So you’ve extracted color histograms from a set of images…
But how are you going to compare them for similarity?
You’ll need a distance function to handle that.
But which one? How you choose? And how do you compare histograms using Python and OpenCV?
Don’t worry, I’ve got you covered.
In this blog post I’ll show you three different ways to compare histograms using Python and OpenCV, including the cv2.compareHist function.
By the end of this post you’ll be comparing histograms like a pro.
Our Example Dataset

Our example dataset consists of four images: two Doge memes, a third Doge image, but this time with added Gaussian noise, thus distorting the image, and then, velociraptors. Because I honestly can’t do a blog post without including Jurassic Park.
We’ll be using the top-left image as our “query” image in these examples. We’ll take this image and then rank our dataset for the most “similar” images, according to our histogram distance function.
Ideally, the Doge images would appear in the top three results, indicating that they are more “similar” to the query, with the photo of the raptors placed at the bottom, since it is least semantically relevant.
However, as we’ll find out, the addition of Gaussian noise to the bottom-left Doge image can throw off our histogram comparison methods. Choosing which histogram comparison function to use is normally dependent on (1) the size of the dataset (2) as well as quality of the images in your dataset — you’ll definitely want to perform some experiments and explore different distance functions to get a feel for what metric will work best for your application.
With all that said, let’s have Doge teach us about comparing histograms.
Much histogram. Wow. I OpenCV. A lot computer vision, indeed.
3 Ways to Compare Histograms Using OpenCV and Python
# import the necessary packages
from scipy.spatial import distance as dist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import glob
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory of images")
args = vars(ap.parse_args())
# initialize the index dictionary to store the image name
# and corresponding histograms and the images dictionary
# to store the images themselves
index = {}
images = {}
The first thing we are going to do is import our necessary packages on Lines 2-7. The distance sub-package of SciPy contains implementations of many distance functions, so we’ll import it with an alias of dist to make our code more clean.
We’ll also be using matplotlib to display our results, NumPy for some numerical processing, argparse to parse command line arguments, glob to grab the paths to our image dataset, and cv2 for our OpenCV bindings.
Then, Lines 10-13 handle parsing our command line arguments. We only need a single switch, --dataset, which is the path to the directory containing our image dataset.
Finally, on Lines 18 and 19, we initialize two dictionaries. The first is index, which stores our color histograms extracted from our dataset, with the filename (assumed to be unique) as the key, and the histogram as the value.
The second dictionary is images, which stores the actual images themselves. We’ll make use of this dictionary when displaying our comparison results.
Now, before we can start comparing histograms, we first need to extract the histograms from our dataset:
# loop over the image paths
for imagePath in glob.glob(args["dataset"] + "/*.png"):
# extract the image filename (assumed to be unique) and
# load the image, updating the images dictionary
filename = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
images[filename] = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# extract a 3D RGB color histogram from the image,
# using 8 bins per channel, normalize, and update
# the index
hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8],
[0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
index[filename] = hist
First, we utilize glob to grab our image paths and start looping over them on Line 22.
Then, we extract the filename from the path, load the image, and then store the image in our images dictionary on Lines 25-27.
Remember, by default, OpenCV stores images in BGR format rather than RGB. However, we’ll be using matplotlib to display our results, and matplotlib assumes the image is in RGB format. To remedy this, a simple call to cv2.cvtColor is made on Line 27 to convert the image from BGR to RGB.
Computing the color histogram is handled on Line 32. We’ll be extracting a 3D RGB color histogram with 8 bins per channel, yielding a 512-dim feature vector once flattened. The histogram is normalized on Line 34 and finally stored in our index dictionary on Line 35.
For more details on the cv2.calcHist function, definitely take a look at my guide to utilizing color histograms for computer vision and image search engines post.
Now that we have computed histograms for each of our images, let’s try to compare them.
Method #1: Using the OpenCV cv2.compareHist function
Perhaps not surprisingly, OpenCV has a built in method to facilitate an easy comparison of histograms: cv2.compareHist. Check out the function signature below:
cv2.compareHist(H1, H2, method)
The cv2.compareHist function takes three arguments: H1, which is the first histogram to be compared, H2, the second histogram to be compared, and method, which is a flag indicating which comparison method should be performed.
The method flag can be any of the following:
-
cv2.HISTCMP_CORREL: Computes the correlation between the two histograms.cv2.HISTCMP_CHISQR: Applies the Chi-Squared distance to the histograms.cv2.HISTCMP_INTERSECT: Calculates the intersection between two histograms.cv2.HISTCMP_BHATTACHARYYA: Bhattacharyya distance, used to measure the “overlap” between the two histograms.
