
In today’s blog post, I interview Davis King, the creator and chief maintainer of dlib — a toolkit for real-world machine learning, computer vision, and data analysis in C++ (with Python bindings included, when appropriate).
I’ve personally used dlib in a number of projects (especially for object detection), so it’s quite the honor to be interviewing Davis on the PyImageSearch blog.
In the remainder of this blog post, Davis:
- Discusses his inspiration behind working in the computer vision and machine learning field.
- Explains the origin of dlib, why it exists, and what the library is mainly used for.
- Talks about the most difficult aspect of maintaining a popular open source library such as dlib.
- Describes the details behind his novel Max-Margin Object Detection paper, the cornerstone of object detection inside the dlib library.
- Reflects on the latest release of dlib which includes deep metric learning, suitable for state-of-the-art face recognition and face verification.
- Provides helpful suggestions and advice for readers who are are just getting started in their computer vision and deep learning careers.
The majority of these questions came from the brilliant Kyle McDonald whom I first met over Twitter when chatting with Davis regarding his latest dlib release. Kyle was nice enough to let me use and modify his original questions (along with adding a few others from myself and David McDuffee, the correspondence coordinator for PyImageSearch) to help make this interview possible. Be sure to give a shoutout to Kyle and David and tell them thanks!
To learn more about Davis King, the dlib toolkit, and how the library can be used for computer vision, machine learning, and deep learning, just keep reading.
An interview with Davis King, creator of dlib
Adrian: Hey Davis! I know you are very busy, thank you for taking the time to do this interview. It’s an honor and a privilege to have you on the PyImageSearch blog. For people who don’t know you, who are you and what do you do?
Davis: Thanks for having me. I’m a software developer who works on applied machine learning problems. Most of my work has been on machine vision and natural language processing for US defense applications. A lot of that is doing computer vision stuff with different kinds of sensors like sonar, lidar, radar, optical cameras, etc. I’ve also worked on industrial automation and sensing for autonomous underwater vehicles as well as machine learning systems for automated financial trading.
But publicly, most people know me as the author of the open source projects dlib (dlib.net) and MITIE (github.com/mit-nlp/MITIE).
Adrian: What inspired you to start working in the computer vision, machine learning, and deep learning field?
Davis: I wanted to work in some area that was interesting and important. For the longest time I’ve been convinced that automation is hugely important. Also, since I was a kid I knew I wanted to do some computer science thing and it turns out I’m pretty good at programming and I love math. Machine learning is where the cutting edge of automation is and involves a lot of math and programming, so here I am. I’m also a fan of sci-fi authors like Isaac Asimov and Vernor Vinge. Machine learning and its related fields seem like the most obvious path to interesting kinds of sci-fi AI. So that’s pretty cool too, even if still far away at this point 🙂
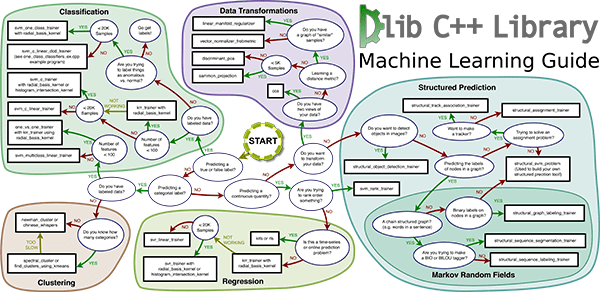
Adrian: What is dlib? What is the library mainly used for?
Davis: Dlib is a general purpose open source C++ software library. I started writing it 15 years ago and it initially had nothing to do with machine learning. I was then, and still am, a huge fan of contract programming however. So the initial motivation for dlib was to use the “design by contract” approach to make a bunch of nice cross-platform tools that weren’t available at the time. For instance, there weren’t non-frustrating portable threading, networking, or linear algebra tools for C++ 15 years ago.
