
It’s too damn cold up in Connecticut — so cold that I had to throw in the towel and escape for a bit.
Last week I took a weekend trip down to Orlando, FL just to escape. And while the weather wasn’t perfect (mid-60 degrees Fahrenheit, cloudy, and spotty rain, as you can see from the photo above), it was exactly 60 degrees warmer than it is in Connecticut — and that’s all that mattered to me.
While I didn’t make it to Animal Kingdom or partake in any Disney adventure rides, I did enjoy walking Downtown Disney and having drinks at each of the countries in Epcot.
Sidebar: Perhaps I’m biased since I’m German, but German red wines are perhaps some of the most under-appreciated wines there are. Imagine having the full-bodied taste of a Chianti, but slightly less acidic. Perfection. If you’re ever in Epcot, be sure to check out the German wine tasting.
Anyway, as I boarded the plane to fly back from the warm Florida paradise to the Connecticut tundra, I started thinking about what the next blog post on PyImageSearch was going to be.
Really, it should not have been that long (or hard) of an exercise, but it was a 5:27am flight, I was still half asleep, and I’m pretty sure I still had a bit of German red wine in my system.
After a quick cup of (terrible) airplane coffee, I decided on a 2-part blog post:
-
Part #1: Image Pyramids with Python and OpenCV.
- Part #2: Sliding Windows for Image Classification with Python and OpenCV.
You see, a few months ago I wrote a blog post on utilizing the Histogram of Oriented Gradients image descriptor and a Linear SVM to detect objects in images. This 6-step framework can be used to easily train object classification models.
A critical aspect of this 6-step framework involves image pyramids and sliding windows.
Today we are going to review two ways to create image pyramids using Python, OpenCV, and sickit-image. And next week we’ll discover the simple trick to create highly efficient sliding windows.
Utilizing these two posts we can start to glue together the pieces of our HOG + Linear SVM framework so you can build object classifiers of your own!
Read on to learn more…
What are image pyramids?
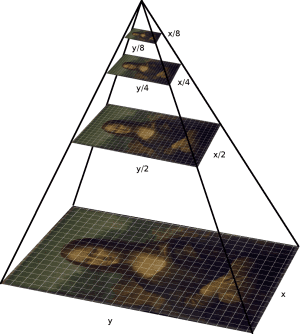
An “image pyramid” is a multi-scale representation of an image.
Utilizing an image pyramid allows us to find objects in images at different scales of an image. And when combined with a sliding window we can find objects in images in various locations.
At the bottom of the pyramid we have the original image at its original size (in terms of width and height). And at each subsequent layer, the image is resized (subsampled) and optionally smoothed (usually via Gaussian blurring).
The image is progressively subsampled until some stopping criterion is met, which is normally a minimum size has been reached and no further subsampling needs to take place.
Method #1: Image Pyramids with Python and OpenCV
The first method we’ll explore to construct image pyramids will utilize Python + OpenCV.
In fact, this is the exact same image pyramid implementation that I utilize in my own projects!
Let’s go ahead and get this example started. Create a new file, name it helpers.py , and insert the following code:
# import the necessary packages import imutils def pyramid(image, scale=1.5, minSize=(30, 30)): # yield the original image yield image # keep looping over the pyramid while True: # compute the new dimensions of the image and resize it w = int(image.shape[1] / scale) image = imutils.resize(image, width=w) # if the resized image does not meet the supplied minimum # size, then stop constructing the pyramid if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]: break # yield the next image in the pyramid yield image
We start by importing the imutils package which contains a handful of image processing convenience functions that are commonly used such as resizing, rotating, translating, etc. You can read more about the imutils package here. You can also grab it off my GitHub. The package is also pip-installable:
$ pip install imutils
Next up, we define our pyramid function on Line 4. This function takes two arguments. The first argument is the scale , which controls by how much the image is resized at each layer. A small scale yields more layers in the pyramid. And a larger scale yields less layers.
Secondly, we define the minSize , which is the minimum required width and height of the layer. If an image in the pyramid falls below this minSize , we stop constructing the image pyramid.
Line 6 yields the original image in the pyramid (the bottom layer).
From there, we start looping over the image pyramid on Line 9.
Lines 11 and 12 handle computing the size of the image in the next layer of the pyramid (while preserving the aspect ratio). This scale is controlled by the scale factor.
On Lines 16 and 17 we make a check to ensure that the image meets the minSize requirements. If it does not, we break from the loop.