Now it’s time to apply the cv2.compareHist function to compare our color histograms:
# METHOD #1: UTILIZING OPENCV
# initialize OpenCV methods for histogram comparison
OPENCV_METHODS = (
("Correlation", cv2.HISTCMP_CORREL),
("Chi-Squared", cv2.HISTCMP_CHISQR),
("Intersection", cv2.HISTCMP_INTERSECT),
("Hellinger", cv2.HISTCMP_BHATTACHARYYA))
# loop over the comparison methods
for (methodName, method) in OPENCV_METHODS:
# initialize the results dictionary and the sort
# direction
results = {}
reverse = False
# if we are using the correlation or intersection
# method, then sort the results in reverse order
if methodName in ("Correlation", "Intersection"):
reverse = True
Lines 39-43 define our tuple of OpenCV histogram comparison methods. We’ll be exploring the Correlation, Chi-Squared, Intersection, and Hellinger/Bhattacharyya methods.
We start looping over these methods on Line 46.
Then, we define our results dictionary on Line 49, using the filename of the image as the key and its similarity score as the value.
I would like to draw special attention to Lines 50-55. We start by initializing a reverse variable to False. This variable handles how sorting the results dictionary will be performed. For some similarity functions a LARGER value indicates higher similarity (Correlation and Intersection). And for others, a SMALLER value indicates higher similarity (Chi-Squared and Hellinger).
Thus, we need to make a check on Line 54. If our distance method is Correlation or Intersection, our results should be sorted in reverse order.
Now, lets compare our histograms:
# loop over the index for (k, hist) in index.items(): # compute the distance between the two histograms # using the method and update the results dictionary d = cv2.compareHist(index["doge.png"], hist, method) results[k] = d # sort the results results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
We start by looping over our index dictionary on Line 58.
Then we compare the color histogram to our Doge query image (see the top-left image in Figure 1 above) to the current color histogram in the index dictionary on Line 61. The results dictionary is then updated with the distance value.
Finally, we sort our results in the appropriate order on Line 65.
Now, lets move on to displaying our results:
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the OpenCV methods
plt.show()
We start off by creating our query figure on Lines 68-71. This figure simply displays our Doge query image for reference purposes.
Then, we create a figure for each of our OpenCV histogram comparison methods on Line 74-83. This code is fairly self-explanatory. All we are doing is looping over the results on Line 78 and adding the image associated with the current result to our figure on Line 82.
Finally, Line 86 then displays our figures.
When executed, you should see the following results:
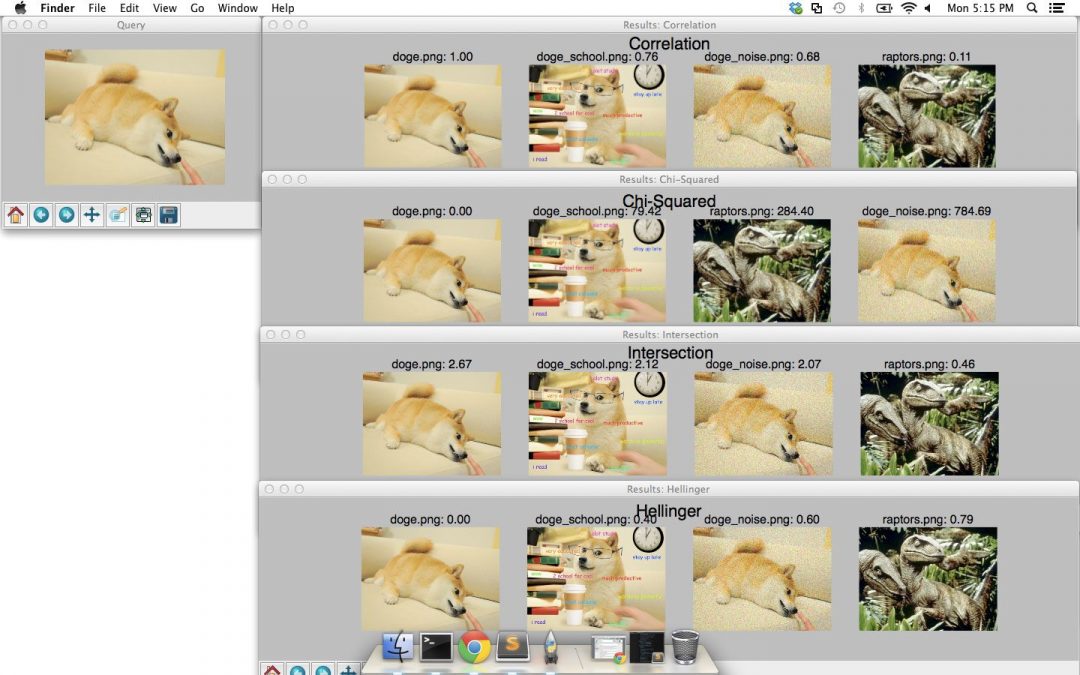
cv2.compareHist function.The image on the left is our original Doge query. The figures on the right contain our results, ranked using the Correlation, Chi-Squared, Intersection, and Hellinger distances, respectively.
For each distance metric, our the original Doge image is placed in the #1 result position — this makes sense because we are using an image already in our dataset as a query. We expect this image to be in the #1 result position since the image is identical to itself. If this image was not in the #1 result position, then we would know there is likely a bug somewhere in our code!
We then see the Doge school meme is in the second result position for all distance metrics.
However, adding Gaussian noise to the original Doge image can hurt performance. The Chi-Squared distance seems especially sensitive.