So that’s how dlib started, as a cross-platform C++ library containing a bunch of random systems tools. For example, one of the most popular things in dlib is the dlib::pipe, a type-safe tool to pass messages between threads, which is used on a huge number of embedded/real-time processing applications that don’t do any kind of machine learning. And really, this is still what dlib is today, a collection of C++ tools written in the design by contract style. It’s just that I’ve spent the last 10 years making mostly machine learning tooling. So as of 2017, dlib is dominated by machine learning stuff, which has really driven its popularity in the last few years. In particular, the face detection, landmarking, and recognition example programs are now probably the most popular parts of dlib.
Adrian: Do you see dlib setting any precedents in terms of new research, or do you aspire to make published work more accessible?
Davis: Not really. There are some things in dlib that are novel, like the MMOD detector. But by and large my goal with dlib has always been to make really clean and easy to use tools. That’s a different goal from doing novel research and somewhat at odds with it since brand new ideas generally don’t come in clean and easy to use forms. Most of the time when I’m adding something to dlib it’s something from the published literature that’s already known to be really great, which means it’s been around for a little while.
So with dlib, my goals are definitely more about making published work more accessible. Which is also why I selected the license I did for dlib. I want as many people as possible to be able to take advantage of state-of-the-art machine learning tooling and use it for whatever they want. I think that’s great.
I also do most of my original research at work, which means I usually can’t publish it. Original research is also hard. Part of the reason I work on dlib is so I can do something relatively easier and relaxing after my day job. There is also the issue that original research, at least the kind I tend to do at my day job, is very application specific and not of very general interest. So it usually wouldn’t be appropriate for dlib anyway.
Adrian: Do you see dlib eventually being “feature complete”, or is it an ongoing project?
Davis: No, it will never be complete. Dlib is just a collection of useful tools, and obviously you can always make more tools, unless some day humans stop having ideas for new and better things. But that doesn’t seem likely. I also really enjoy writing software and putting it on the internet for free. I’ve been doing this for 15 years and I don’t see any reason for that to change any time soon.
Adrian: What is the most difficult aspect in maintaining an open source library like dlib?
Davis: Getting the damn build system to work everywhere. The core of dlib is easy to build. But the Python bindings? Not so straightforward. This is because, as I’ve learned from running dlib, there are a huge number of Python versions out there that are all incompatible in the sense that extension modules built for one Python won’t work with another. This is made even worse since dlib uses boost.python to build the extension modules. So you have this problem where someone will install boost.python for Python version A, then they will try to use it with Python version B, and BOOM, Python crashes. The problem here is that there are 3 places the Python version has to match (the Python interpreter you run with, the Python you compile boost.python against, and the Python you compile dlib against), which is a lot of opportunity for a user to mix things up. I get a lot of questions from users about this and it’s not clear to me how to avoid this kind of user confusion.
What makes this problem particularly bad is that it’s common, especially on the Mac, for there to be multiple versions of Python installed on a user’s system. There are also multiple package managers (e.g. conda, pip, brew). So there are all these ways of installing Python, boost.python, and dlib, and there are no standards or anything. So it’s super easy to get mixed up and incompatible versions.
Someone is working on moving dlib’s Python binding from boost.python to pybind11, which will improve this. That’s because there will then only be 2 things that need to match (compiled dlib and the Python interpreter) rather than 3 (dlib/python/boost). So that should make things a lot easier. But I’m sure I’m still going to get a lot of forum traffic from users with multiple versions of Python installed. So if anyone has any ideas about how to somehow make the Python binding install process more foolproof please hit me up on github 🙂
Adrian: One of the most exciting aspects of open source is seeing how your work is used by others. What are some of the more surprising ways you’ve seen dlib used?
Davis: I was really surprised to see artists using dlib. That’s something I never expected. The usual applications I think of are all industrial. So seeing guys like Kyle McDonald using it is surprising and cool.

Adrian: I remember reading your paper on Max-Margin Object Detection two years ago. This paper mainly focused on HOG-based detectors. You’ve recently updated dlib to also use this approach for object detection with deep learning. How did you incorporate your previous object detection research with the new deep learning detection module in dlib?
Davis: There were two main parts of that paper. The first, and most important, was the argument that you should use a certain loss function (the MMOD loss) when training an object detector because it makes much better use of the available training data. The second part was a description of an algorithm for optimizing this loss when the detector is some linear function of a fixed feature extractor (e.g. HOG, BoW, etc.). The paper then went on to do some experiments to show that the MMOD loss is a good idea and used HOG and a few other methods as examples. But there wasn’t anything fundamental about the choice of HOG there. I used it only because it was popular at the time I originally wrote the paper, which was way back in 2012.
