath is not None: model.load_weights(weightsPath) # return the constructed network architecture return model
Creating the LeNet driver script
Now that we have implemented the LeNet Convolutional Neural Network architecture using Python + Keras, it’s time to define the lenet_mnist.py driver script which will handle:
- Loading the MNIST dataset.
- Partitioning MNIST into training and testing splits.
- Loading and compiling the LeNet architecture.
- Training the network.
- Optionally saving the serialized network weights to disk so that it can be reused (without having to re-train the network).
- Displaying visual examples of the network output to demonstrate that our implementaiton is indeed working properly.
Open up your lenet_mnist.py file and insert the following code:
# import the necessary packages
from pyimagesearch.cnn.networks.lenet import LeNet
from sklearn.model_selection import train_test_split
from keras.datasets import mnist
from keras.optimizers import SGD
from keras.utils import np_utils
from keras import backend as K
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--save-model", type=int, default=-1,
help="(optional) whether or not model should be saved to disk")
ap.add_argument("-l", "--load-model", type=int, default=-1,
help="(optional) whether or not pre-trained model should be loaded")
ap.add_argument("-w", "--weights", type=str,
help="(optional) path to weights file")
args = vars(ap.parse_args())
Lines 2-10 handle importing our required Python packages. Notice how we’re importing our LeNet class from the networks sub-module of cnn and pyimagesearch .
Note: If you’re following along with this blog post and intend on executing the code, please use the “Downloads” section at the bottom of this post. In order to keep this post shorter and concise, I’ve left out the __init__.py updates which might throw off newer Python developers.
From there, Lines 13-20 parse three optional command line arguments, each of which are detailed below:
--save-model: An indicator variable, used to specify whether or not we should save our model to disk after training LeNet.--load-model: Another indicator variable, this time specifying whether or not we should load a pre-trained model from disk.--weights: In the case that--save-modelis supplied, the--weights-pathshould point to where we want to save the serialized model. And in the case that--load-modelis supplied, the--weightsshould point to where the pre-existing weights file lives on our system.
We are now ready to load the MNIST dataset and partition it into our training and testing splits:
# grab the MNIST dataset (if this is your first time running this
# script, the download may take a minute -- the 55MB MNIST dataset
# will be downloaded)
print("[INFO] downloading MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# if we are using "channels first" ordering, then reshape the
# design matrix such that the matrix is:
# num_samples x depth x rows x columns
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# otherwise, we are using "channels last" ordering, so the design
# matrix shape should be: num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
Line 26 loads the MNIST dataset from disk. If this is your first time calling the fetch_mldata function with the "MNIST Original" string, then the MNIST dataset will need to be downloaded. The MNIST dataset is a 55MB file, so depending on your internet connection, this download may take anywhere from a couple seconds to a few minutes.
Lines 31-39 handle reshaping data for either “channels first” or “channels last” implementation. For example, TensorFlow supports “channels last” ordering.
Finally, Lines 42-43 perform a training and testing split, using 2/3 of the data for training and the remaining 1/3 for testing. We also reduce our images from the range [0, 255] to [0, 1.0], a common scaling technique.
The next step is to process our labels so they can be used with the categorical cross-entropy loss function:
# transform the training and testing labels into vectors in the
# range [0, classes] -- this generates a vector for each label,
# where the index of the label is set to `1` and all other entries
# to `0`; in the case of MNIST, there are 10 class labels
trainLabels = np_utils.to_categorical(trainLabels, 10)
testLabels = np_utils.to_categorical(testLabels, 10)
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(numChannels=1, imgRows=28, imgCols=28,
numClasses=10,
weightsPath=args["weights"] if args["load_model"] > 0 else None)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
Lines 49 and 50 handle processing our training and testing labels (i.e., the “ground-truth” labels of each image in the MNIST dataset).
Since we are using the categorical cross-entropy loss function, we need to apply the to_categorical function which converts our labels from integers to a vector, where each vector ranges from [0, classes] . This function generates a vector for each class label, where the index of the correct label is set to 1 and all other entries are set to 0.
In the case of the MNIST dataset, we have 10 lass labels, therefore each label is now represented as a 10-d vector. As an example, consider the training label “3”. After applying the to_categorical function, our vector would now look like:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
Notice how all entries in the vector are zero except for the third index which is now set to one.
We’ll be training our network using Stochastic Gradient Descent (SGD) with a learning rate of 0.01 (Line 54). Categorical cross-entropy will be used as our loss function, a fairly standard choice when working with datasets that have more than two class labels. Our model is then compiled and loaded into memory on Lines 55-59.
We are now ready to build our LeNet architecture, optionally load any pre-trained weights from disk, and then train our network:
# only train and evaluate the model if we *are not* loading a
# pre-existing model
if args["load_model"] < 0:
print("[INFO] training...")
model.fit(trainData, trainLabels, batch_size=128, epochs=20,
verbose=1)
# show the accuracy on the testing set
print("[INFO] evaluating...")
(loss, accuracy) = model.evaluate(testData, testLabels,
batch_size=128, verbose=1)
print("[INFO] accuracy: {:.2f}%".format(accuracy * 100))
In the case that --load-model is not supplied, we need to train our network (Line 63).
Training our network is accomplished by making a call to the .fit method of the instantiated model (Lines 65 and 66). We’ll allow our network to train for 20 epochs (indicating that our network will “see” each of the training examples a total of 20 times to learn distinguishing filters for each digit class).
We then evaluate our network on the testing data (Lines 70-72) and display the results to our terminal.
