
If you’ve been following along with this series of blog posts, then you already know what a huge fan I am of Keras.
Keras is a super powerful, easy to use Python library for building neural networks and deep learning networks.
In the remainder of this blog post, I’ll demonstrate how to build a simple neural network using Python and Keras, and then apply it to the task of image classification.
A simple neural network with Python and Keras
To start this post, we’ll quickly review the most common neural network architecture — feedforward networks.
We’ll then discuss our project structure followed by writing some Python code to define our feedforward neural network and specifically apply it to the Kaggle Dogs vs. Cats classification challenge. The goal of this challenge is to correctly classify whether a given image contains a dog or a cat.
We’ll review the results of our simple neural network architecture and discuss methods to improve it.
Our final step will be to build a test script that will load images and classify them with OpenCV, Keras, and our trained model.
Feedforward neural networks
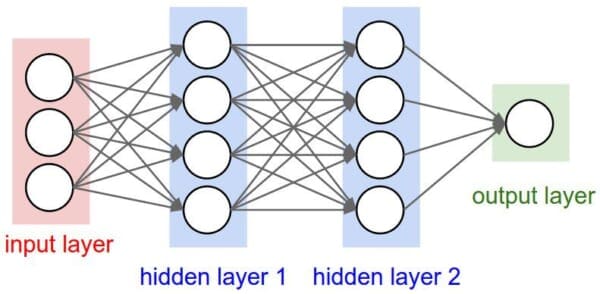
While there are many, many different neural network architectures, the most common architecture is the feedforward network:
In this type of architecture, a connection between two nodes is only permitted from nodes in layer i to nodes in layer i + 1 (hence the term feedforward; there are no backwards or inter-layer connections allowed).
Furthermore, the nodes in layer i are fully connected to the nodes in layer i + 1. This implies that every node in layer i connects to every node in layer i + 1. For example, in the figure above, there are a total of 2 x 3 = 6 connections between layer 0 and layer 1 — this is where the term “fully connected” or “FC” for short, comes from.
We normally use a sequence of integers to quickly and concisely describe the number of nodes in each layer.
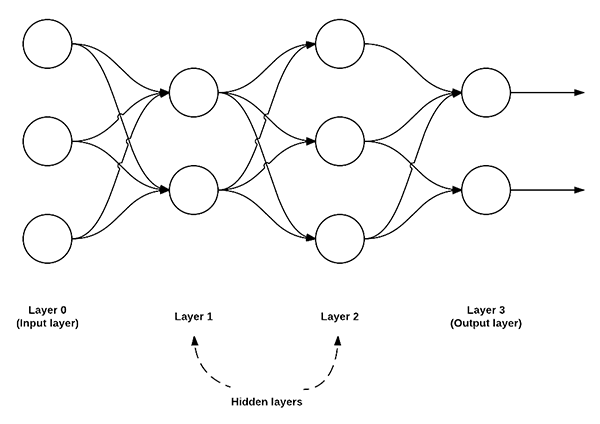
For example, the network above is a 3-2-3-2 feedforward neural network:
- Layer 0 contains 3 inputs, our
 values. These could be raw pixel intensities or entries from a feature vector.
values. These could be raw pixel intensities or entries from a feature vector. - Layers 1 and 2 are hidden layers, containing 2 and 3 nodes, respectively.
- Layer 3 is the output layer or the visible layer — this is where we obtain the overall output classification from our network. The output layer normally has as many nodes as class labels; one node for each potential output. In our Kaggle Dogs vs. Cats example, we have two output nodes — one for “dog” and another for “cat”.
 values. These could be raw pixel intensities or entries from a feature vector.
values. These could be raw pixel intensities or entries from a feature vector.Project directory structure
Before we begin, head to the “Downloads” section of this blog post, and download the files and data. From there you’ll be able to follow along as we work through today’s examples.
Once your zip is downloaded, extract the files.
From within the directory, let’s run the tree command with two command line arguments to list our project structure:
$ tree --filelimit 10 --dirsfirst . ├── kaggle_dogs_vs_cats │ └── train [25000 entries exceeds filelimit, not opening dir] ├── test_images [50 entries exceeds filelimit, not opening dir] ├── output │ └── simple_neural_network.hdf5 ├── simple_neural_network.py └── test_network.py 4 directories, 4 files
The first command line argument is important as it prevents tree from displaying all of the image files and cluttering our terminal.