Finally, Line 20 yields our resized image.
But before we get into examples of using our image pyramid, let’s quickly review the second method.
Method #2: Image pyramids with Python + scikit-image
The second method to image pyramid construction utilizes Python and scikit-image. The scikit-image library already has a built-in method for constructing image pyramids called pyramid_gaussian , which you can read more about here.
Here’s an example on how to use the pyramid_gaussian function in scikit-image:
# METHOD #2: Resizing + Gaussian smoothing.
for (i, resized) in enumerate(pyramid_gaussian(image, downscale=2)):
# if the image is too small, break from the loop
if resized.shape[0] < 30 or resized.shape[1] < 30:
break
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
Similar to the example above, we simply loop over the image pyramid and make a check to ensure that the image has a sufficient minimum size. Here we specify downscale=2 to indicate that we are halving the size of the image at each layer of the pyramid.
Image pyramids in action
Now that we have our two methods defined, let’s create a driver script to execute our code. Create a new file, name it pyramid.py , and let’s get to work:
# import the necessary packages
from pyimagesearch.helpers import pyramid
from skimage.transform import pyramid_gaussian
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size")
args = vars(ap.parse_args())
# load the image
image = cv2.imread(args["image"])
# METHOD #1: No smooth, just scaling.
# loop over the image pyramid
for (i, resized) in enumerate(pyramid(image, scale=args["scale"])):
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
# close all windows
cv2.destroyAllWindows()
# METHOD #2: Resizing + Gaussian smoothing.
for (i, resized) in enumerate(pyramid_gaussian(image, downscale=2)):
# if the image is too small, break from the loop
if resized.shape[0] < 30 or resized.shape[1] < 30:
break
# show the resized image
cv2.imshow("Layer {}".format(i + 1), resized)
cv2.waitKey(0)
We’ll start by importing our required packages. I put my personal pyramid function in a helpers sub-module of pyimagesearch for organizational purposes.
You can download the code at the bottom of this blog post for my project files and directory structure.
We then import the scikit-image pyramid_gaussian function, argparse for parsing command line arguments, and cv2 for our OpenCV bindings.
Next up, we need to parse some command line arguments on Lines 9-11. Our script requires only two switches, --image , which is the path to the image we are going to construct an image pyramid for, and --scale , which is the scale factor that controls how the image will be resized in the pyramid.
Line 14 loads then our image from disk.
We can start utilize our image pyramid Method #1 (my personal method) on Lines 18-21 where we simply loop over each layer of the pyramid and display it on screen.
Then from Lines 27-34 we utilize the scikit-image method (Method #2) for image pyramid construction.
To see our script in action, open up a terminal, change directory to where your code lives, and execute the following command:
$ python pyramid.py --image images/adrian_florida.jpg --scale 1.5
If all goes well, you should see results similar to this:
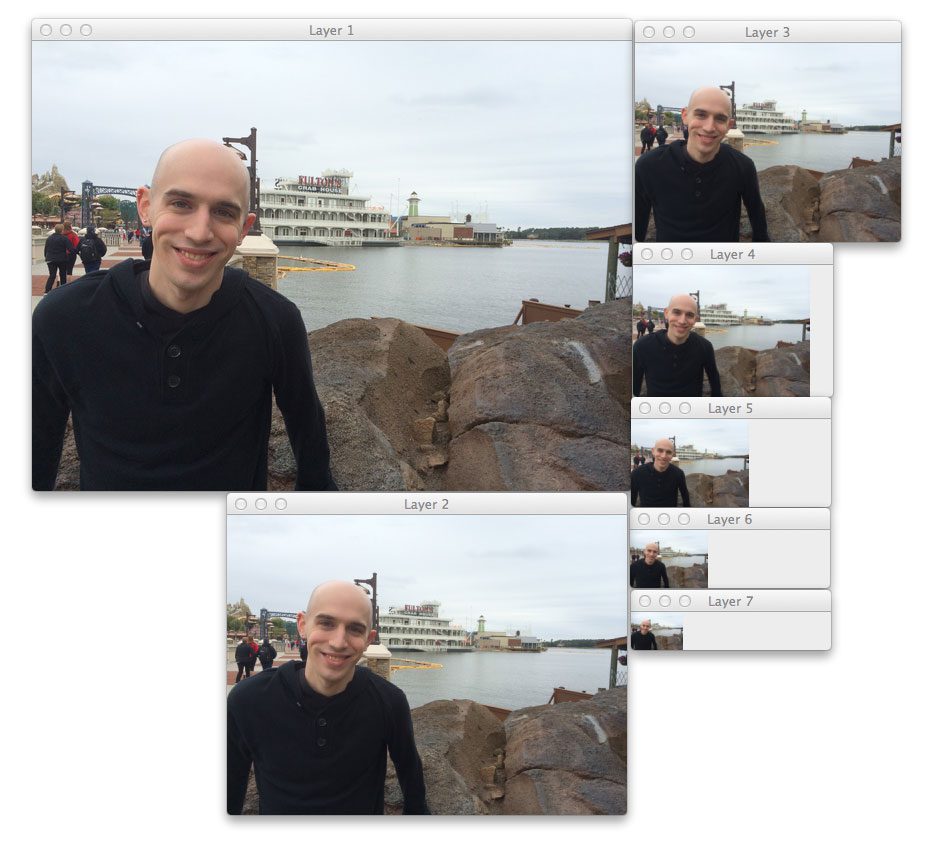
Here we can see that 7 layers have been generated for the image.