Next, we make a check to see if we should serialize the network weights to file, allowing us to run the lenet_mnist.py script subsequent times without having to re-train the network from scratch:
# check to see if the model should be saved to file
if args["save_model"] > 0:
print("[INFO] dumping weights to file...")
model.save_weights(args["weights"], overwrite=True)
Our last code block handles randomly selecting a few digits from our testing set and then passing them through our trained LeNet network for classification:
# randomly select a few testing digits
for i in np.random.choice(np.arange(0, len(testLabels)), size=(10,)):
# classify the digit
probs = model.predict(testData[np.newaxis, i])
prediction = probs.argmax(axis=1)
# extract the image from the testData if using "channels_first"
# ordering
if K.image_data_format() == "channels_first":
image = (testData[i][0] * 255).astype("uint8")
# otherwise we are using "channels_last" ordering
else:
image = (testData[i] * 255).astype("uint8")
# merge the channels into one image
image = cv2.merge([image] * 3)
# resize the image from a 28 x 28 image to a 96 x 96 image so we
# can better see it
image = cv2.resize(image, (96, 96), interpolation=cv2.INTER_LINEAR)
# show the image and prediction
cv2.putText(image, str(prediction[0]), (5, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
print("[INFO] Predicted: {}, Actual: {}".format(prediction[0],
np.argmax(testLabels[i])))
cv2.imshow("Digit", image)
cv2.waitKey(0)
For each of the randomly selected digits, we classify the image using our LeNet model (Line 82).
The actual prediction of our network is obtained by finding the index of the class label with the largest probability. Remember, our network will return a set of probabilities via the softmax function, one for each class label — the actual “prediction” of the network is therefore the class label with the largest probability.
Lines 87-103 handle resizing the 28 x 28 image to 96 x 96 pixels so we can better visualize it, followed by drawing the prediction on the image .
Finally, Lines 104-107 display the result to our screen.
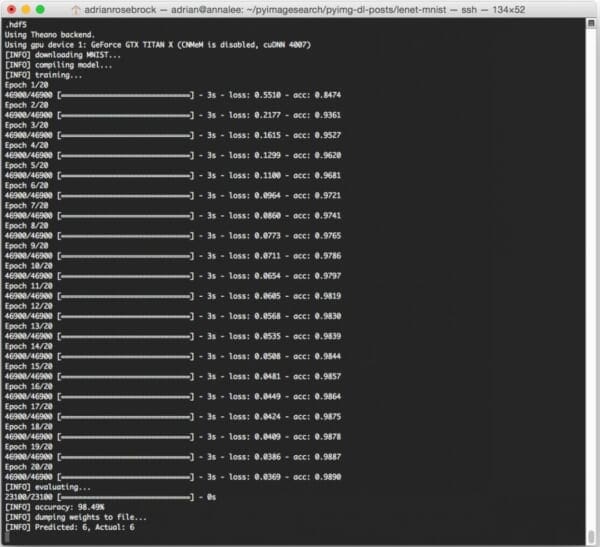
Training LeNet with Python and Keras
To train LeNet on the MNIST dataset, make sure you have downloaded the source code using the “Downloads” form found at the bottom of this tutorial. This .zip file contains all the code I have detailed in this tutorial — furthermore, this code is organized in the same project structure that I detailed above, which ensures it will run properly on your system (provided you have your environment configured properly).
After downloading the .zip code archive, you can train LeNet on MNIST by executing the following command:
$ python lenet_mnist.py --save-model 1 --weights output/lenet_weights.hdf5
I’ve included the output from my machine below:
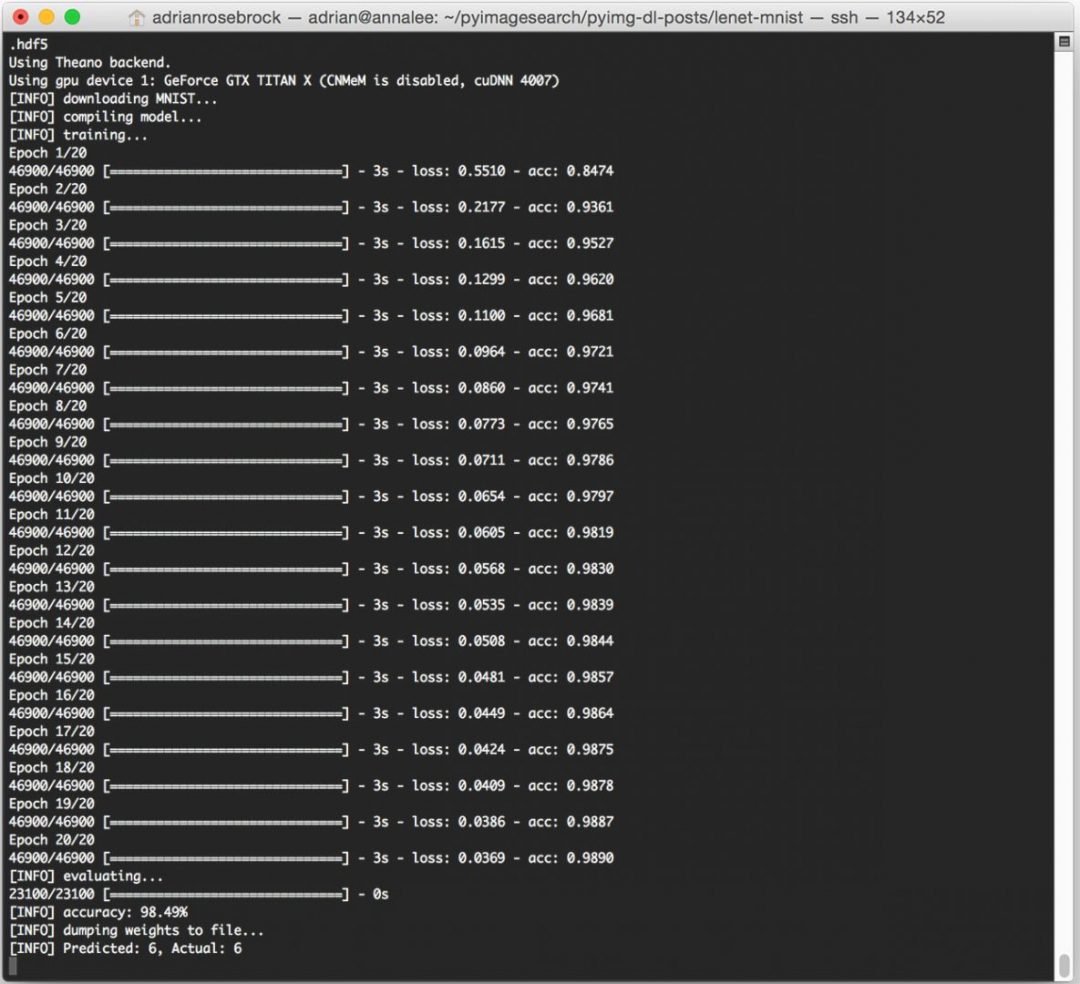
On my Titan X GPU, it takes approximately 3 seconds per epoch, allowing the entire training process to finish in approximately 60 seconds.