The Kaggle Dogs vs. Cats dataset is in the relevant directory (kaggle_dogs_vs_cats). All 25,000 images are contained in the train subdirectory. This data came from the train.zip dataset available on Kaggle.
I’ve also included 50 samples from the Kaggle test1.zip available on their website.
The output directory contains our serialized model that we’ll generate with Keras at the bottom of the first script.
We’ll review the two Python scripts, simple_neural_network.py and test_network.py , in the next sections.
Implementing our own neural network with Python and Keras
Now that we understand the basics of feedforward neural networks, let’s implement one for image classification using Python and Keras.
To start, you’ll want to follow the appropriate tutorial for your system to install TensorFlow and Keras:
- Configuring Ubuntu for deep learning with Python
- Setting up Ubuntu 16.04 + CUDA + GPU for deep learning with Python
- Configuring macOS for deep learning with Python
Note: A GPU is not needed for today’s blog post — your laptop can run this very elementary network easily. That being said, in general I do not recommend using a laptop for deep learning. Laptops are for productivity rather than working with TB sized datasets required for many deep learning activities. I recommend Amazon AWS using my pre-configured AMI or Microsoft’s DSVM. Both of these environments are ready to go in less than 5 minutes.
From there, open up a new file, name it simple_neural_network.py , and we’ll get coding:
# import the necessary packages from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from keras.models import Sequential from keras.layers import Activation from keras.optimizers import SGD from keras.layers import Dense from keras.utils import np_utils from imutils import paths import numpy as np import argparse import cv2 import os
We start off by importing our required Python packages. We’ll be using a number of scikit-learn implementations along with Keras layers and activation functions. If you do not already have your development environment configured for Keras, please see this blog post.
We’ll be also using imutils, my personal library of OpenCV convenience functions. If you do not already have imutils installed on your system, you can install it via pip :
$ pip install imutils
Next, let’s define a method to accept and image and describe it. In previous tutorials, we’ve extracted color histograms from images and used these distributions to characterize the contents of an image.
This time, let’s use the raw pixel intensities instead. To accomplish this, we define the image_to_feature_vector function which accepts an input image and resizes it to a fixed size, ignoring the aspect ratio:
def image_to_feature_vector(image, size=(32, 32)): # resize the image to a fixed size, then flatten the image into # a list of raw pixel intensities return cv2.resize(image, size).flatten()
We resize our image to fixed spatial dimensions to ensure each and every image in the input dataset has the same “feature vector” size. This is a requirement when utilizing our neural network — each image must be represented by a vector.
In this case, we resize our image to 32 x 32 pixels and then flatten the 32 x 32 x 3 image (where we have three channels, one for each Red, Green, and Blue channel, respectively) into a 3,072-d feature vector.
The next code block handles parsing our command line arguments and taking care of a few initializations:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", required=True,
help="path to output model file")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the data matrix and labels list
data = []
labels = []
We only need a single switch here, --dataset , which is the path to the input directory containing the Kaggle Dogs vs. Cats images. This dataset can be downloaded from the official Kaggle Dogs vs. Cats competition page.
Line 30 grabs the paths to our --dataset of images residing on disk. We then initialize the data and labels lists, respectively, on Lines 33 and 34.
Now that we have our imagePaths , we can loop over them individually, load them from disk, convert the images to feature vectors, and the update the data and labels lists:
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
# load the image and extract the class label (assuming that our
# path as the format: /path/to/dataset/{class}.{image_num}.jpg
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
# construct a feature vector raw pixel intensities, then update
# the data matrix and labels list
features = image_to_feature_vector(image)
data.append(features)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))
The data list now contains the flattened 32 x 32 x 3 = 3,072-d representations of every image in our dataset. However, before we can train our neural network, we first need to perform a bit of preprocessing:
# encode the labels, converting them from strings to integers
le = LabelEncoder()
labels = le.fit_transform(labels)
# scale the input image pixels to the range [0, 1], then transform
# the labels into vectors in the range [0, num_classes] -- this
# generates a vector for each label where the index of the label
# is set to `1` and all other entries to `0`
data = np.array(data) / 255.0
labels = np_utils.to_categorical(labels, 2)
# partition the data into training and testing splits, using 75%
# of the data for training and the remaining 25% for testing
print("[INFO] constructing training/testing split...")