Then along came CNNs, which are super good at object detection. I still thought the MMOD loss was the way to go when learning an object detector and wanted to try it with CNNs. All this entailed was coding up the MMOD loss function from the paper as a CNN loss layer. Then you just optimize the CNN like everyone does with stochastic gradient descent and it turns out the MMOD loss works great for CNNs too. In fact, one of the dlib example programs shows it training a CNN to find faces with just 4 training images. That’s way less training data than normally required to train a CNN, supporting the claim that MMOD makes more efficient use of training data.
Adrian: A lot of the recent work in dlib has centered around deep learning. How do you keep up with current deep learning trends (and in research trends in general?)
Davis: I spend a lot of time reading. That’s the only way. You have to read papers. It also helps to have friends who do this stuff too since they will tell you about good papers they found that you might have missed. But that’s not as important as just reading through papers on your own. So people reading this should not assume that just being on their own makes this much more difficult, since it doesn’t. You don’t need to be part of some big lab to be involved with this stuff.
For those interested, there are academic conferences that regularly publish great papers, which you can find for free on the internet. Some good conferences to Google are CVPR, ICML, NIPS, and ICLR. Google “CVPR papers” for instance and you will find all kinds of good stuff. Another great resource is Google Scholar. There you can search pretty much all the worlds academic literature. The results are sorted more or less by citation count so you can easily find papers that are really popular, because they are cited a lot. Those are usually the best papers to read if you are interested in some topic and don’t know where to start. You can also find the most important follow up research to any paper you like by clicking the “Cited by XX” link in google scholar. That will show you all the papers that cited a paper you like, and again, you can see the most popular paper that cited it. Allowing you to quickly find out where a research path went. Google Scholar is such a great resource, I can’t recommend it enough.
Note from Adrian: To add to Davis’ recommendations, I would also suggest Googling for “{{ topic }} survey paper” to find literature surveys (normally quite lengthy) that summarize research trends for a particular topic over a period of time. Finding survey papers is an excellent way to quickly get up-to-speed with previous, seminal approaches in your research area of interest.
Adrian: Between your work with MMOD on both HOG and deep learning, your library has obtained state-of-the-art results. Other than your arXiv paper on MMOD, is there a reason you don’t publish more often?
Davis: There are a couple of other papers I’ve published, but right, I generally don’t publish. There are no deep reasons for this, other than it takes a lot of time to create a publication quality paper, then get it accepted, and then to present it at a conference. I do have a day job and, most of the time, I can’t publish what I work on there. Moreover, most employers don’t really care if you publish. I don’t have the sort of job where publishing papers is important for career success like it would be if I worked purely in academia.
So I don’t have a lot of incentive to grind out papers. It’s also worth remembering that the fundamental point of publishing papers is to spread ideas. If I have some useful algorithm and I want people to use it, what’s the most effective way to make that happen? If I put it into dlib thousands of people will use it, which is a lot more than you can say for the average academic publication. In terms of maximizing the public good, I don’t think writing papers is the best use of my time.
There is also a lot of nonsense around publication. I actually wrote that MMOD paper back in 2012, a long time ago. I submitted it to CVPR two times as well as a few other places and each time got good reviews, except each time there would be one reviewer with some nonsense comments along the lines of “I think the experiments are wrong and don’t believe this works”. Some of them obviously didn’t even read the paper. These sorts of reviews are particularly irritating since, meanwhile, thousands of people are using the method with great success. But you can’t say “go run dlib and see it work” since submission is double blind and based only on the paper at most places. Anyway, everyone who publishes complains about this kind of thing. It’s a real grind and publishing papers takes a lot of time. I can spread ideas much more easily by putting them in dlib, with accompanying documentation that explains it. So that’s usually what I do.
Adrian: I see that ODNI and IARPA are listed as sponsors of dlib. Can you tell us more about this sponsorship? How did this connection happen? And how does it drive the development of dlib?