After only 20 epochs, LeNet is reaching 98.49% classification accuracy on the MNIST dataset — not bad at all for only 60 seconds of computation time!
Note: If you execute the lenet_mnist.py script on our CPU rather than GPU, expect the per-epoch time to jump to 70-90 seconds. It’s still possible to train LeNet on your CPU, it will just take a little while longer.
Evaluating LeNet with Python and Keras
Below I have included a few example evaluation images from our LeNet + MNIST implementation:
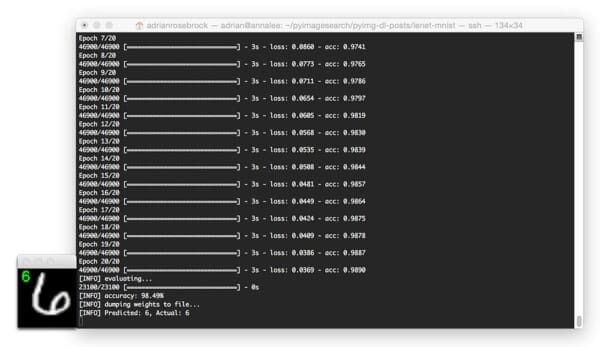
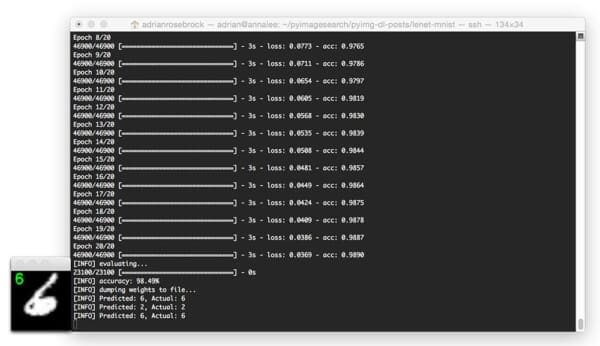
In the above image, we are able to correctly classify the digit as “6”.
And in this image, LeNet correctly recognizes the digit as a “2”:

The image below is a great example of the robust, discriminating nature of convolution filters learned by CNN filters: This “6” is quite contorted, leaving little-to-no gap between the circular region of the digit, but LeNet is still able to correctly classify the digit:
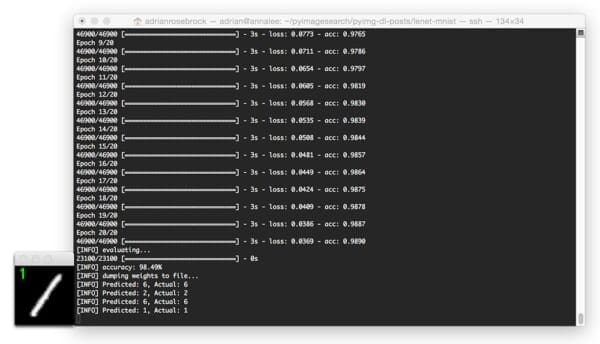
Here is another image, this time classifying a heavily skewed “1”:
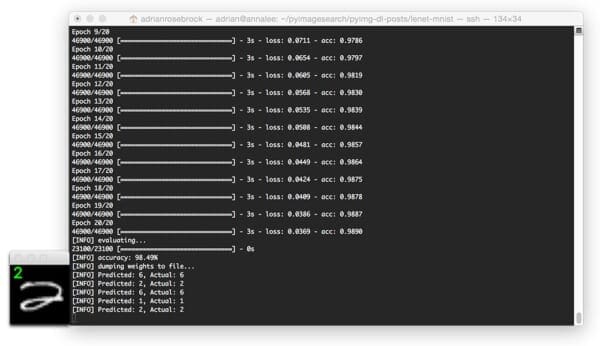
Finally, this last example demonstrates the LeNet model classifying a “2”:
Running the serialized LeNet model
After our lenet_mnist.py script finishes executing the first time (provided you supplied both --save-model and --weights ), you should now have a lenet_weights.hdf5 file in your output directory.
Instead of re-training our network on subsequent runs of lenet_mnist.py , we can instead load these weights and use them to classify digits.
