So what type of shape descriptors does OpenCV provide?
The most notable are Hu Moments which are can be used to describe, characterize, and quantify the shape of an object in an image.
Hu Moments are normally extracted from the silhouette or outline of an object in an image. By describing the silhouette or outline of an object, we are able to extract a shape feature vector (i.e. a list of numbers) to represent the shape of the object.
We can then compare two feature vectors using a similarity metric or distance function to determine how “similar” the shapes are.
In this blog post I’ll show you how to extract the Hu Moments shape descriptor using Python and OpenCV.
OpenCV and Python versions:
This example will run on Python 2.7/Python 3.4+ and OpenCV 2.4.X/OpenCV 3.0+.
OpenCV Shape Descriptor: Hu Moments Example
As I mentioned, Hu Moments are used to characterize the outline or “silhouette” of an object in an image.
Normally, we obtain this shape after applying some sort of segmentation (i.e. setting the background pixels to black and the foreground pixels to white). Thresholding is the most common approach to obtain our segmentation.
After we have performed thresholding we have the silhouette of the object in the image.
We could also find the contours of the silhouette and draw them, thus creating an outline of the object.
Regardless of which method we choose, we can still apply the Hu Moments shape descriptors provided that we obtain consistent representations across all images.
For example, it wouldn’t make sense to extract Hu Moments shape features from the silhouette of one set of images and then extract Hu Moments shape descriptors from the outline of another set of images if our intention is to compare the shape features in some way.
Anyway, let’s get started and extract our OpenCV shape descriptors.
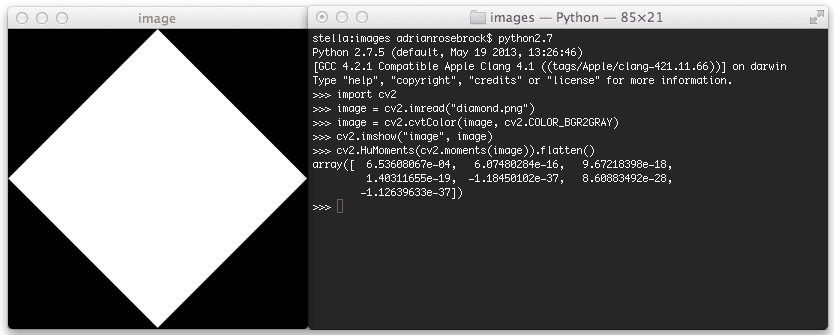
First, we’ll need an image, diamond.png:

This image is of a diamond, where the black pixels correspond to the background of the image and the white pixels correspond to the foreground. This is an example of a silhouette of an object in an image. If we had just the border of the diamond, it would be the outline of the object.
Regardless, it is important to note that our Hu Moments shape descriptor will only be computed over the white pixels.
Now, let’s extract our shape descriptors:
>>> import cv2
>>> image = cv2.imread("diamond.png")
>>> image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
The first thing we need to do is import our cv2 package which provides us with our OpenCV bindings.
Then, we load our diamond image off disk using the cv2.imread method and convert it to grayscale.
We convert our image to grayscale because Hu Moments requires a single channel image — the shape quantification is only carried out among the white pixels.
From here, we can compute our Hu Moments shape descriptor using OpenCV:
>>> cv2.HuMoments(cv2.moments(image)).flatten()
array([ 6.53608067e-04, 6.07480284e-16, 9.67218398e-18,
1.40311655e-19, -1.18450102e-37, 8.60883492e-28,
-1.12639633e-37])
In order to compute our Hu Moments, we first need to compute the original 24 moments associated with the image using cv2.moments.
From there, we pass these moments into cv2.HuMoments, which calculates Hu’s seven invariant moments.
Finally, we flatten our array to form our shape feature vector.
This feature vector can be used to quantify and represent the shape of an object in an image.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post I showed you how to use the Hu Moments OpenCV shape descriptor.
In future blog posts I will show you how to compare Hu Moments feature vectors for similarity.
Be sure to enter your email address in the form below to be informed when I post new awesome content!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