(trainData, testData, trainLabels, testLabels) = train_test_split(
data, labels, test_size=0.25, random_state=42)
Lines 61 and 62 handle scaling the input data to the range [0, 1], followed by converting the labels from a set of integers to a set of vectors (a requirement for the cross-entropy loss function we will apply when training our neural network).
We then construct our training and testing splits on Lines 67 and 68, using 75% of the data for training and the remaining 25% for testing.
For a more detailed review of the data preprocessing stage, please see this blog post.
We are now ready to define our neural network using Keras:
# define the architecture of the network
model = Sequential()
model.add(Dense(768, input_dim=3072, init="uniform",
activation="relu"))
model.add(Dense(384, activation="relu", kernel_initializer="uniform"))
model.add(Dense(2))
model.add(Activation("softmax"))
On Lines 71-76 we construct our neural network architecture — a 3072-768-384-2 feedforward neural network.
Our input layer has 3,072 nodes, one for each of the 32 x 32 x 3 = 3,072 raw pixel intensities in our flattened input images.
We then have two hidden layers, each with 768 and 384 nodes, respectively. These node counts were determined via a cross-validation and hyperparameter tuning experiment performed offline.
The output layer has 2 nodes — one for each of the “dog” and “cat” labels.
We then apply a softmax activation function on top of the network — this will give us our actual output class label probabilities.
The next step is to train our model using Stochastic Gradient Descent (SGD):
# train the model using SGD
print("[INFO] compiling model...")
sgd = SGD(lr=0.01)
model.compile(loss="binary_crossentropy", optimizer=sgd,
metrics=["accuracy"])
model.fit(trainData, trainLabels, epochs=50, batch_size=128,
verbose=1)
To train our model, we’ll set the learning rate parameter of SGD to 0.01. We’ll use the binary_crossentropy loss function for the network as well.
In most cases, you’ll want to use just crossentropy , but since there are only two class labels, we use binary_crossentropy . For > 2 class labels, make sure you use crossentropy .
The network is then allowed to train for a total of 50 epochs, meaning that the model “sees” each individual training example 50 times in an attempt to learn an underlying pattern.
The final code block evaluates our Keras neural network on the testing data:
# show the accuracy on the testing set
print("[INFO] evaluating on testing set...")
(loss, accuracy) = model.evaluate(testData, testLabels,
batch_size=128, verbose=1)
print("[INFO] loss={:.4f}, accuracy: {:.4f}%".format(loss,
accuracy * 100))
# dump the network architecture and weights to file
print("[INFO] dumping architecture and weights to file...")
model.save(args["model"])
Classifying images using neural networks with Python and Keras
To execute our simple_neural_network.py script, make sure you have already downloaded the source code and data for this post by using the “Downloads” section at the bottom of this tutorial.
The following command can be used to train our neural network using Python and Keras:
$ python simple_neural_network.py --dataset kaggle_dogs_vs_cats \
--model output/simple_neural_network.hdf5
The output of our script can be seen in the screenshot below:
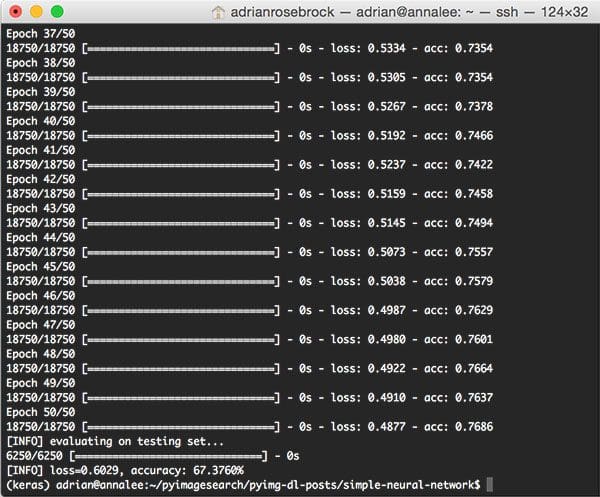
On my Titan X GPU, the entire process of feature extraction, training the neural network, and evaluation took a total of 1m 15s with each epoch taking less than 0 seconds to complete.
