
This past weekend I’ve been really sick with the flu. I haven’t done much besides lay on my couch, sip chicken noodle soup from a coffee mug, and marathon gaming sessions of Call of Duty.

It’s honestly been years since I’ve spent a weekend relentlessly playing Call of Duty. Getting online and playing endless rounds of Team Deathmatch and Domination brought back some great memories of my college roommate and myself gaming all night during my undergraduate years.
Seriously, back in college I was a Call of Duty fanatic — I even had Call of Duty posters hanging on the walls. And I had played all the games: the original Call of Duty games set during World War II; the Modern Warfare series (my favorite); even the Black Ops games. And while I was too sick to get myself off the couch this weekend, I could no-scope my through a game of Domination without a problem.
But by the end of Sunday afternoon I was starting to feel a little burnt out on my gaming session. Apparently, there is a only a finite amount of gaming I can do in a single sitting now that I’m not in college anymore.
Anyway, I reached over to my laptop and started surfing the web. After a few minutes of browsing Facebook, I came across a template matching tutorial I did over at Machine Learning Mastery. In this article, I detailed how to play a game of Where’s Waldo? (or Where’s Wally?, for the international readers) using computer vision.
While this tutorial was pretty fun (albeit, very introductory), I realized there was an easy extension to make template matching more robust that needed to be covered.
You see, there are times when using keypoint detectors, local invariant descriptors (such as SIFT, SURF, FREAK, etc.), and keypoint matching with RANSAC or LMEDs is simply overkill — and you’re better off with a more simplistic approach.
In this blog post I’ll detail how you can extend template matching to be multi-scale and work with images where the template and the input image are not the same size.
OpenCV and Python versions:
This example will run on Python 2.7/Python 3.4+ and OpenCV 2.4.X.
Multi-scale Template Matching using Python and OpenCV
To start this tutorial off, let’s first understand why the standard approach to template matching using cv2.matchTemplate is not very robust.
Take a look at the example image below:

In the example image above, we have the Call of Duty logo on the left. And on the right, we have the image that we want to detect the Call of Duty logo in.
Note: Both the template and input images were matched on the edge map representations. The image on the right is simply the output of the operation after attempting to find the template using the edge map of both images.
However, when we try to apply template matching using the cv2.matchTemplate function, we are left with a false match — this is because the size of the logo image on the left is substantially smaller than the Call of Duty logo on the game cover on the right.
Given that the dimensions of the Call of Duty template does not match the dimensions of the Call of Duty logo on the game cover, we are left with a false detection.
So what do we do now?
Give up? Start detecting keypoints? Extracting local invariant descriptors? And applying keypoint matching?
Not so fast.
While detecting keypoints, extracting local invariant descriptors, and matching keypoints would certainly work, it’s absolutely overkill for this problem.
In fact, we can get away with a much easier solution — and with substantially less code.
The cv2.matchTemplate Trick
So as I hinted at in the beginning of this post, just because the dimensions of your template do not match the dimensions of the region in the image you want to match, does not mean that you cannot apply template matching.
In this case, all you need to do is apply a little trick:
- Loop over the input image at multiple scales (i.e. make the input image progressively smaller and smaller).
- Apply template matching using
cv2.matchTemplateand keep track of the match with the largest correlation coefficient (along with the x, y-coordinates of the region with the largest correlation coefficient). - After looping over all scales, take the region with the largest correlation coefficient and use that as your “matched” region.
As I said, this trick is dead simple — but in certain situations this approach can save you from writing a lot of extra code and dealing with more fancy techniques to matching objects in images.
Note: By definition template matching is translation invariant. The extension we are proposing now can help make it more robust to changes in scaling (i.e. size). But template matching is not ideal if you are trying to match rotated objects or objects that exhibit non-affine transformations. If you are concerned with these types of transformations you are better of jumping right to keypoint matching.
Anyway, enough with the talking. Let’s jump into some code. Open up your favorite editor, create a new file, name it match.py , and let’s get started:
# import the necessary packages
import numpy as np
import argparse
import imutils
import glob
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--template", required=True, help="Path to template image")
ap.add_argument("-i", "--images", required=True,
help="Path to images where template will be matched")
ap.add_argument("-v", "--visualize",
help="Flag indicating whether or not to visualize each iteration")
args = vars(ap.parse_args())
# load the image image, convert it to grayscale, and detect edges
template = cv2.imread(args["template"])
template = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
template = cv2.Canny(template, 50, 200)
(tH, tW) = template.shape[:2]
cv2.imshow("Template", template)
The first thing we’ll do is import the packages we’ll need. We’ll use NumPy for numerical processing, argparse for parsing command line arguments, imutils for some image processing convenience functions (included with the .zip of the code for this post), glob for grabbing the paths to our input images, and cv2 for our OpenCV bindings.