Does this mean that the Chi-Squared metric should not be used?
Absolutely not!
In reality, the similarity function you use is entirely dependent on your dataset and what the goals of your application. You will need to run some experiments to determine the optimally performing metric.
Next up, let’s explore some SciPy distance functions.
Method #2: Using the SciPy distance metrics
The main difference between using SciPy distance functions and OpenCV methods is that the methods in OpenCV are histogram specific. This is not the case for SciPy, which implements much more general distance functions. However, they are still important to note and you can likely make use of them in your own applications.
Let’s check out the code:
# METHOD #2: UTILIZING SCIPY
# initialize the scipy methods to compaute distances
SCIPY_METHODS = (
("Euclidean", dist.euclidean),
("Manhattan", dist.cityblock),
("Chebysev", dist.chebyshev))
# loop over the comparison methods
for (methodName, method) in SCIPY_METHODS:
# initialize the dictionary dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the method and update the results dictionary
d = method(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the SciPy methods
plt.show()
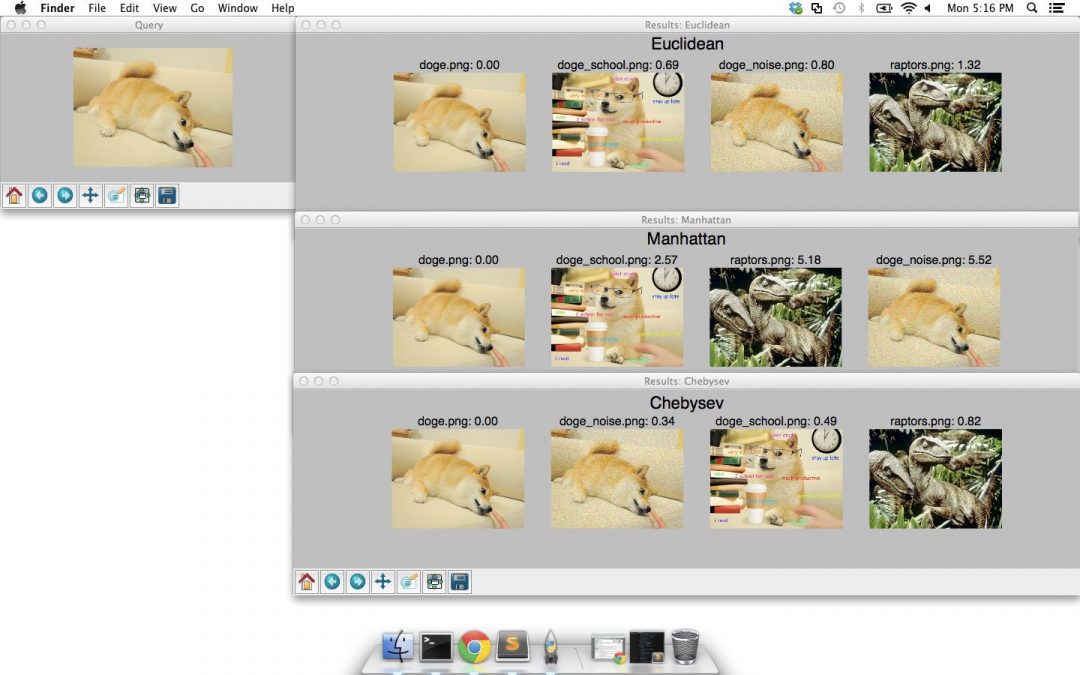
On Lines 90-93 we define tuples containing the SciPy distance functions we are going to explore.
Specifically, we’ll be using the Euclidean distance, Manhattan (also called City block) distance, and the Chebyshev distance.
From there, our code is pretty much identical to the OpenCV example above.
We loop over the distance functions on Line 96, perform the ranking on Lines 101-108, and then present the results using matplotlib on Lines 111-129.
The figure below shows our results:
Method #3: Roll-your-own similarity measure
The third method to compare histograms is to “roll-your-own” similarity measure. I define my own Chi-Squared distance function below:
# METHOD #3: ROLL YOUR OWN def chi2_distance(histA, histB, eps = 1e-10): # compute the chi-squared distance d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps) for (a, b) in zip(histA, histB)]) # return the chi-squared distance return d
And you may be thinking, hey, isn’t the Chi-Squared distance already implemented in OpenCV?
Yes. It is.
But the OpenCV implementation only takes the squared difference of each individual bin, divided by the bin count for the first histogram.
In my implementation, I take the squared difference of each bin count, divided by the sum of the bin count values, implying that large differences in the bins should contribute less weight.
From here, we can apply my custom Chi-Squared function to the images:
# initialize the results dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the custom chi-squared method, then update
# the results dictionary
d = chi2_distance(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: Custom Chi-Squared")
fig.suptitle("Custom Chi-Squared", fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the custom method
plt.show()
This code should start to feel pretty standard now.
We loop over the index and rank the results on Lines 144-152. Then we present the results on Lines 155-173.