Davis: I’ve spent most of my career doing department of defence work and most of my friends are people I know from that world. The IARPA sponsorship happened because there was a desire for an easy to use C++ deep learning library. That is, something easy to use from a C++ program. There were lots of deep learning tools that were usable from Python or other languages, but nothing from C++, which is a little surprising since all the deep learning tools are ultimately written in C++ or C. So someone I know in the DoD talked me into writing an easy to use C++ deep learning API and putting it into dlib. The other open source project I maintain, MITIE, was also sponsored by the DARPA DoD agency, as part of DARPA’s XDATA project.
Most things in dlib aren’t sponsored by anyone though. Usually I’m working on dlib just for fun. But when someone wants to sponsor some addition or change to dlib I only accept it if I think it’s actually a useful tool that makes sense to put into dlib.

Adrian: The latest version of dlib ships with deep metric learning, comparable to other state-of-the-art techniques for face recognition. What motivated you to work with face recognition? Was it your intention to “solve” face recognition when you started working on this project? (Note: I’ve read your announcement blog post a few times and I’m actually a bit confused if you are doing face recognition [given an image of 1 face, recognizing in a database of N faces] or face verification [given two images, determine if the person in both photos is the same person or not]. If you could elaborate on that it would be super helpful).
Davis: Oh I don’t care about face recognition. For me, what is interesting are the learning algorithms, which in the last release was mainly the addition of some deep metric learning tools. Metric learning is useful for a lot of things that don’t have anything to do with faces. It’s exactly the sort of broadly useful and interesting tool I like to add to dlib. The main reason I included a face recognition model with the last dlib release was to show that the new tooling works properly. It’s also useful as a teaching tool. When I add new things to dlib I try to write example programs that explain how to use the tools and why they are useful and interesting. In the case of deep metric learning, the obvious example to write is one that shows how to do some kind of face recognition. So I added the face recognition stuff because that’s what makes the most compelling documentation, not because I care about face recognition.
As for your other question about recognition vs. verification, the example program does neither of these things. Instead, it shows how to embed faces into a 128D vector space where images of the same person appear close to each other. That by itself doesn’t do anything. But it’s the fundamental building block used by most systems that do interesting things with faces. So for example, if you want to do face verification, you take two faces and check if they are within some distance from each other in the 128D space. If they are close enough you say they are the same person. To do recognition, you instead say “here is my new face, which face in my database of people is it closest to? Or is it far away from everything in the database?”. Or to do face clustering, which one of the dlib examples does, you can run a clustering algorithm on the vector embeddings of faces and out pops clusters of faces.
In the blog post I mentioned that the new dlib model gets 99.38% on the LFW benchmark. That benchmark is a face verification benchmark. But you can easily use the tool to do face recognition or clustering.
Adrian: When developing a new feature for dlib, what does the general timeline look like? Is there a long gap between having a feature “basically done”, polishing it, and releasing it? Or do you publish as soon as the feature is “done”?
Davis: It depends on the feature. Most things don’t take that long. I think I wrote the face landmarking tool in dlib in a weekend, for example. Although sometimes it takes longer. It really depends on what it is. However, I do generally put it on the internet right away. You can usually see the code appear on github pretty much immediately. But I do wait to make official numbered dlib releases until I feel like everything is stable.
It also depends on what you include in the timeline. I spend a lot of time reading. Sometimes I’ll get excited about something, which might involve buying a textbook on some subject and reading it cover to cover. Then eventually there will be some specific thing I want to add to dlib. The time spent reading could be months or years depending on how you look at it.
I will also go on tangents sometimes. For example, when I’m writing the code for something it’s often the case that I realize I need some other tool to make the machine learning algorithm I want to make. So then I’ll go make that other tool. And while writing that other tool I might realize I need yet another tool to make it. Sometimes that gets out of hand and whole new major parts of dlib come out of it, like the optimization tooling or the linear algebra library.
Adrian: While rewarding, being the chief maintainer of an open source project requires an investment of your time, creativity, and patience. Do you find it challenging to manage the expectations of your users?