At the end of the 50th epoch, we see that we are getting ~76% accuracy on the training data and 67% accuracy on the testing data.
This ~9% difference in accuracy implies that our network is overfitting a bit; however, it is very common to see ~10% gaps in training versus testing accuracy, especially if you have limited training data.
You should start to become very worried regarding overfitting when your training accuracy reaches 90%+ and your testing accuracy is substantially lower than that.
In either case, this 67.376% is the highest accuracy we’ve obtained thus far in this series of tutorials. As we’ll find out later on, we can easily obtain > 95% accuracy by utilizing Convolutional Neural Networks.
Classifying images using our Keras model
We’re going to build a test script to verify our results visually.
So let’s go ahead and create a new file named test_network.py in your favorite editor and enter the following code:
# import the necessary packages
from __future__ import print_function
from keras.models import load_model
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
def image_to_feature_vector(image, size=(32, 32)):
# resize the image to a fixed size, then flatten the image into
# a list of raw pixel intensities
return cv2.resize(image, size).flatten()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to output model file")
ap.add_argument("-t", "--test-images", required=True,
help="path to the directory of testing images")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="size of mini-batches passed to network")
args = vars(ap.parse_args())
On Lines 2-8, we load necessary packages. These should be familiar as we used each of them above, with the exception of load_model from keras.models . The load_model module simply loads the serialized Keras model from disk so that we can send images through the network and acquire predictions.
The image_to_feature_vector function is identical and we include it in the test script because we want to preprocess our images in the same way as training.
Our script has three command line arguments which can be provided at runtime (Lines 16-23):
--model: The path to our serialized model file.--test-images: The path to the directory of test images.--batch-size: Optionally, the size of mini-batches can be specified with the default being32.
You do not need to modify Lines 16-23 — if you are unfamiliar with argparse and command line arguments, just give this blog post a read.
Moving on, let’s define our classes and load our serialized model from disk:
# initialize the class labels for the Kaggle dogs vs cats dataset
CLASSES = ["cat", "dog"]
# load the network
print("[INFO] loading network architecture and weights...")
model = load_model(args["model"])
print("[INFO] testing on images in {}".format(args["test_images"]))
Line 26 creates a list of the classes we’re working with today — a cat and a dog.
From there we load the model into memory so that we can easily classify images as needed (Line 30).
Let’s begin looping over the test images and predicting whether each image is a feline or canine:
# loop over our testing images
for imagePath in paths.list_images(args["test_images"]):
# load the image, resize it to a fixed 32 x 32 pixels (ignoring
# aspect ratio), and then extract features from it
print("[INFO] classifying {}".format(
imagePath[imagePath.rfind("/") + 1:]))
image = cv2.imread(imagePath)
features = image_to_feature_vector(image) / 255.0
features = np.array([features])
We begin looping over all images in the testing directory on Line 34.
First, we load the image and preprocess it (Lines 39-41).
From there, let’s send the image through the neural network:
# classify the image using our extracted features and pre-trained
# neural network
probs = model.predict(features)[0]
prediction = probs.argmax(axis=0)
# draw the class and probability on the test image and display it
# to our screen
label = "{}: {:.2f}%".format(CLASSES[prediction],
probs[prediction] * 100)
cv2.putText(image, label, (10, 35), cv2.FONT_HERSHEY_SIMPLEX,
1.0, (0, 255, 0), 3)
cv2.imshow("Image", image)
cv2.waitKey(0)
A prediction is made on Lines 45 and 46.
The remaining lines build a display label containing the class name and probability score and overlay it on the image (Lines 50-54). Each iteration of the loop, we wait for a keypress so that we can check images one at a time (Line 55).
Testing our neural network with Keras
Now that we’re finished implementing our test script, let’s run it and see our hard work in action. To grab the code and images, be sure to scroll down to the “Downloads” section of this blog post.