To load our pre-trained LeNet model, just execute the following command:
$ python lenet_mnist.py --load-model 1 --weights output/lenet_weights.hdf5
I’ve included a GIF animation of LeNet used to correctly classify handwritten digits below:

What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post, I demonstrated how to implement the LeNet architecture using the Python programming language and the Keras library for deep learning.
The LeNet architecture is a great “Hello, World” network to get your feet wet with deep learning and Convolutional Neural Networks. The network itself is simple, has a small memory footprint, and when applied to the MNIST dataset, can be run on either your CPU or GPU, making it ideal for experimenting and learning, especially if you’re a deep learning newcomer.
This tutorial was primarily code focused, and because of this, I needed to skip over detailed reviews of important Convolutional Neural Network concepts such as activation layers, pooling layers, and dense/fully-connected layers (otherwise this post could have easily been 5x as long).
In future blog posts, I’ll be reviewing each of these layer types in lots of detail — in the meantime, simply familiarize yourself with the code and try executing it yourself. And if you’re feeling really daring, try tweaking the number of filters and filter sizes per convolutional layer and see what happens!
Anyway, I hope you’ve enjoyed this blog post — I’ll certainly be doing more deep learning and image classification posts in the future.
But before you go, be sure to enter your email address in the form below to be notified when future PyImageSearch blog posts are published — you won’t want to miss them!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Incredible! Thank you so much. After learning from your very clear examples, I trained LeNet on over a hundred thousand sample images of over 2700 Japanese Kanji with over 99% predictive accuracy on the over thirty thousand test data images. Thank you again!
Congrats Keith, that’s awesome! 😀
Can i use LeNet 5 architecture for more than thousand Classes?
You can try but realistically it’s not going to work well unless your data is incredibly simplistic.
OK, I have a question about locating the classified objects in a large image. Let’s say we do have multiple objects that mighty be classified as ‘A’ and ‘B’ in the same image.
How can I locate the classified object and draw a rectangle around it? Do I have to use sliding windows like HoG does?
There are many different ways to perform object localization using deep learning. Yes, you could apply a sliding window like HOG does. However, this is very slow. Instead, you might be interested in RCNNs and Faster R-CNNs where the goal is to integrate both object classification and localization into the same framework. Personally, I really like the You Only Look Once approach to object detection.
Oh, thanks so much and I need this right now!
Hi Adrian!
Awesome article! How many images are required to train a CNN?
Cheers
That really depends entirely on your dataset and your application. In general, I would recommend 500-1,000 images per class (the more the better) to train an CNN from start to finish. The more classes you have, the more images you’ll want per class as well. You can get away with less images by using a pre-trained CNN for feature extraction or applying data augmentation + fine-tuning. For what it’s worth, I cover Deep Learning + CNNs in more detail inside the PyImageSearch Gurus course.
hello i want to learn how to build lenet from scratch can you help me in building that model?
This exact tutorial teaches you how to:
1. Implement LeNet from scratch in Keras
2. Train LeNet from scratch
Perhaps I’m not understanding your question?
Hey Adrian, great post! I tested out the program on my desktop, and it worked amazingly. Do you think that a raspberry pi 2 would be capable of handling this program, and similar deep learning modules as well?
Since LeNet does not require much memory, this would work fine on the Pi. However, for larger network architectures such as GoogLeNet, VGG, ResNet, etc., the Pi won’t have enough memory to run state-of-the-art networks. But for small, simple networks, you can use the Pi — just keep in mind it won’t be super fast. You should also train your networks on on a faster GPU machine and then deploy only the network weights for classification to your Pi.
Adrian: The fun level is high! I really like your teaching technique of first showing us how to make something new and interesting that works decently, right away, with just the skeleton of the ideas. You then later follow up with additional theoretical explanations and variations so that something even better can be made if we want it. Detail, justification, expansion, alternatives etc, these all just make more sense later after some practical context — a fun, working program — is already established.
Thanks Geoffrey, I appreciate that!
Suggestions to all. Of course not everything is presented in a concise project description. That’s what concise is of course. That said, a major idea or two for nascent machine learning developers:
This code by Adrian (thank you Adrian!) does no evaluation using training data, i.e., the evaluate function call. But if you do add it, I promise that you will get additional crucial information to allow you to more smartly debug the model better. Because if you do it, you can then be able to know if bias is the reason for low accuracy, versus variance being the issue for low accuracy.
Suggest all you modelers should first develop a model which attains low bias on training set, ie, which you trained model on. Please ignore these non-training-data predictions (you called it “test” data, Adrian) at first, because you must get your model to a sufficiently high capacity and complexity at first using the training data, e.g., more units, more layers, more and better features — a more flexible model is needed.
Go and go until your accuracy of prediction is as good as you can get it on training predictions. Did you get low error finally? Did you find greater capacity by adding more and better features and model capacity like layers and units? That’s great and necessary — but you are not done yet.
So now you finally get low bias on training dataset predictions. Now you are ready to begin evaluating the accuracy of predictions on a dataset you did not train on, call it “V” dataset (you called it “test” but it’s a misnomer so I won’t call it “test”). Your model has a low bias as you already determined. Check its predictions on “V” dataset. If your accuracy with this model is too low on “V” then you have a variance problem. Or no variance problem and you are done! great job! bias and variance are both low. But if not so lucky, then you need a more data examples, or more rigid model, or more regularization like noise injection, L1 reg, L2 reg, dropout, etc. Do not waste your time tuning all the hyperparameters or adding more units, more layers, more features, as these are addressing bias and capacity, not variance at all. You need to distinguish the options, and correctly use those, which affect model capacity versus those which affect model variance. You could waste 3-6 months of your life getting more data and adding more layers and running computer time, when all along it was the bias not the variance the whole time, so you need to know which is happening.