We then parse our arguments on Lines 8-15. We’ll need three switches: --template , which is the path to the template we want to match in our image (i.e. the Call of Duty logo), --images , the path to the directory including the images that contain the Call of Duty logo that we want to find, and an optional --visualize argument which lets us visualize the template matching search across multiple scales.
Next up, it’s time to load our template off disk on Line 18. We’ll also convert it to grayscale on Line 19 and detect edges on Line 20. As you’ll see later in this post, applying template matching using edges rather than the raw image gives us a substantial boost in accuracy for template matching.
The reason for this is because the Call of Duty logo is rigid and well defined — and as we’ll see later on in this post, it allows us to discard the color and styling of the logo and instead focus solely on the outline. Doing this gives us a slightly more robust approach that we would not have otherwise.
Anyway, after applying edge detection our template should look like this:
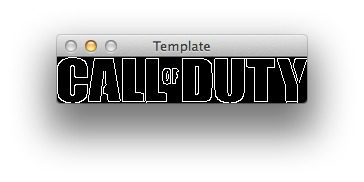
Now, let’s work on the multi-scale trick:
# loop over the images to find the template in for imagePath in glob.glob(args["images"] + "/*.jpg"): # load the image, convert it to grayscale, and initialize the # bookkeeping variable to keep track of the matched region image = cv2.imread(imagePath) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) found = None # loop over the scales of the image for scale in np.linspace(0.2, 1.0, 20)[::-1]: # resize the image according to the scale, and keep track # of the ratio of the resizing resized = imutils.resize(gray, width = int(gray.shape[1] * scale)) r = gray.shape[1] / float(resized.shape[1]) # if the resized image is smaller than the template, then break # from the loop if resized.shape[0] < tH or resized.shape[1] < tW: break
We start looping over our input images on Line 25. We then load the image off disk, convert it to grayscale, and initialize a bookkeeping variable found to keep track of the region and scale of the image with the best match.
From there we start looping over the multiple scales of the image on Line 33 using the np.linspace function. This function accepts three arguments, the starting value, the ending value, and the number of equal chunk slices in between. In this example, we’ll start from 100% of the original size of the image and work our way down to 20% of the original size in 20 equally sized percent chunks.
We then resize the image image according to the current scale on Line 36 and compute the ratio of the old width to the new width — as you’ll see later, it’s important that we keep track of this ratio.
On Line 41 we make a check to ensure that the input image is larger than our template matching. If the template is larger, then our cv2.matchTemplate call will throw an error, so we just break from the loop if this is the case.
At this point we can apply template matching to our resized image:
# detect edges in the resized, grayscale image and apply template
# matching to find the template in the image
edged = cv2.Canny(resized, 50, 200)
result = cv2.matchTemplate(edged, template, cv2.TM_CCOEFF)
(_, maxVal, _, maxLoc) = cv2.minMaxLoc(result)
# check to see if the iteration should be visualized
if args.get("visualize", False):
# draw a bounding box around the detected region
clone = np.dstack([edged, edged, edged])
cv2.rectangle(clone, (maxLoc[0], maxLoc[1]),
(maxLoc[0] + tW, maxLoc[1] + tH), (0, 0, 255), 2)
cv2.imshow("Visualize", clone)
cv2.waitKey(0)
# if we have found a new maximum correlation value, then update
# the bookkeeping variable
if found is None or maxVal > found[0]:
found = (maxVal, maxLoc, r)
# unpack the bookkeeping variable and compute the (x, y) coordinates
# of the bounding box based on the resized ratio
(_, maxLoc, r) = found
(startX, startY) = (int(maxLoc[0] * r), int(maxLoc[1] * r))
(endX, endY) = (int((maxLoc[0] + tW) * r), int((maxLoc[1] + tH) * r))
# draw a bounding box around the detected result and display the image
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
On Line 46 we compute the Canny edge representation of the image, using the exact same parameters as in the template image.
We then apply template matching using cv2.matchTemplate on Line 47. The cv2.matchTemplate function takes three arguments: the input image, the template we want to find in the input image, and the template matching method. In this case, we supply the cv2.TM_CCOEFF flag, indicating we are using the correlation coefficient to match templates.