When you have the files extracted, to run our test_network.py we simply execute it in the terminal and provide two command line arguments:
$ python test_network.py --model output/simple_neural_network.hdf5 \ --test-images test_images Using TensorFlow backend. [INFO] loading network architecture and weights... [INFO] testing on images in test_images [INFO] classifying 48.jpg [INFO] classifying 49.jpg [INFO] classifying 8.jpg [INFO] classifying 9.jpg [INFO] classifying 14.jpg [INFO] classifying 28.jpg
Did you see the following error message?
Using TensorFlow backend. usage: test_network.py [-h] -m MODEL -t TEST_IMAGES [-b BATCH_SIZE] test_network.py: error: the following arguments are required: -m/--model, -t/--test-images
This message describes how to use the script with command line arguments.
Are you unfamiliar with command line arguments and argparse? No worries — just give this blog post on command line arguments a quick read.
If everything worked correctly, after the model loads and runs the first inference, we’re presented with a picture of a dog:
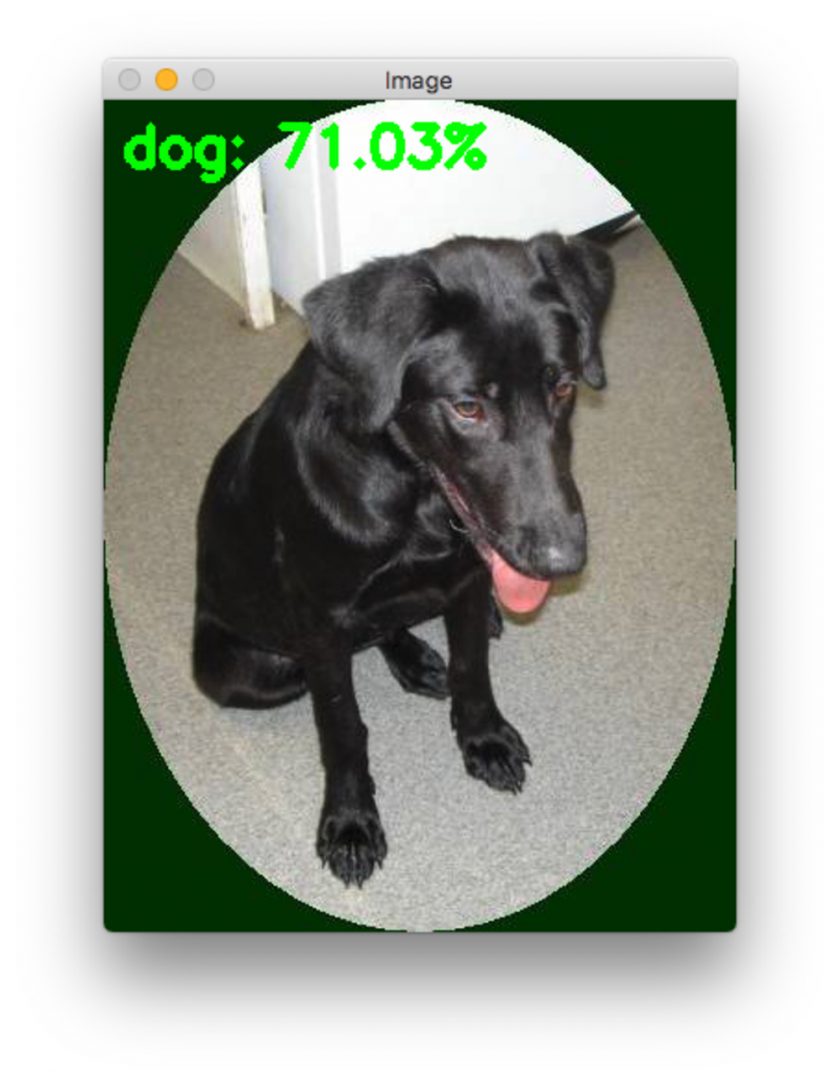
The network classified the dog with 71% prediction accuracy. So far so good!
When you’re ready, press a key to cycle to the next image (the window must be active).

Our cute and cuddly cat with white chest hair passed the test with 77% accuracy!
Onto Lois, a dog:

Lois is definitely a dog — our model is 97% sure of it.
Let’s try another cat:

Yahoo! This ball of fur is correctly predicted to be a cat.
Let’s try a yet another dog:

DOH! Our network thinks this dog is a cat with 61% confidence. Clearly this is a misclassification.