Bottom line is a model developer must be smart and know what improvements to try next to get a high accuracy model on new data. The way to get it is for the training data set to be also used for predictions.
Second major point is the code above did not give a truly new dataset error estimate, on a proper test dataset, ie, that which is new to you and to your model, after you did the recommended tweaks and improvements to it. To predict what your final model’s error will be, as best you can (still imperfect tho) you need the new data set partition where nothing was ever used during the above bias and variance work. You really need this third as-yet-unseen data partition to get something closer to a realistic error assessment. You really must not use the “V” dataset nor the training dataset for final error estimation, as these both will be already baked into your final model.
It proves to be super challenging and nuanced for students and even practitioners, and I am not the best teacher admittedly. I hope all will take time to think hard and check into these things yourselves. It will save you time when building if it becomes clear to you.
Andrew Ng is the best I know to explain this particular thing, so please go watch Ng’s free videos on this topic of deciding what to do next in modeling with learning algorithms. Tibshirani also made a great free set of videos about it. You will save time and money by understanding bias improvement versus variance improvement, flexibil models and rigid models, as soon as you can.
Best to all!
Great insights, thanks Geoffrey!
Thanks for writing the mnist example program here. I noticed it loads the data in one line.
What if we had instead a couple of jpg files instead. How would we actually load them into keras to train on. Even just 3 or 4 jpg files so we can get the syntax would be very helpful. The web is replete with deep learning examples of loading mnist from a convenient single file. Or we see how to load weights that someone else made for us, again in just a one-liner of code. But loading a monolithic data file is rarely what we do in a realistic program which must train a new model we are making.
Adrian I’m hoping you (or I) find and share with each other, and with everyone, a working example of how to train a Keras model starting from the real first step: A bunch of jpg files on disk, rather than a singleton file that somehow contains a representation of lots of image files that someone else preprepared which is so convenient for toy programs. It’s been driving me batty. You might be the best person to show us how to get going here! You are the best! I love your teaching materials!
I’ll be doing more detailed, advanced tutorials that demonstrate how to build custom neural networks and deep learning models from scratch. However, in the meantime, just keep in mind that your training data is just a list of images. Therefore, just load your images into a single NumPy array and pass them through your network. It gets a little more complicated once all your images don’t fit into main memory, but again, that’s a topic for a separate blog post.
Hi Adrian, Thank you for your amazing tutorial.
However, I have a big issue. Training is so slow on my computer. I run it on CPU and each epoch takes almost 6000 seconds. I tested it both on windows 7 x64 (Anaconda) and Ubuntu x64 14.04 LTS. I expected your estimation of 70 seconds. Do you have any idea what is wrong?
Thank you
Here is my system’s spec:
-Intel Core i7-3770 3.4 GHz
-16 GB RAM
-64-bit
– Graphics: Intel HD (I am running on CPU)
6,000 seconds per epoch sounds extremely slow. In my experience, you should be seeing 120 seconds max per epoch on the CPU. I would look at your install and see if you forgot to install BLAS or LAPACK, common linear algebra optimization libraries. That is my best guess regarding the issue.
I have installed openblas on my ubuntu and now each epoch takes almost 120 seconds (I installed it on windows but it still not working, not a big deal as I have ubuntu working well).
Thank you so much.
No problem, I’m happy I could help! 🙂
I was curious about the digits which were classified incorrectly so I replaced your code that displays a few random results with a loop over all the test images and displayed the ones that were wrong. Some of the digits I couldn’t identify correctly either. The model seems to have big trouble with 3 vs 8 and 1 vs 7. Would more training with the digits 1, 3, 7 and 8 fix this?
More training data is almost always helpful. However, in this case I would instead use ensembles. I would train 3-5 separate LeNet models and then average the results. The accuracy will likely increase.
I installed a fresh Ubuntu 14.04 after I bought a Titan X. I was able to run your example on my previous Ubuntu (CPU). But now that I want to run it on my fresh Ubuntu, it generates an error:
“Exception: The shape of the input to “Flatten” is not fully defined (got (0, 7, 50). Make sure to pass a complete “input_shape” or “batch_input_shape” argument to the first layer in your model.”
I am totally confused as it was working well before.
That is quite strange, but it sounds like the error message is directly related to using your GPU. I presume the issue could be related to the Keras version. Which version of Keras are you utilizing? And did you use use this tutorial to install Keras?
I have got the exact same error.
Exception: The shape of the input to “Flatten” is not fully defined (got (0, 7, 50). Make sure to pass a complete “input_shape” or “batch_input_shape” argument to the first layer in your model.
I am using only CPU, on my MacBook Air (OS X Yosemite, 10.10.5).
My Keras version is ‘1.1.0’.
And yeah I did your previous tutorial to install keras.
Hm, I’m not sure what the exact reason for that error message is. Which backend for Keras are you using — TensorFlow or Theano?
EDIT: For what it’s worth, I just tried with Keras 1.1.0 on both my CPU and GPU. In both cases the script ran without error. This sounds like it’s a configuration problem on your machine(s).
Got the same error. The problem was, that i (once upon a time) installed tensorflow, and while keras was configured, the keras.json used the wrong image_dim_ordering.
Check your .keras/keras.json, and if “image_dim_ordering” is set to “tf”, just change it to “th”
Found the solution here: https://github.com/fchollet/keras/issues/3850
Great job resolving the issue Max! I’ve made note of this just in case any other readers have a similar issue.