The cv2.minMaxLoc function on Line 48 takes our correlation result and returns a 4-tuple which includes the minimum correlation value, the maximum correlation value, the (x, y)-coordinate of the minimum value, and the (x, y)-coordinate of the maximum value, respectively. We are only interested in the maximum value and (x, y)-coordinate so we keep the maximums and discard the minimums.
Line 51-57 handle visualizing the multi-scale template match. This allows us to inspect the regions of the image that are getting matched at each iteration of the scale.
From there, we update our bookkeeping variable found on Lines 61 and 62 to keep track of the maximum correlation value found thus far, the (x, y)-coordinate of the maximum value, along with the ratio of the original image width to the current, resized image width.
At this point all the hard work is done.
After we have looped over all scales of the image, we unpack our bookkeeping variable on Line 66, and then compute our starting and ending (x, y)-coordinates of our bounding box on Line 67 and 68. Special care is taken to multiply the coordinates of the bounding box by the ratio on Line 37 to ensure that the coordinates match the original dimensions of the input image.
Finally, we draw our bounding box and display it to our screen on Lines 71-73.
Multi-scale Template Matching Results
Don’t take my word for it that this method works! Let’s look at some examples.
Open up your terminal and execute the following command:
$ python match.py --template cod_logo.png --images images
Your results should look like this:

As you can see, our method successfully found the Call of Duty logo, unlike the the basic template matching in Figure 1 which failed to find the logo.

We then apply multi-scale template matching to another Call of Duty game cover — and again we have found the Call of Duty logo, despite the template being substantially smaller than the input image.