Davis: Not really. I work on dlib because I like to. I’ve also found that most people are sensible. The only persistently annoying questions I get from users are from people who obviously don’t know how to program and clearly don’t want to learn. Questions like “I don’t know how to program, can you tell me what to type?”. Invariably, answering these kinds of questions leads to endless further questions of “… ok … so what do I type after that?”. I definitely don’t have the time to be a free code writing service to everyone on the internet.
But I try to be helpful. I’ve also got a “suggested books” page for people who are just starting out.
Adrian: As an expert in your field, who do you talk to when you get “stuck” on a hard problem?
Davis: Usually no one. Not because I don’t want to, but because usually when you are stuck on something you don’t know anyone who knows how to fix it. For example, often when I try to implement something from a paper it doesn’t work at first. Why doesn’t it work? Is it because there is a bug in my code? Probably. Or is it because I’ve overlooked some subtle but important detail? Maybe. Is it because the paper was just wrong and it’s never going to work? Sometimes.
In each of these cases you will find that, after you spent a lot of time working on it and got stuck, you will be more familiar with the relevant details than whoever you might ask. Partly because you wrote your code and only you have seen it, partly because the paper you are trying to implement is fresh in your mind and not in the mind of someone else you might ask. So asking someone else might not help at all. That’s not to say that you shouldn’t do it, sometimes it helps a lot. But usually you are on your own when solving these kinds of problems.
Adrian: Do you have any advice for readers who are just starting out on their computer vision and deep learning careers?
Davis: Read a lot and don’t skip the fundamentals. That’s far and away the biggest problem people starting out face. Everyone wants to jump right to the cool part at the end. But you can’t do that. If you skip important things then understanding computer vision will seem impossible and you will quickly become frustrated. You have to understand a bunch of core areas before you can hope to make any kind of progress in computer vision or machine learning. However, if you learn things in the right order everything is a lot easier.
Specifically, I would say you need to know these six things well: How to program, calculus, linear algebra, probability, statistics, and numerical optimization. If you don’t know those six areas well then you won’t be able to understand machine learning and computer vision papers.
You also won’t be able to get a computer to do things, since you won’t know how to program. But no big deal, you can fix that by reading :). In particular, you should read a textbook on each of those topics. I realize that a lot of people don’t want to read textbooks. But if you don’t read you won’t learn. That’s just how it is.
So you have to find some way to get motivated to read textbooks on topics like linear algebra. A good way to get motivated is to pick some topic you are excited about. Maybe you find some paper at CVPR you really want to understand and implement. So you read it but there are parts you don’t understand. Maybe they use a lot of linear algebra and you are weak on linear algebra. Now you know you need to learn linear algebra, and more importantly, you have a specific goal that you are excited about propelling you to do it. You could pick a book from my list: http://dlib.net/books.html. Or you could go to a university website and see what book they use for the equivalent class.
Also, lots of machine learning algorithms ultimately involve complex looping computations with logical statements in the middle. These kinds of things are really really slow when executed in Python, so even though this is a Python blog and Python is great, I’m going to plug learning C++ as well :). So learn C++ too. There are many times when you will want to do some computation that isn’t easily vectorized in Python, or you want to write some custom CUDA code, or use SIMD instructions, or whatever. All that stuff is trivially easy in C++ but really hard or impossible in languages with high function call overhead, slow looping structures, and no access to hardware (e.g. Python, MATLAB, Lua). But if you know C++ you can just write a Python extension module to handle such things whenever you feel like it and it’s easy.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we interviewed Davis King, the creator and maintainer of dlib, a toolkit for real-world computer vision and machine learning applications.
While dlib is primarily used in C++ applications, there exist Python bindings for certain functionalities — although Davis recommends using C++ to harness the full power of dlib.
I can personally attest to the ease-of-use of dlib — I’ve used it in a number of computer vision projects and I even discuss it in the context of object detection inside the PyImageSearch Gurus course.
Again, I want to say thanks to Davis King for taking the time to do this interview (and give a shoutout to Kyle McDonald and David McDuffee for helping pull the questions for the interview together).
To keep up with Davis, be sure to follow him on Twitter as well as watch his GitHub projects.
To be notified when future blog posts go live (including interviews), be sure to enter your email address in the form below!

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