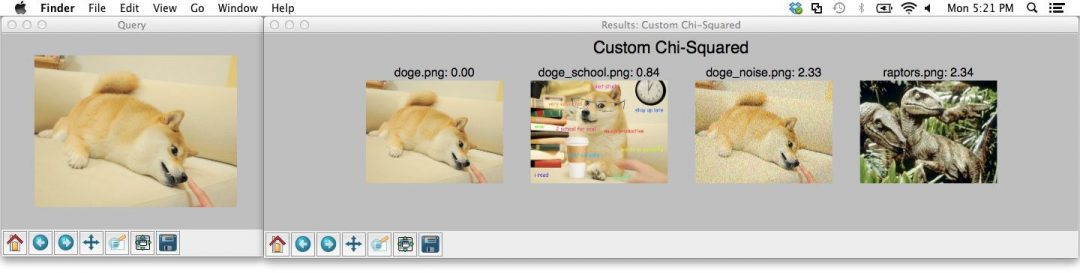
Below is the output of using my custom Chi-Squared function:
Take a second to compare Figure 4 to Figure 2 above. Specifically, examine the OpenCV Chi-Squared results versus my custom Chi-Squared function — the Doge image with noise added is now in the third result position rather than the fourth.
Does this mean you should use my implementation over the OpenCV one?
No, not really.
In reality, my implementation will be much slower than the OpenCV one, simply because OpenCV is compiled C/C++ code, which will be faster than Python.
But if you need to roll-your-own distance function, this is the best way to go.
Just make sure that you take the time to perform some experiments and see which distance function is right for your application.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post I showed you three ways to compare histograms using Python and OpenCV.
The first way is to use the built in cv2.compareHist function of OpenCV. The benefits of this function is that it’s extremely fast. Remember, OpenCV is compiled C/C++ code and your performance gains will be very high versus standard, vanilla Python.
The second benefit is that this function implements four distance methods that are geared towards comparing histograms, including Correlation, Chi-Squared, Intersection, and Bhattacharyya/Hellinger.
However, you are limited by these functions. If you want to customize the distance function, you’ll have to implement your own.
The second way to compare histograms using OpenCV and Python is to utilize a distance metric included in the distance sub-package of SciPy.
However, if the above two methods aren’t what you are looking for, you’ll have to move onto option three and “roll-your-own” distance function by implementing it by hand.
Hopefully this helps you with your histogram comparison needs using OpenCV and Python!
Feel free to leave a comment below or shoot me an email if you want to chat more about histogram comparison methods.
And be sure to signup for the newsletter below to receive awesome, exclusive content that I don’t publish on this blog!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Thanks , Best Ideas
Which is the best way to compare Faces ? any sugesion !!!
Hi Ansari, you’ll want to take a look at the Eigenfaces, Fisherfaces, and LBP (Local Binary Patterns) for face recognition family of algorithms. I hope this gets you started!
Hi sir, Actually I am trying to compare two faces (one from my database , another from my web cam) , but I couldnt.
can u help me with some examples or links ?
I have done Facedetection , cropping etc but need to campare two faces . plz give me some nice ideas .
thanks
Hi Ansari, please see my previous comment: If you want to compare the two faces and see if they face belongs to the same person, you’ll need to read up on the Eigenfaces and Fisherfaces algorithms. You can also compare faces using Local Binary Patterns.
Hi Adrian, thanks so much you’ve been a lot of help with our project we are trying to accomplish. What modules do I need to download for this, just opencv and numpy? Anything else?
OpenCV, NumPy, SciPy, and matplotlib are the standard stack.
Hi,
When I run this python program, I get KeyError: ‘Doge.png’ when below code is being ran
d = cv2.compareHist(index[“doge.png”], hist, method)
I’m new to python, I would like to learn from this.. whats the issue ?
Hi Sathish, it sounds like the path to the dataset of images is incorrect. Definitely make sure you are providing the correct path via command line argument (see the top of the code file for an example usage of the script). And if you are on a Windows system, definitely make sure the path separators are correct as well (“/” vs. “\”).
Hi Adrian, your tutorial is so good but a same problem is happened to me. In my Windows system, typed the example usage or change the “images” to the route of the images in the cmd window, it always said that the doge.png is wrong. Can you help me? Many thanks!
I honestly haven’t used a Windows system in quite some time, but make sure you use the “\” path separator instead of the “/” separator that Unix systems use. This could be why the image is not properly loaded.
In case anyone else has this problem…For Windows, my command looks like this: compare.py –dataset images
Then, edit in compare.py…
Ln 25 should be: for imagePath in glob.glob(args[“dataset”] + “\*.png”):
Ln 28 should be: filename = imagePath[imagePath.rfind(“\\”) + 1:]
Note: extra backslash to escape required backslash, or you will get: “SyntaxError: EOL while scannning single-quoted string”
Thanks for sharing!
it would improve the tutorial if you showed the histograms for each of the example images. then it would make more sense that the two doge images are usually rated as farther apart when to the eye they seem close.
in any case nice job
Good point Jeremy, thanks for the feedback!