Also, take a second a examine how different the style and color of the Call of Duty logos are in Figure 3 and Figure 4. Had we used the RGB or grayscale template we would have not been able to find these logos in the input images. But by applying template matching to the edge map representation rather than the original RGB or grayscale representation, we were able to obtain slightly more robust results.
Let’s try another image:

Once again, our method was able to find the logo in the input image!
The same is true for Figure 6 below:

And now for my favorite Call of Duty, Modern Warfare 3:
Once again, our multi-scale approach was able to successfully find the template in the input image!
And what’s even more impressive is that there is a very large amount of noise in the MW3 game cover above — the artists of the cover used white space to form the upper-right corner of the “Y” and the lower-left corner of the “C”, hence no edge will be detected there. Still, our method is able to find the logo in the image.
Visualizing the Match
In the above section we looked at the output of the match. But let’s take a second to dive into a visualization of how this algorithm actually works.
Open up your terminal and execute the following command:
$ python match.py --template cod_logo.png --images images --visualize 1
You’ll see an animation similar to the following:
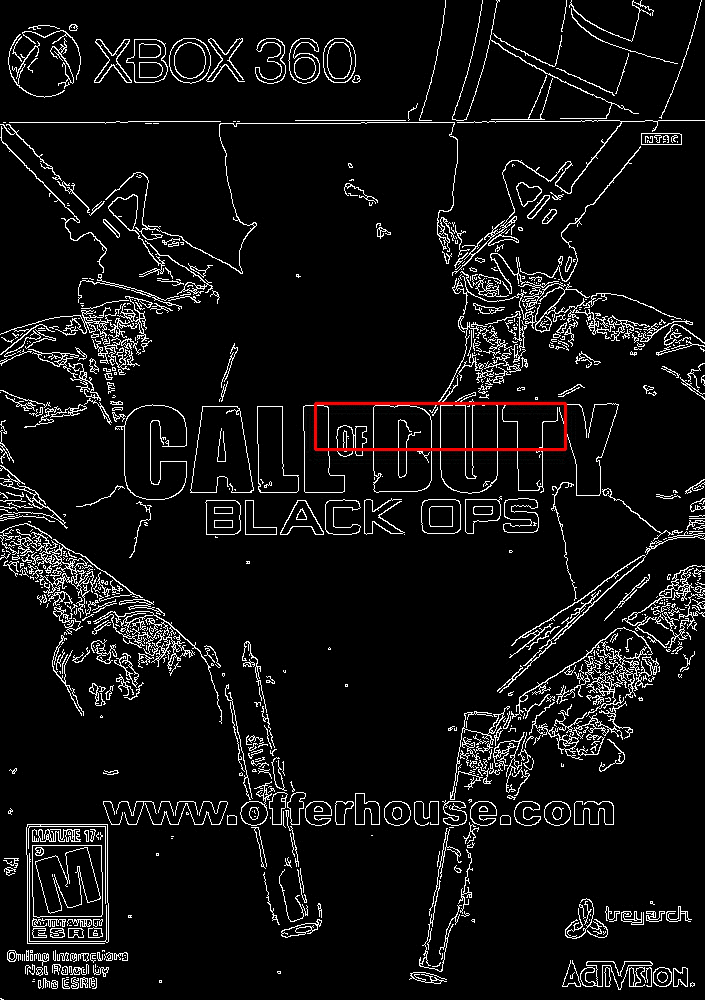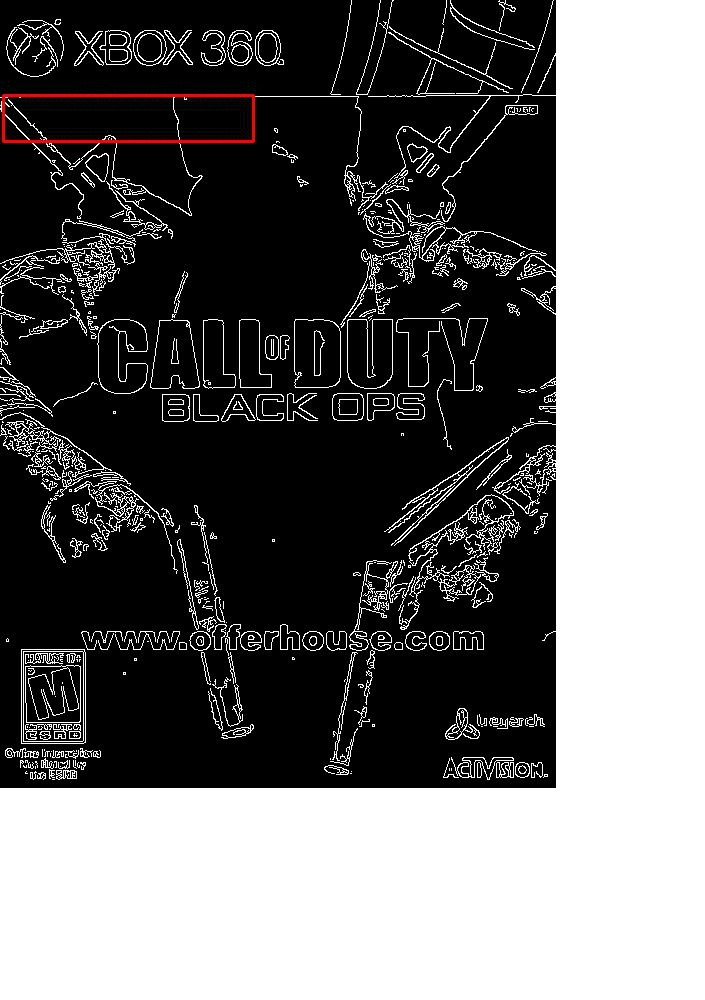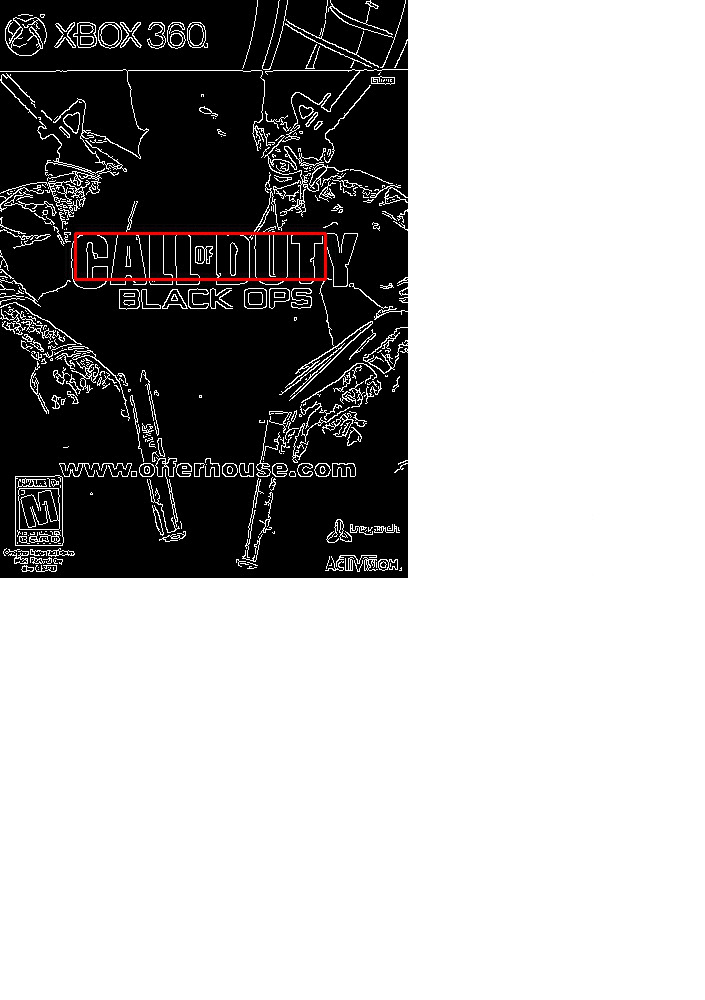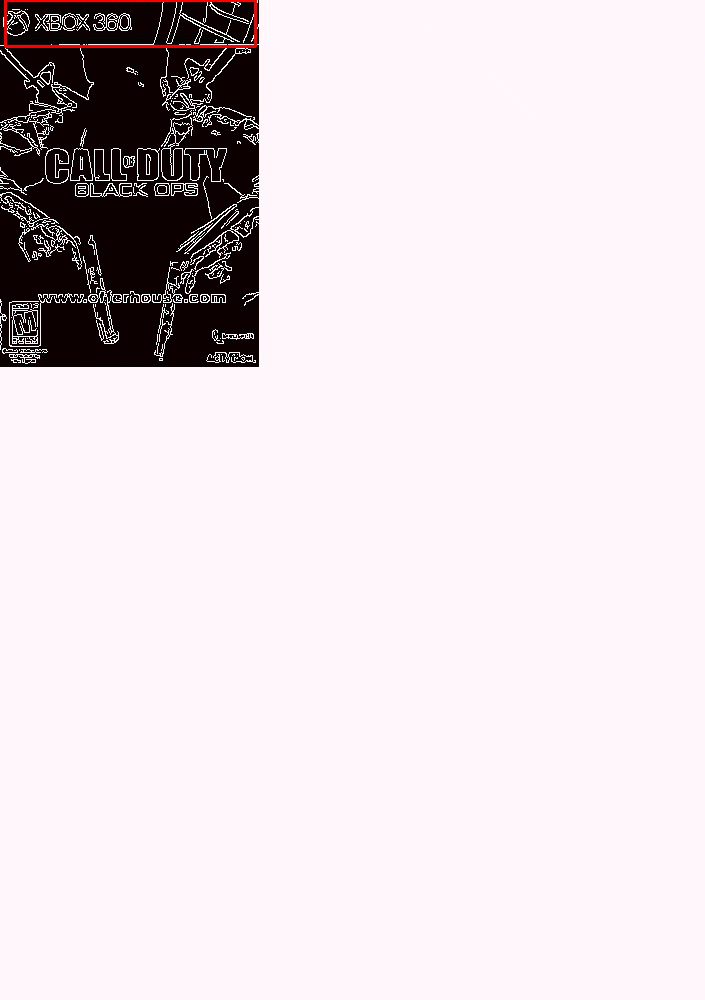
At each iteration, our image is resized and the Canny edge map computed.
We then apply template matching and find the (x, y)-coordinates of the image with the largest correlation coefficient.
Lastly, we store these values in a bookkeeping variable.
At the end of the algorithm we find the (x, y)-coordinates of the region with the largest correlation coefficient response across all scales and then draw our bounding box, as seen below:
For completeness, here is another example of visualizing our multi-scale template matching using OpenCV and Python:

Limitations and Drawbacks
Of course, applying simple template matching, even multi-scale template matching has some significant limitations and drawbacks.
While we can handle variations in translation and scaling, our approach will not be robust to changes in rotation or non-affine transformations.
If we are concerned about rotation on non-affine transformations we are better off taking the time to detect keypoints, extract local invariant descriptors, and apply keypoint matching.
But in the case where our templates are (1) fairly rigid and well-defined via an edge map and (2) we are only concerned with translation and scaling, then multi-scale template matching can provide us with very good results with little effort.
Lastly, it’s important to keep in mind that template matching does not do a good job of telling us if an object does not appear in an image. Sure, we could set thresholds on the correlation coefficient, but in practice this is not reliable and robust. If you are looking for a more robust approach, you’ll have to explore keypoint matching.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we discovered how to make standard template matching more robust by extending it to work with multiple scales.
We also discovered that in cases where our template image is rigid and well-formed, that utilizing an edge map rather than the RGB or grayscale representation can yield better results when applying template matching.
Our method to multi-scale template matching works well if we are only concerned with translation and scaling; however, this method will not be as robust in the presence of rotation and non-affine transformations. If our template or input image exhibits these types of transformations we are better off applying keypoint detection, local invariant descriptors, and keypoint matching.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