How could that be? Well, our network is only 67% accurate as we demonstrated above. It will be common to see a number of misclassifications.
Our last image is of one of the most adorable kittens in the test_images folder. I’ve named this kitten Simba. But is Simba a cat according to our model?
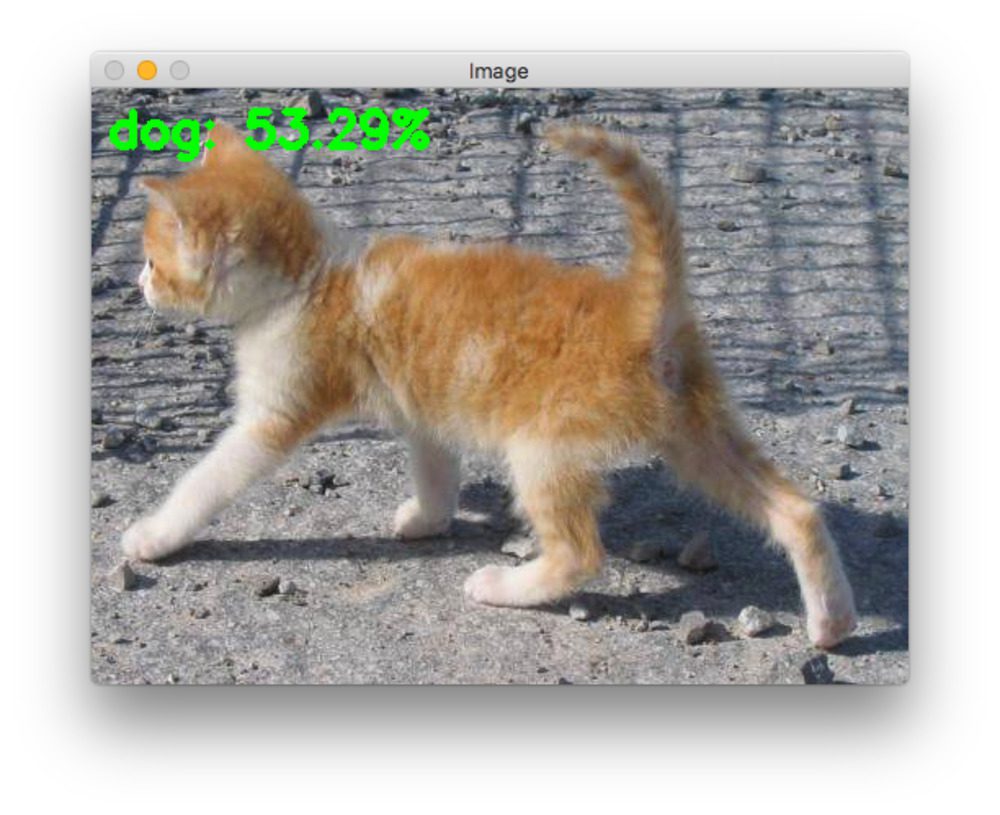
Alas, our network has failed us, but only by 3.29 percent. I was almost sure that our network would classify Simba correctly, but I was wrong.
Not to worry — there are improvements we can make to rank on the Top-25 leaderboard of the Kaggle Dogs vs. Cats challenge.
In my new book, Deep Learning for Computer Vision with Python, I demonstrate how to do just that. In fact, I’ll go so far to say that you’ll probably achieve a Top-5 position with what you’ll learn in the book.
To pick up your copy, just use this link: Deep Learning for Computer Vision with Python.
What's next? We recommend PyImageSearch University.
84 total classes • 114+ hours of on-demand code walkthrough videos • Last updated: February 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 84 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 84 Certificates of Completion
- ✓ 114+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 536+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post, I demonstrated how to train a simple neural network using Python and Keras.
We then applied our neural network to the Kaggle Dogs vs. Cats dataset and obtained 67.376% accuracy utilizing only the raw pixel intensities of the images.
Starting next week, I’ll begin discussing optimization methods such as gradient descent and Stochastic Gradient Descent (SGD). I’ll also include a tutorial on backpropagation to help you understand the inner-workings of this important algorithm.
Before you go, be sure to enter your email address in the form below to be notified when future blog posts are published — you won’t want to miss them!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