And similarly for the scikit-image method:
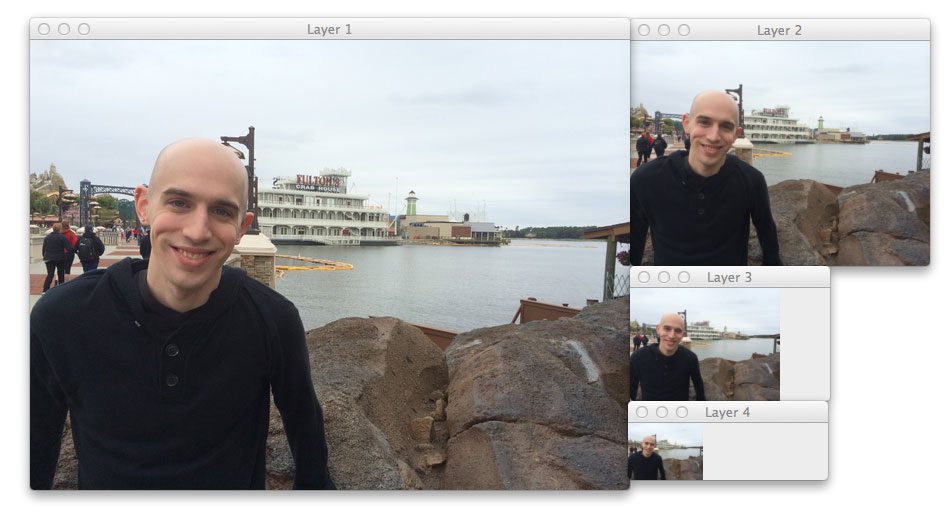
The scikit-image pyramid generated 4 layers since it reduced the image by 50% at each layer.
Now, let’s change the scale factor to 3.0 and see how the results change:
$ python pyramid.py --image images/adrian_florida.jpg --scale 1.5
And the resulting pyramid now looks like:
Using a scale factor of 3.0 , only 3 layers have been generated.
In general, there is a tradeoff between performance and the number of layers that you generate. The smaller your scale factor is, the more layers you need to create and process — but this also gives your image classifier a better chance at localizing the object you want to detect in the image.
A larger scale factor will yield less layers, and perhaps might hurt your object classification performance; however, you will obtain much higher performance gains since you will have less layers to process.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we discovered how to construct image pyramids using two methods.
The first method to image pyramid construction used Python and OpenCV and is the method I use in my own personal projects. Unlike the traditional image pyramid, this method does not smooth the image with a Gaussian at each layer of the pyramid, thus making it more acceptable for use with the HOG descriptor.
The second method to pyramid construction utilized Python + scikit-image and did apply Gaussian smoothing at each layer of the pyramid.
So which method should you use?
In reality, it depends on your application. If you are using the HOG descriptor for object classification you’ll want to use the first method since smoothing tends to hurt classification performance.
If you are trying to implement something like SIFT or the Difference of Gaussian keypoint detector, then you’ll likely want to utilize the second method (or at least incorporate smoothing into the first).

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Actually in option one you should smooth the image with a gaussian filter to remove high frequencies before down scaling and to prevent aliasing effects.