Hi, thanks for the the information, but I have a question. I’ve generated histogram information, and saved them to disk. When re-importing them to perform a comparison I do the following:
hist_a =
hist_a = numpy.array( [float(x) for x in hist_a.split(‘,’)])
hist_b =
hist_b = numpy.array( [float(x) for x in hist_b.split(‘,’)])
cv2.compareHist( hist_a, hist_b, cv2.cv.CV_COMP_CORREL)
However, this throws an error about the H1.type not being CV_32F. Looking through your example the only thing that I can see is different is that I have not calculate the historgrams on the fly and instead had to read them from the disk. Is this something obvious that I’m missing?
Thanks in advance for any help you can give
UPDATE:
I’ve actually found the issue. When numpy was converting the float arrays it was using float64 instead of float32.
Just incase someone else comes across this and has the same problem just cast the values to float32 first e.g.
numpy.array([numpy.float32(x) for x in hist_a.split(‘,’)])
Hope that helps and thanks again for everything.
Nice, congrats on figuring out the issue Keith!
Hi Keith. Can you explain how to save histogram to disk?
There are a number of ways to save a histogram to disk. You can use a CSV file. A JSON file. And the
cPicklemethod works quite well. Which format did you want to use to store your histogram?At first I wanted to save histograms in mysql, but couldn’t find a simple way for this. Also i thought that in OpenCV exist some methods to save/read histograms fast and easy, but i didn’t find anything. If you know any method for sql I’ll be glad to read about it.
Now i read about “cPickle method” from your mesage, it is good for me. Thanks for the help!
I normally wouldn’t recommend storing raw histograms in a SQL database, but if you really wanted to, you can use
cPickleand store pickle’d data in a TEXT or BLOB column.Hi Adrian, great tutorial! Could this method be used for object tracking by comparing histograms of objects in subsequent frames? Is there a way to automatically create ROI’s around he contours of detected images and then use that as your query histogram for each object?
Absolutely. Tracking an object based on color and histograms can be done using CamShift. I detail how to use CamShift here.
As for “automatically” creating ROIs, you would need to filter your list of contours based on some criteria (i.e., shape, size, etc.) From there, you can extract the histogram form the region and use it as your query.
hi adrian, great tutorial. but how i write path on raspberry pi?
“Path to the directory of images” , thx for your help
Please download the source code to this post using the form provided where an example usage of the script is provided. You should also read up on the basics of command line arguments.
Hi Adrian, this tutorial really helps me a lot, but on my windows system, I don’t know how to use the Argparse package to load the dataset, could tell me how to do that? Many thanks!
I would suggest reading through this tutorial on how to use argparse.
I get an error below when I run it.
(“Correlation”, cv.cv.CV_COMP_CORREL)
Attribute Error: ‘module’object has no attribute ‘cv’
It sounds like you’re using OpenCV 3 — this tutorial was designed for OpenCV 2.4. That said, you can find the OpenCV 3 specific flags below:
Update the code in the post to use these flags and it should work just fine 🙂
Actually there are even more flags available since 3.0. Two new methods have been added: HISTCMP_CHISQR_ALT and HISTCMP_KL_DIV:
https://docs.opencv.org/3.4/d6/dc7/group__imgproc__hist.html#ga994f53817d621e2e4228fc646342d386
BTW Hellinger and Bhattacharyya are alternative names for the same thing.
Hi Adrian, first of all thanks for another useful tutorial. I am building a photobooth using RPi and Python. And I was hoping to reuse your code to do histogram matching (for some colour based photo filters), would you be able to hint me on what should I do after getting the result from 2 compared histograms ?
Thanks
What is the end goal of applying photo filters? Are you trying to compare how “similar” two photos are? Or take some action based on how similar the images are?
Adrian, the goal is to use a template image and match its histogram to the new image, a perfect example would be Matlab’s imhistmatch() function.
I’m not familiar with MATLAB, so I haven’t used the
imhistmatchfunction before. From what I’ve seen on their documentation page, it looks like it’s performing a color transfer between the images using the CDF of the histograms. I would suggest doing more research in that area. The methods proposed in this blog post are mainly just for comparing the similarity of two images based on their color histograms.Ah, I see. Okay then I will continue with more research. Thank you!
Hello Adrian,
Thanks for your useful tutorial. I am doing my master thesis, descriptors of images have been given to me, and now I am supposed to calculate hellinger distance. But I should do it with C++ and in Qt creator. Maybe do you know source having information like your tutorial but for C++ ?
Unfortunately, I do not have any C++ tutorials. But the same principles in this blog post can be applied to C++ as well. The programming language isn’t important, it’s the computer vision concepts that are being used.
Thanks for the tutorial! However, in OpenCV the flags for the type of histograme comparison have changed. It is now: cv2.HISTCMP_CORREL, etc.