Fixed the problem.
In ~/.keras/keras.json image_dim_ordering should be changed to “th” from “tf”.
Ah, I should have guessed that was the issue. Congrats on resolving the problem!
Thanks @Max Kostka – that was highly annoying.
thanks @Max Kostka, i had the same issue using windows 7, Keras and Theano
and thanks Adrian for putting together another great post.
I ended up with Keras 2.0 and my keras.json file had an extra line in it:
“image_data_format”: “channels_last”,
In order for your script to work, I had to change image_dim_ordering to th AND change the above line to:
“image_data_format”: “channels_first”,
Adrian – thanks for your work!!!
With the release of Keras 2.0 you can ignore
image_dim_orderingand simply setimage_data_format. I’ll be updating the Keras blog posts on PyImageSearch to represent this.Having this error :
ValueError: Filter must not be larger than the input: Filter: (5, 5) Input: (1, 28)
Please Help!!
Hey fubuki — can you confirm which backend you are using for Keras? Either TensorFlow or Theano?
hi Adrian,
got the same error with TensorFlow, any suggestion?
If you’re using TensorFlow then try setting your
backendto"tensorflow"and theimage_dim_orderingto"th"in~/.keras/keras.json.Found out the issues is caused by wrong settings in ~/.keras/keras.json
should change
“image_dim_ordering”: “th”,
to
“image_dim_ordering”: “tf”,
Sorry for bothering…
Grant
No worries Grant, this is a common issue. Depending on which backend you are using (Theano or TensorFlow) the
keras.jsonfile may need to be updated.Thank you so much for your great job Adrain!
The sample now runs like a charm!
I get 5s on training one set of Epoch on my platform,
system configuration:
Skylake i7-6700, 8G RAM, 500G HD, nVIDIA 950GTX,
Ubuntu 14.04 64bit
Congrats, nice work Grant!
Thanks A lot sir this was my first tutorials on your blog it surely gave a lot of confidence to learn more
Thanks Dhawal, I’m glad you enjoyed it 🙂
Hello,
We need an example how to load an image with an handwritten digit on it to predict with your code
I would suggest creating two Python scripts:
1. The first script trains your detector saves it to disk using the
.savemethod.2. Create a second Python script that actually loads the model + digit and classifies it.
I don’t have any ready-made code to do this with CNNs, but I do explain how to do it with HOG and Linear SVMs inside Practical Python and OpenCV.
Which requirements the digit-picture must have?
How to preprocess the picture that the model is able to predict the digit on it?
If you are using the LeNet architecture then each digit should be 28×28 pixels and single channel (grayscale). The most important aspect is pre-processing the digit. You would need to preserve the aspect ratio of the image and not resize the image to 28×28 pixels ignoring the aspect ratio. The
imutils.resizefunction will help you with this. You can then pad the image to be the final 28×28 pixels.This network also assumes that your digits are white on a black background. The same should be true for your digits as well.
Overall, MNIST is a very “clean” dataset and is used for machine learning benchmarks. It’s not exactly representative of what you will find in the real world. I’m not sure what dataset you are using on the types of images you are passing through the network but if you find your classification accuracy is not satisfactory, then you should consider training LeNet on your own example images.
Hi Adrian,
First thanks for your tutorial. I would like to know if you have worked with .mha image format before. I want to use a CNN on .mha images but I don’t know how to read this format on python.
Hey Keila — I have not worked with .mha files before, unfortunately. In order to work with them in the context of CNNs or OpenCV you will need to convert them to a NumPy array at some point. I would focus your research efforts on how to do that.
Can your CNN classify images for things such as hotels, bathrooms, etc?
The CNN demonstrated in this blog post was trained to recognize digits, but yes, you could also train it to recognize other objects provided you have enough images. I would instead suggest you take a look at pre-trained CNNs.
Great article. I made my first CNN (technically your) from this article. Keep up the good work!
Congrats on getting your first CNN up and running — that’s a huge step! Keep up the great progress.
I don’t understand why there is a `cv2.waitKey(0)` in the end. I also don’t know how to stop it except kill it(program paused at `cv2.waitKey(0)`).
The call to
cv2.waitKey(0)pauses the execution of the script so you can see the image displayed to your screen; otherwise,cv2.imshowwould automatically close. To stop the execution of the script, click on the image window and press any key.Hi Adrian,
Thank you for your article. Could you please help me to calculate the numbers of weights and outputs of each layer (Conv1, Conv2, dense1, dense2)?
I try to calculate the parameter as follow:
1. For Conv1:
– 20x5x5=500 weights (why the output file only has 20×5=100 weights)
– 20x24x24 =11250 outputs (pixels)?. 24×24 because of 28×28 input and 5×5 filter size.
– After passing pooling layer 1: there are 20x12x12 pixels?
2. For Conv2:
– 50x5x5 =1250 weights (why there are only 50×20=1000)
– 50x20x8x8 outputs??
– After passing pooling layer 2: there are 50x20x4x4 outputs??
3. dense1: why? did you choose 500 neurons, the number of weights in the output file is 500×2450?
Please help me to correct them. Thank you in advance.
hello,Great tutorial but I have problem with the code that I downloaded,it doesnt contain any code in __init.py__ file.
Which
__init__.pyfile are you referring to? There are multiple ones.all the __init__.py except for the one in networks folder which has – “from lenet import LeNet”
That is correct. Allnetworks should be empty. The
__init__.pysimply indicates that a given directory is part of a Python module.Hi Adrian,
I developed cnn model and want to get class probabilities as prediction. Let me know how to extract class probabilities.