Hi Oliver, thanks for the comment. However, as mentioned in the Summary section of this article, Method #1 is intended to be used for object classification using HOG + Linear SVM. As demonstrated by Dalal and Triggs in their Histogram of Oriented Gradients for Human Detection paper, applying Gaussian smoothing (even to remove high frequency noise) prior to extracting HOG features actually hurts classification performance. So when using HOG, it’s actually best to just subsample and avoid the Gaussian smoothing.
I’m going to agree with Adrian. Gaussian smooth during downscaling seems like a good idea when you read the signal processing literature, but for features like HOG it doesn’t really matter.
With HOG it’s all about speed. The fewer operations your perform before the classifier hits the pixels, the better off you’ll be.
If you implement your own HOG (only loosely following Navneet Dalal’s recipe), you should build a test suite which measures your computation time and descriptor/classifier performance, and iterate. I can envision a variant of HOG that benefits from smoothing, but experiments should have the final word.
Hey, thanks for the comment Tomasz. I could not agree with you more — experiments should always have the final word.
Just to clarify, the resizing operation used in the imutils library does perform some level of smoothing to avoid aliasing effects (Moire patterns in the case of images). They call it interpolation, which only means it uses a different type of smoothing, not as strong as when using a Gaussian filter. Too much smoothing will destroy edge information which has a big impact on gradient computation. Depending on the type on interpolation scheme, you will tend to use digital filters with sharper transition bands to preserve edge information as much as possible. Downsampling without filtering would be as bad as oversmoothing for HOGs.
Hi!, that’s exactly what I am looking for, thank you so much for doing this post. I was reading about the use of Gaussian smooth during downscaling and now i am wondering if for haar-like features it should be used or not. thank you again.
Haar features are normally scaled in the feature space rather than the image space to avoid (unnecessarily) recomputing the integral images. I would refer to the original Viola-Jones paper on Haar cascades to read more about their sampling scheme.
Why don’t simply use Pyrup and Pyrdown from opencv?
OpenCV’s implementation of pyramids don’t give enough control. For example, one of my primary use cases for image pyramids is for object detection using Histogram of Oriented Gradients. It’s well known that applying Gaussian blurring prior to extracting HOG feature vectors can actually hurt performance — which is something OpenCV’s implementation of pyramids do, hence the scikit-image implementation is a better choice (at least in my opinion).
Hi Adrian, i have a question: The scale parameter will resized at each subsequent layer, so when will the parameter will stop?
Take a look at Line 4 where we define the
minSizeargument to thepyramidfunction. Once the image falls belowminSize, we break from the loop.awww sorry my bad, by the way can you explain to me how does the scale parameter work?
i read it from https://pyimagesearch.com/2015/11/16/hog-detectmultiscale-parameters-explained/ but i still nervous. please!
The scale simply controls the number of levels that are ultimately generated by the image pyramid. The smaller the scale, more layers in the image pyramid are generated. The larger the scale, the less pyramids are generated. I would suggest downloading the source code to this post and running the examples with varying scale parameters to convince yourself of this.
Hi, I have been using your tutorial to build a gesture classifier and localiser. I was successful in doing so. However, I do not understand what to do with image pyramid. I understand why it is used but i donot get what we have to do once we obtain the pyramid. Suppose I obtained the pyramid, ran my localiser on each image of the pyramid and then obtained a list of sliding windows which my localising classifier suggest is a window of interest. What do I do now? How do I combine the results? How do I get the best bounding box from all the scaled images?
Thanks in advance! Your tutorial is extremely helpful!
Hey Abhishek. My first suggestion would be to go through the PyImageSearch Gurus course where I explain how to build your own custom object detectors in lots of detail.
Secondly, you need to run your sliding window on each layer of the image pyramid and obtain your predictions. Once you have them, apply non-maxima suppression.
Again, I cover this entire process (with lots of code) inside the course.
Hi Adrian thanks for your reply! Okay so I did run sliding window on each layer of the pyramid, that gave me a list of windows most likely to be my object. I took the one of highest probability from each layer and then took the maximum probability one from that final set. I am guessing this is not the correct way to use Image Pyramid.
You said : run NMS after running sliding window on all layers. NMS algo takes as input a set of top left and bottom right coordinates, correct? Now, when i run sliding window on all layers, i will obtain coordinates of boxes in different scales of images. Should I give these coordinates as input directly to the NMS algo or do I have to rescale them somehow?