Thanks for sharing Jon. The blog post was intended for OpenCV 2.4; however, as you noted, the flags have changed slightly with OpenCV 3. Please see my reply to “Themba” above for the listing of new flags.
when i text this code in line 34 :
hist = cv2.normalize(hist).flatten() (the other line is same)
i found message error :
TypeError: required argument ‘dst’
but if i changed to :
hist = cv2.normalize(hist,cv2.NORM_MINMAX).flatten() (the other line is same)
the code are running, but the result is different with youre result
please answer 😀
It sounds like you’re Using OpenCV 3. The function signature for
cv2.normalizechanged between OpenCV 2.4 and OpenCV 3. To resolve the issue, simply change the code to:How does
ap.add_argument(“-d”, “–dataset”, required = True,help = “Path to the directory of images”)
this line works what is “-d” & “–dataset”
Hi Samad — if you’re just getting started working with command line arguments, I really suggest that you read this tutorial first.
Can I use it to compare human images more specifically human recognition ?
Histograms typically are used for human recognition. Presuming you mean “face recognition”, you would use Eigenfaces, Fisherfaces, or LBPs for face recognition.
It’s entirely dependent on your dataset and what you’re trying to build. In nearly all situations I recommend started with the chi-squared distance as this will normally give the best results for comparing histograms. However, you should spot-check all distance methods and see which works best for your project.
Did i understand this correctly
Its not possible to use the histogram compare method to check a bunch of images to be similar or identical? You always need a MASTER image and compare all other images with this master image?
Hmm, I’m not sure I understand your question. But you can certainly compare a bunch of histograms for similarity. You could do this via clustering such as the k-means clustering algorithm. But if you intend to build an image search engine you normally have an input image (your “query image”) that is compared to a database of images.
Hi Adrian,
I’ve been trying for hours but I can’t get this line to work.
ap.add_argument(“-d”, “–dataset”, required = True,
help = “Path to the directory of images”)
My images are stored at this location: C:\Python27\Lib\images
So all I need to do is replace dataset with this file path, right? And –d stays as is?
I would suggest you learn more about command line arguments before you continue. You DO NOT have to modify any code. Simply change the command you are executing:
$ python compare.py --dataset C:\Python27\Lib\imagesI calculate the histogram like method#1 but the histogram output has rows=-1,cols=-1? Can you explain this, plz?
I’m not sure why that would be Julian. What version of OpenCV + Python are you using?
Hi Adrian
Thanks
but when I try to execute your code, I get the following error message
File "compare.py", line 37, in hist = cv2.normalize(hist).flatten() TypeError: Required argument 'dst' (pos 2) not foundNote:I have OpenCV3
Please see my comment to “Willy” above. I have addressed this question earlier.
thank yo , I have problem : my pc works with windows system and I edit in compare.py…
Ln 25 should be: for imagePath in glob.glob(args[“dataset”] + “\*.png”):
Ln 28 should be: filename = imagePath[imagePath.rfind(“\\”) + 1:]
then i found message error : line 77 in module ax.imshow(images[“doge.png”])
keyError : ‘doge.png’
please reply me soon !!!!!!!!
I’m not a Windows user, but I think Line 25 should be “\\*” if I’m not mistaken.
thanks
Hey Adrian i’m interested in textured images, so any ideas about the best method to compare similarities and about the threhold that i should take ?
It doesn’t matter if you are comparing color, shape, or texture — what patterns is the type of feature vectors you are producing. If they are histograms, my first suggestion would be the chi-squared distance.
compare.py: error: argument -d/–dataset is required
error?
It sounds like you are forgetting to supply the command line arguments to the script.
how to do that?
You can read more about command line arguments here.
i have the same problems
how to fix that ?
You can fix the error by reading my reply to “napi”. You need to read this tutorial on how to use command line arguments.
Wow! What an excellent article! Exactly what I was looking for.
One thing that I find puzzling is that the perfect score for the Histogram Intersection was 2.67. I totally expected that to be 3.00 (or maybe 1.00). My understanding of the histogram normalization function is that it converts the absolute bins counts to a relative frequency distribution so that all of the bin frequencies for a given histogram together add up to 1.00.
Then during the Histogram Intersection, each bin is compared to its corresponding bin in the compared-to histogram with then minimum of the two being accumulated. Since they should be identical the total for each histogram comparison should be 1.00. I am guessing that there are three histograms, one for each channel, which then should produce a score of 3.00.
Why would it be 2.67?
I just wanted you to make small updates for OpenCV 3.2 because I almost died trying to find this in the documentation.
The methods are now, cv2.HISTCMP_CORREL and the like
Normalization is now with two compulsory arguments, hist = cv2.normalize(hist, hist).flatten()
Thanks for sharing Suhas!
sir i want to check a object present in an image or not….i tried a lot but i didn’t get any solution…can u help me with that
It really depends on the type of object you’re trying to detect. If you can share more information about the object you’re trying to detect, I can attempt to point you in the right direction. Otherwise, you should consider training a HOG + Linear SVM detector. I cover the implementation of the HOG + Linear SVM detector inside the PyImageSearch Gurus course.
Hai,
The above 3 methods are not reliable for signatures. All 3 giving bad results.
Can anyone suggest me for comparing histograms other than above 3 methods
Are you referring to handwritten signatures? You wouldn’t use histograms to compare handwritten signatures as histograms throw away all spatial information.