If you are using Keras, you can use
.predict_probato obtain the probabilities each of the class labels.Hi Adrian,
Can i use this model to train for pedestrian-detection?
Please give me some suggestion !
Hi Jay — I would suggest you take a look at the Histogram of Oriented Gradients framework for object detection. I detail how to implement this framework inside the PyImageSearch Gurus course.
I already used HOG for pedestrian-detection , but it is too slow to detect immediately.
I would suggest reading up on how to optimize the detectMultiScale method of OpenCV’s pedestrian detector.
Sir I didn’t understand the concept behind choosing Dense(500) . If you Explain this more thoroughly then it will be helpful for me.. thank you
The “Dense” class refers to the fully-connected layer in a network. Therefore there are 500 nodes in the fully-connected layer.
Why 500 specifically, can you please explain why you chose 500 and not any other number?
This was the number of nodes recommended by Yann LeCun in his original publication. This is a hyperparameter we typically tune.
I have a problem with RAM. I’m running Keras with Theano on CPU(in Anaconda, Win7x64, 8GB RAM) and the program runs fine but i’m only able to make one epoch that uses 6GB of RAM. It grows linearly when it starts training. Possible solutions or any reasons why?
At least 1 epoch gives 86% accuracy.
That is indeed very strange, 6GB of RAM should not be required. How long does it take for that one epoch to complete?
It takes about 1:30 – 2 minutes.
I tried to solve the problem by saving the model to a .json file and repeat the process until i get good results.
It works fine but it’s not optimal.
That’s definitely slow. Have you installed any linear algebra optimization libraries such as BLAS or LAPACK? Make sure those libraries are installed, then re-install Keras.
hi
why you choice 20 filters for conv1. with the knowledge that if you stride by 4 we need 49 filter to convoluted input image (28*28) and that minimum number of filters
Twenty filters was used for the first CONV layer because that is what Yann LeCun used in his original LeNet paper (since we are replicating his work). The stride has nothing to do with the number of filters, the stride simply reduces the spatial dimensions of the input volume.
If you are interested in reading more about deep learning fundamentals, take a look at my book, Deep Learning for computer Vision with Python.
hi
can I apply CNN to classifying image with height not equal width
In this case you would typically resize your image to the fixed size required by the CNN.
Hi Adrian,
I downloaded your code, but when I attempt to train the model, I receive ‘ModuleNotFoundError: no module named ‘lenet” on the line ‘from pyimagesearch.cnn.networks import LeNet’
Any ideas? I am using Python 3.6.1 if this could make a difference.
Thanks
Go into the
__init__.pyfile insidenetworksand change the import statement to be:from .lenet import LeNetThe extra “.” is required as that is how Python 3 handles imports.
I’ll also update the code download with this change as well.
Hi Adrian,
Thank you for such a nice tutorial. I could run it successfully, but had to fix a few things. Just thought to share it in case someone else runs into the same problem:
1. The name of the dataset has been changed from “MNIST Original” into “MNIST (Original)”. You can check this by going to: http://mldata.org/repository/data/viewslug/mnist-original/
2. I had to change the ordering of the image dimension in a few places in the code. I kept getting errors, and I tried different things that people suggested, but everything that I tried resulted into another error, here is the thing that finally worked for me:
In lenet.py :
1. In line 17 changed the input shape to input_shape=(width, height, depth) (apparently this is the image ordering for tensorflow)
2. In line 19, I added an extra argument to the MaxPooling2D which is dim_ordering=”tf” (takes the image ordering in the tensorflow standard). I did the same thing for the MaxPooling2D in line 24.
In lenet.mnist:
1. changed line 31 into data = data[:, :, :, np.newaxis]. Again, to follow the tensorflow image dimension ordering.
Another error that I got was not recognizing LeNet in the second line of lenet_mnist.py. To fix this I had to change the name of lenet.py into LeNet.py. Also, I had to change line 45 into LeNet.LeNet.build. I still don’t understand why lenet couldn’t be recognized. Any idea why this happened?
I run this with python 2.7.13 (anaconda 1.6.3), tensorflow 1.2.1, keras 2.0.5
Thanks for sharing. This code was originally intended for a Theano backend, hence the “channels first” ordering rather than “channels last”. I’ll be discussing more about this inside Deep Learning for Computer Vision with Python.
As for your second issue, it sounds like your
__init__.pyfiles don’t have the correct imports. Make sure you use the “Downloads” section of this blog post to download the source code and compare it to mine.Thank you for your post. It’s seems its work. I would give suggest to Adrian to replace his code with Niki’s ideas. Today more people use tf than Theano.
Yes, I will be updating the post in the future.
Great Stuff! I had to use single quotes for MaxPooling2D argument, i.e., dim_ordering = ‘tf’
Thank you so so much Niki, It helped me a lot, was lost on how to convert theano to Tensorflow. Best wishes to you!
The tutorial is amazing, but my question is regarding the dataset. How can we tweek our own dataset so that we can split and download it using a similar function call?
Thank you.
Hi Mansoor — I’m covering how to train neural networks from scratch using your own custom datasets inside Deep Learning for Computer Vision with Python. I suggest you start there.
I’m using anaconda3 on windows. Numpy and Scipy are using mkl. Still the ram usage jumps sharply and the program crashes on epic 13. Though 12 is also okay, some idea what causes that would let me try more complex networks.
OS: Windows 8.1
Environment: Anaconda3 with python 2.7.13 64 bit
Ram: 16 gb
Hi Adrian. Thanks a lot for an awesome tutorial. I am facing a strange problem. Whenever I run my script from the root directory (where our driver program resides) I always get an import error as follows:
ImportError: No module named ‘lenet’
The file containing the LeNet class is named lenet. I am running exactly the same source code as you’ve provided for download. I have the __init__.py files as well, for the interpreter to understand that the directory is a package.