And I will definitely check out the course! Thanks!
Your intuition is correct. When you append a bounding box to your set of possible predictions, scale the bounding box by the ratio of the current pyramid level to the original scale of the image. This will give you the coordinates of the bounding boxes in the same scale as the original image. You then apply NMS to these bounding boxes.
Many thanks for your tut.
In HOG, before I fuse the overlap windows I have to know the coordinates of window in the original image. Should I construct a mapping between original image and resized image? Or this kind of mapping already exist some where?
OK, it seems a very stupid question…
You are correct, you would want to map the coordinates from the resized image to the original image. This can be accomplished by computing the ratio of the new image width to the old image width. I cover this in more detail inside the PyImageSearch Gurus course.
Hi again,
Also when I apply imutils.resize function, always get the left half of my image, do you know why? I just use ‘img_resize=imutils.resize(img, halfsize_of_my_image)’
Many thanks
I’m not sure what you mean by the “left half of my image”, can you elaborate?
Hi Adrian
Thanks a lot
of I got (x1,y1,x2,y2) at certain layer, how can I get the values on the original image to point to same box?
Simply compute the ratio of the original image dimensions to the current dimensions of the layer. Multiply the coordinates by this ratio and you’ll obtain the coordinates in relation to the original image. I cover this, and the rest of the object detection framework, inside the PyImageSearch Gurus course.
How to install Pyimagesearch module??
It is not pip-installable. Just use the “Downloads” section at the bottom of this blog post to download the source code to this post. It will include the “pyimagesearch” module.
Thanks for the quick reply Adrian. But still, cv2 module is not available in the “Downloads” section
If you cannot import the “cv2” module then you need to install and configure OpenCV on your system. Please see my tutorials on installing OpenCV for more information.
Hey Adrian thanks for this amazing tutorial im following it but i dont understand something
in the first method when you resize the image by dividing the column number by the scale factor , why you dont do the same with the height or rows of the image ? im not following that , something related with the reshape function perhaps?
also why do you compare at the end , the height of the new image with the min width , shouldnt we compare img height with min height and img width with min width?
The first method (using the
.resizefunction of imutils) automatically preserves the aspect ratio of the input image. As long as we compute the ratio with respect to one dimension the image will be properly resized.How do I save a picture after apply the pyramid layer
You can use the “cv2.imwrite” function to write each layer visualization to disk.
I am not able to understand how decreasing a size of image will help in detecting an object using pyrdown.
I am not able to understand its usage
The size of your sliding window ROI stays the same. If you keep the size of the sliding window the same and then go up and down layers of a pyramid you’ll be able to detect objects that are larger and smaller.
Hi, Adrian,
I think you should have mentioned `cv2.pyrDown()` for completeness because OpenCV has implementation of Gaussian pyramid without dependence on `scikit-image` package.
Also, when you build image pyramid with `cv2.resize()` you use default bilinear interpolation. Is it really better than, say, Lanczos8 which better preserves edges? (in theory)
1. The pyrDown function will introduce Gaussian blurring which can actually hurt the performance of HOG-based object detectors (which is the context in which this post was originally published).
That said…
2. All the type of interpolation and whether or not Gaussian blurring is performed is really just a hyperparameter. Run experiments and let your empirical results drive your decisions.
First of all, I would like to thank you for these tutorials. I have been following your blog for quite a while and will continue doing it. You are an amazing tutor. And I am soon going to check out >> https://pyimagesearch.com/pyimagesearch-gurus/
P.S. I guess, you have a typo error at one point. When you change the scale factor to 3.0 and show the demo of how the results change, the scale factor in the terminal command is still 1.5. You could just remove the image of that terminal command. People can ignore that though. 😉
Thanks Manoz!
Hello Adrian,
Yesterday I reported the program runs into an error using OpenCV4. I can’t find the post here anymore, but that can be for review purposes or so.
I found a solution here: https://stackoverflow.com/questions/46689428/convert-np-array-of-type-float64-to-type-uint8-scaling-values
Strangely, the most upvoted solution gives me only black images, but the second answer works fine for me.
I do not know why this works, as it worked on OpenCV3,
There is a deprecation warning on the pyramid_gaussian function, but that is solved by explicitly setting the multichannel parameter (to True, otherwise another error occurs in showing the images).
Thanks for all the wonderful blogs and fun way of learning.
Kind regards,
Peter Lans