Nice concept! Thank you for the tutorial.
I’m using #1 to find similar pic from one pic compare to a set of pics)
I don’t need to display results visually, so the code after
results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
not used.I just need to know the most similar one with its filename (“print results” is enough), and it works fine (compared to small amount images).
Here met the problem:
When compared to big set of files (1000+ image), the memory consumed by python.exe grew rapidly until about 2gig, exception raised.
After some googling, it seems opencv 3.0.0 has memory leak issue, but fixed already.
I’ve tried:
python2.7 + cv2(from SF opencv-2.4.13.exe)
python3.4 + cv2(from pypi opencv_python-3.2.0.7)
Both worked but failed with issue stated upon.
So is there a way to reduce or release memory usage in for loop?
Tried “Del image”, no way.
I’m unaware of any issues related to a memory leak. Can you profile your code and determine if there is a Python variable that is eating up memory? Or if this is internally an OpenCV issue?
The constant names have changed: https://stackoverflow.com/questions/40451706/how-to-use-comparehist-function-opencv
I really enjoyed this. I am getting an issue when I run the code of: Usage:
FileName [-h] -d DATASET
FileName: error: argument -d/–dataset is required
I am using Python 2.7, is that the base of the issue? Thanks.
Please see my reply to “Samad” above.
Hi, Adrian, thanks for the great tutorial!
I am, however, unsure if it is correct to use `flatten()` to transform a 3D histogram into a 1D histogram before comparing them.
I am working on an algorithm which segments an image using SLIC (thanks again for the SLIC tutorial!) and calculates the histogram for each superpixel. After that, I compare each superpixel to all its neighbors to see if they are similar — if they are similar, I merge them together. However, by using `flatten()` on two similar superpixels results on two very different histograms!
In my understanding, the `flatten()` method will make “values” that are close in the 3D space sparse in 1D space. Consider the following code:
>>> a=np.zeros((4,4,4))
>>> b=np.zeros((4,4,4))
>>> a[3,3,3] = 1
>>> b[2,3,3] = 1
>>> a0 = a.flatten()
>>> b0 = b.flatten()
>>> np.argmax(a0)
63
>>> np.argmax(b0)
47
So, [3,3,3] and [2,3,3] are very close on to each other (euclidean distance of 1), but are placed really far away (in positions 63 and 47) by the `flatten()` method.
Thus, I think it is not appropriate to use this approach to compare 3D histograms, but I have no other idea than to revert to calculate 1D histogram per channel and comparing them, which I would like to avoid. What is your opinion on this?
Thanks a lot and keep the amazing work!
Hey Silas — there are many, many different methods to compare histograms, most of which rely on a distance function/similarity metric of some sort. Typically we would take the 3D histogram, flatten it out, and then compare — the “adjacency” of the bins here doesn’t really matter (unless you wanted to apply earth movers distance) as long as the flattening is consistent. The distance metric will then compare each individual bin.
Hi, Adrian, thanks for the reply. I agree with you that in this case the adjacency really does not matter, since the image has enough information. However, I think that is not the case for superpixels, which have limited information (i.e. low pixel count). I think that training a classifier might provide better results. Thank you very much for your help! =)
Hey Adrian, Amazing experiment with comparing histograms, I wonder how can we match histograms of an image with respect to a reference image so that we can Normalize other images in the dataset with respect to the same reference image. Is there a method for it or how can it be done, can we implement something like curve fitting on cumulative histogram so that we can match both ??
You mean something like this?
Hi, Adrian, thanks for the tutorial!
But i have a problem when i try to run the code :
results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
^
IndentationError: unindent does not match any outer indentation level
Can you help me please ?
It sounds like you accidentally introduced an indentation error when copying and pasting the code. Make sure you use the “Downloads” section of this post to download the source code.
It works. Thank you Adrian.
hey Adrian i am doing my final year project on the topic face recognition and till now i have retrieved the faces using the Viola Jones algorithm and saved them in a folder with unique ID now i need to send an image as input and search whether it is present or not and if found just return the result…and i am not able to process this comparsion part…please help me out..i am in serious trouble
Congrats on doing your final year project. Histograms are actually not the best method for facial recognition. Popular algorithms used are normally Eigenfaces, Fisherfaces, LBPs for face recognition, and deep learning embeddings. I have a tutorial on LBPs to help you get started. Otherwise, I cover face recognition in detail inside the PyImageSearch Gurus course.
Sir it shows an error saying Key error : doge.png
hi
i download the file
what line of code i should write to run the code
it show me this error
usage: compare.py [-h] -d DATASET
compare.py: error: argument -d/–dataset is required
You need to execute the script from your terminal and supply the command line arguments. If you are new to command line arguments, that’s okay, but you need to read up on them first before you try to execute the script.
You just need to open up a terminal, navigate to wherever you downloaded the code, and execute the Python script, ensuring you supply the command line arguments as I do in the post.
pls
someone can show me how to run this code in Windows
I tried
>>python compare.py –dataset C:\Adm\Desktop\compare-histograms-opencv\images\Lib\images
SyntaxError: invalid syntax
>>python compare.py –dataset images
SyntaxError: invalid syntax
Don’t execute the script via the Python shell. Execute it via the terminal. You do not need to launch a Python shell.