The __init__.py file in the networks directory contains the import statement as well. I just have no clue why I am getting this ImportError. Any ideas what I might be doing wrong, or how I can resolve this?
Hi Shivank — what Python version are you using? Python 2.7 or Python 3? Secondly, this might be an issue with your directory structure. I think the LeNet class you are trying to import is not in the same directory as your driver script code.
How can I run it in windown?
Thanks for so much friendly introduction of CNN.
Kindly guide me a little bit more.
What if we want to add more classes like I want to add alphabets from A to Z?
Your more help will be highly appreciated.
Hi Rauf — you would need to gather training data for each of your characters. Training data is the most important part. Once you have your training data (and class labels) you increase the number output labels to match the number of characters you want to recognize. You may also need to modify the network architecture to include more parameters. If you’re interested in studying deep learning in more detail, please take a look at my book, Deep Learning for Computer Vision with Python where I demonstrate how to build your own datasets and train your own networks.
Hi Adrian,
I import Caffe and want to save the model as .caffemodel, is that possible? What do I need (or change) in code and installation?
Regards,
Alice
This blog post is for Keras. You cannot import a Caffe model into Keras and then export it as a Caffe model. This would require writing a custom import/export script.
Would you make a tutorial with Caffe?
This tutorial doesn’t work with the newest version of Keras/Tensorflow anymore.
For it to work correctly, you have to modify your input shape. Here, it’s shaped like [samples][channels][height][width], for the current version of Tensorflow and Keras it should be shaped like [samples][height][width][channels].
So basically in the lenet_mnist.py, line 30 and 31 should be:
data = dataset.data.reshape((dataset.data.shape[0], 28, 28))
data = data[:, :, :, np.newaxis]
instead of:
data = dataset.data.reshape((dataset.data.shape[0], 28, 28))
data = data[:, np.newaxis, :, :]
I would recommended the following updated implementation here.
I did follow that one a few days ago, but it doesn’t go into categorical evaluation (which I wanted to try to learn/understand).
The Santa tutorial was great though – so is this one – thank you so much for those!
You can classify more than two categories by using “categorical_crossentropy” loss and then adding the extra classes to the “images” director. Literally nothing else in the code needs to be changed.
Is there any possibility to use fuzzy instead of neural network in fc layer?
do you know “slim” of tensorflow.
Just to clarify, are you referring to the TensorFlow “slim” module of their “research” GitHub repo?
yep, the tensorflow module, do you use it ? and by the way.
can you post a instruction of how to use my image data to the “mnist data”, cause we need to transfer our data to the mnist type if we want to use designed model, such as lenet.
thanks a lot.
I use TensorFlow + slim primarily for object detection. If you’re looking to study deep learning, including how to use the slim module, I would suggest referring to Deep Learning for Computer Vision with Python. Inside the book I also discuss (and provide code) for my best practices and techniques for working with your own custom datasets. I hope that helps point you in the right direction!
hi,
you’ve mentioned multiple times(in the article and comments) that you’ve built this architecture to be similar to the one Yann LeCun used in his original paper. Could you please share the name of or the link to this paper.
Sure, you can find the paper here.
Hi Adrian!! Thanks for giving insight into the implementation of LeNet on MNIST so clearly.
I have a query which is, once we download the zip file of code, do we have to run
python lenet_mnist.py –save-model 1 –weights output/lenet_weights.hdf5
on Anaconda prompt in the directory where lenet_mnist.py is present if I am using Anaconda??
You would run the “lenet_mnist.py” script in the directory you downloaded it from. Make sure you execute the script via the command line.
Hi Adrian,
Really good post you have here.
One query, what to do, when I have already downloaded the MNIST once?
[INFO] downloading MNIST…
I don’t want to download it all the time, every-time I run the script :
python lenet_mnist.py –save-model 1 –weights output/lenet_weights.hdf5
Is there a way, to use the downloaded weights file? What will be the command for it?
I tried : python lenet_mnist.py –save-model 1 –load-model output/lenet_weights.hdf5, then also it downloads it instead of loading the already downloaded file.
Thanks,
Reema
MNIST only needs to be downloaded once. Once it is downloaded it will automatically be cached.
Thank you for this wonderful tutorial for such a simple network that can even run on raspberry-Pi!
I came across another tutorial online, using a same two-layer CNN with slightly different number of nodes.
https://machinelearningmastery.com/handwritten-digit-recognition-using-convolutional-neural-networks-python-keras/
Your network (Yan Lecun) has over a million parameters. It took 22 mins for one epoch and the accuracy after one epoch is only 73%
Convo 20x5x5 Param=520
Convo 50x5x5 Param=25050
Dense 500 Param=1225500
Dense 10 Param=5010
But the other network on the website has only 60k parameters. It took only 8.5 mins for one epoch and the accuracy is 97%
Convo 30x5x5 Param=780
Convo 15x3x3 Param=4065
Dense 128 Param=48128
Dense 50 Param=6450
Dense 10 Param=510
My question is: is there any general guideline for choosing those hyper-parameters?
Is a million weights overkill? For this dataset of 60k images? And output of 10 classes?
Another question is the other network put the activation into the same layer, is it same as adding a separate activation layer?
Thanks.
Hey Joshua — I would suggest you read Deep Learning for Computer Vision with Python where I teach you guidelines and best practices when choosing and tuning hyperparameters. You’ll also be getting a great education on Deep Learning and Computer Vision.