Hi, adrian.
Do u think it is possible to use these histogram comparison methods to measure similarity between two hog descriptors ?
Absolutely. A HOG descriptor is simply a sequence of histograms appended to each other.
Hello Adrain.
Thanks a lot for this tutorial.
I would like also to take this opportunity to ask you something :
I have two dataset of images ( 2 folders “F1&F2” ), i want to make a cluster for each dataset according to the similarity of the images. After getting those 2 clusters, i want to compare them, get their similarity (similarity clustering).
How can i do that efficiently ? Can you please advise me a good method to make it ?
Thank you very much for your help, I’m looking forward to hearing from you.
First you need to consider how you are quantifying the contents of the images. Are you using color histograms? Texture, such as Haralick texture? Local Binary Patterns?
I would suggest taking a look at the PyImageSearch Gurus course where I have over 30+ lessons on feature extraction and even demonstrate how to cluster images based on their visual similarity.
Hi Adrian,
I use color histogram. According to the color histogram i make each clusters, but after that i don’t know how to compare those two clusters efficiently (How to perform the similarity clustering), that is my problem. Thanks a lot for helping me.
I will be waiting for your answer.
I would suggest you:
1. Extract a color histogram from each image
2. Apply k-means to cluster the histograms
This algorithm with naturally cluster images together based on the similarity of their feature vectors. When using k-means we normally use the euclidean distance as the distance metric.
Hi adrian.
But if i use k-means is it possible to specify the names of the images into the clusters.?
What should i get as a result ? How the clusters are suppose to looks like ?
Because i saw two of your tutorial about k-means : “OpenCV and Python K-Means Color Clustering” and ” Color Quantization with OpenCV using K-Means Clustering” and the representation of k-means is different (The way you used it). And in my case i don’t know exactly how to apply it.
Thanks a lot for helping me.
Can you be a bit more specific but what you mean by “specify the names of the images into the clusters”? I typically grab the image paths, sort them, extract features, cluster, and then use the indexes of the data points (since they were sorted by image paths originally) to map them back to the original image paths. This process is covered in detail inside the PyImageSearch Gurus course.
Why do you run default normalize on the histograms? This results in sum of histogram value squares to be 1, which distorts the actual histogram shape. I imagine, you’d want to normalize with respect to the L1 norm instead.
Hi Sir, I need guidance on How to compare x-ray images for presence / absence of an object. Will it be good to compare Histograms. In fact I want to classify xray images as PASS/FAIL based on presence/absence of an object in the image.
Hi sir, I need to sort images of similar types. Like I have some set of images which I had sorted manually with count of 500 images, and even I have thousands of images which are of different types and I need only images similar to the images which I have sorted before. I mean I need only images of that type so what should I do?. I am waiting for your answer.
The exact algorithm you would use here is highly dependent on the contents of the images. How are you trying to “sort” your images? What constitutes “similarity”? Similar color? Texture? Some other aspect?
Hello Mr. Adrian.
I’m working on a facial recognition project. My goal is to be able to tell the difference between a face detected directly on a physical person and a face detected on a photo using the textures. So I want to make sure that this is really the user in person and not the picture of his face. I need your recommendations to know what are the different methods to use.
Thank you
What you’re referring to is called “liveliness detection”. I don’t have any tutorials on liveliness detection but I hope to write a guide on it soon!
I get a keyerror in 61 d = cv2.compareHist(index[“doge.png”], hist, method)
doge.png I work in opencv 3.x
I modified 34 hist = cv2.normalize(hist).flatten() to hist = cv2.normalize(hist,hist).flatten()
For anyone trying to get the original implementation to work. I have a gist that I got to work for Python 3.6.6 and cv2 version 3.4.3.
https://gist.github.com/youngsoul/b5014604538b8fddc5c1bc8761fe0efc
Hi Adrian, I’m using LBP to acquire a histogram of the edges of part of a persons face. Which metric would be best suited in order to compare these histograms to the histogram of a CGI avatar? (I am comparing the levels of texture in CGI avatars and human faces to derive a measure of ‘realism’ for the avatars corresponding to how closely the avatars skin resembles that of a human)
I would definitely test different metrics but for histogram comparisons the chi-squared metric often works very well.
Would you say LBP is the most suitable for comparison of skin textures? I can’t find many journals stating any particular algorithm that is best for this purpose, I guess I’m also not sure what I’m looking for in the skin texture itself, just a broad overall comparison
What do you mean by “skin texture”? What are you trying to build?
always a great tutorial in this universe 🙂
I want to know, can I use this logic into the attribute detection?
attributes of the furniture like the chair color and the design on a char
or a sofa color and the sofa design and the sofa material use.
if no then please give me your suggestion to accomplish this thing.
Thank you
I would combine more than just color. I would also use texture features like LBP or Haralick. If you’re serious about building the project I would recommend going through the PyImageSearch Gurus course which will help you learn Computer Vision.