 Since this is a computer vision and OpenCV blog, you might be wondering: “Hey Adrian, why in the world are you talking about scraping images?”
Since this is a computer vision and OpenCV blog, you might be wondering: “Hey Adrian, why in the world are you talking about scraping images?”
Great question.
The reason is because image acquisition is one of the most under-talked about subjects in the computer vision field!
Think about it. Whether you’re leveraging machine learning to train an image classifier, building an image search engine to find relevant images in a collection of photos, or simply developing your own hobby computer vision application — it all starts with the images themselves.
And where do these images come from?
Well, if you’re lucky, you might be utilizing an existing image dataset like CALTECH-256, ImageNet, or MNIST.
But in the cases where you can’t find a dataset that suits your needs (or when you want to create your own custom dataset), you might be left with the task of scraping and gathering your images. While scraping a website for images isn’t exactly a computer vision technique, it’s still a good skill to have in your tool belt.
In the remainder of this blog post, I’ll show you how to use the Scrapy framework and the Python programming language to scrape images from webpages.
Specifically, we’ll be scraping ALL Time.com magazine cover images. We’ll then use this dataset of magazine cover images in the next few blog posts as we apply a series of image analysis and computer vision algorithms to better explore and understand the dataset.
Installing Scrapy
I actually had a bit of a problem installing Scrapy on my OSX machine — no matter what I did, I simply could not get the dependencies installed properly (flashback to trying to install OpenCV for the first time as an undergrad in college).
After a few hours of tinkering around without success, I simply gave up and switched over to my Ubuntu system where I used Python 2.7. After that, installation was a breeze.
The first thing you’ll need to do is install a few dependencies to help Scrapy parse documents (again, keep in mind that I ran these commands on my Ubuntu system):
$ sudo apt-get install libffi-dev $ sudo apt-get install libssl-dev $ sudo apt-get install libxml2-dev libxslt1-dev
Note: This next step is optional, but I highly suggest you do it.
I then used virtualenv and virtualenvwrapper to create a Python virtual environment called scrapy to keep my system site-packages independent and sequestered from the new Python environment I was about to setup. Again, this is optional, but if you’re a virtualenv user, there’s no harm in doing it:
$ mkvirtualenv scrapy
In either case, now we need to install Scrapy along with Pillow, which is a requirement if you plan on scraping actual binary files (such as images):
$ pip install pillow $ pip install scrapy
Scrapy should take a few minutes to pull down its dependencies, compile, and and install.
You can test that Scrapy is installed correctly by opening up a shell (accessing the scrapy virtual environment if necessary) and trying to import the scrapy library:
$ python >>> import scrapy >>>
If you get an import error (or any other error) it’s likely that Scrapy was not linked against a particular dependency correctly. Again, I’m no Scrapy expert so I would suggest consulting the docs or posting on the Scrapy community if you run into problems.
Creating the Scrapy project
If you’ve used the Django web framework before, then you should feel right at home with Scrapy — at least in terms of project structure and the Model-View-Template pattern; although, in this case it’s more of a Model-Spider pattern.
To create our Scrapy project, just execute the following command:
$ scrapy startproject timecoverspider
After running the command you’ll see a timecoverspider in your current working directory. Changing into the timecoverspider directory, you’ll see the following Scrapy project structure:
|--- scrapy.cfg | |--- timecoverspider | | |--- __init__.py | | |--- items.py | | |--- pipelines.py | | |--- settings.py | | |--- spiders | | | |---- __init__.py | | | |---- coverspider.py # (we need to manually create this file)
In order to develop our Time magazine cover crawler, we’ll need to edit the following files two files: items.py and settings.py . We’ll also need to create our customer spider, coverspider.py inside the spiders directory
Let’s start with the settings.py file which only requires to quick updates. The first is to find the ITEMS_PIPELINE tuple, uncomment it (if it’s commented out), and add in the following setting:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy.contrib.pipeline.images.FilesPipeline': 1,
}
This setting will activate Scrapy’s default file scraping capability.
The second update can be appended to the bottom of the file. This value, FILES_STORE , is simply the path to the output directory where the download images will be stored:
FILES_STORE = "/home/adrian/projects/time_magazine/timecoverspider/output"
Again, feel free to add this setting to the bottom of the settings.py file — it doesn’t matter where in the file you put it.
Now we can move on to items.py , which allows us to define a data object model for the webpages our spider crawls:
# import the necessary packages import scrapy class MagazineCover(scrapy.Item): title = scrapy.Field() pubDate = scrapy.Field() file_urls = scrapy.Field() files = scrapy.Field()
The code here is pretty self-explanatory. On Line 2 we import our scrapy package, followed by defining the MagazineCover class on Line 4. This class encapsulates the data we’ll scrape from each of the time.com magazine cover webpages. For each of these pages we’ll return a MagazineCover object which includes:
title: The title of the current Time magazine issue. For example, this could be “Code Red”, “The Diploma That Works”, “The Infinity Machine”, etc.pubDate: This field will store the date the issue was published on inyear-month-dayformat.file_urls: Thefile_urlsfield is a very important field that you must explicitly define to scrape binary files (whether it’s images, PDFs, mp3s), etc. from a website. You cannot name this variable differently and must be within yourItemsub-class.files: Similarly, thefilesfield is required when scraping binary data. Do not name it anything different. For more information on the structure of theItemsub-class intended to save binary data to disk, be sure to read this thread on Scrapy Google Groups.
Now that we have our settings updated and created our data model, we can move on to the hard part — actually implementing the spider to scrape Time for cover images. Create a new file in the spiders directory, name it coverspider.py , and we’ll get to work:
# import the necessary packages from timecoverspider.items import MagazineCover import datetime import scrapy class CoverSpider(scrapy.Spider): name = "pyimagesearch-cover-spider" start_urls = ["http://search.time.com/results.html?N=46&Ns=p_date_range|1"]
Lines 2-4 handle importing our necessary packages. We’ll be sure to import our MagazineCover data object, datetime to parse dates from the Time.com website, followed by scrapy to obtain access to our actual spidering and scraping tools.
From there, we can define the CoverSpider class on Line 6, a sub-class of scrapy.Spider . This class needs to have two pre-defined values:
name: The name of our spider. Thenameshould be descriptive of what the spider does; however, don’t make it too long, since you’ll have to manually type it into your command line to trigger and execute it.start_urls: This is a list of the seed URLs the spider will crawl first. The URL we have supplied here is the main page of the Time.com cover browser.
Every Scrapy spider is required to have (at a bare minimum) a parse method that handles parsing the start_urls . This method can in turn yield other requests, triggering other pages to be crawled and spidered, but at the very least, we’ll need to define our parse function:
# import the necessary packages
from timecoverspider.items import MagazineCover
import datetime
import scrapy
class CoverSpider(scrapy.Spider):
name = "pyimagesearch-cover-spider"
start_urls = ["http://search.time.com/results.html?N=46&Ns=p_date_range|1"]
def parse(self, response):
# let's only gather Time U.S. magazine covers
url = response.css("div.refineCol ul li").xpath("a[contains(., 'TIME U.S.')]")
yield scrapy.Request(url.xpath("@href").extract_first(), self.parse_page)
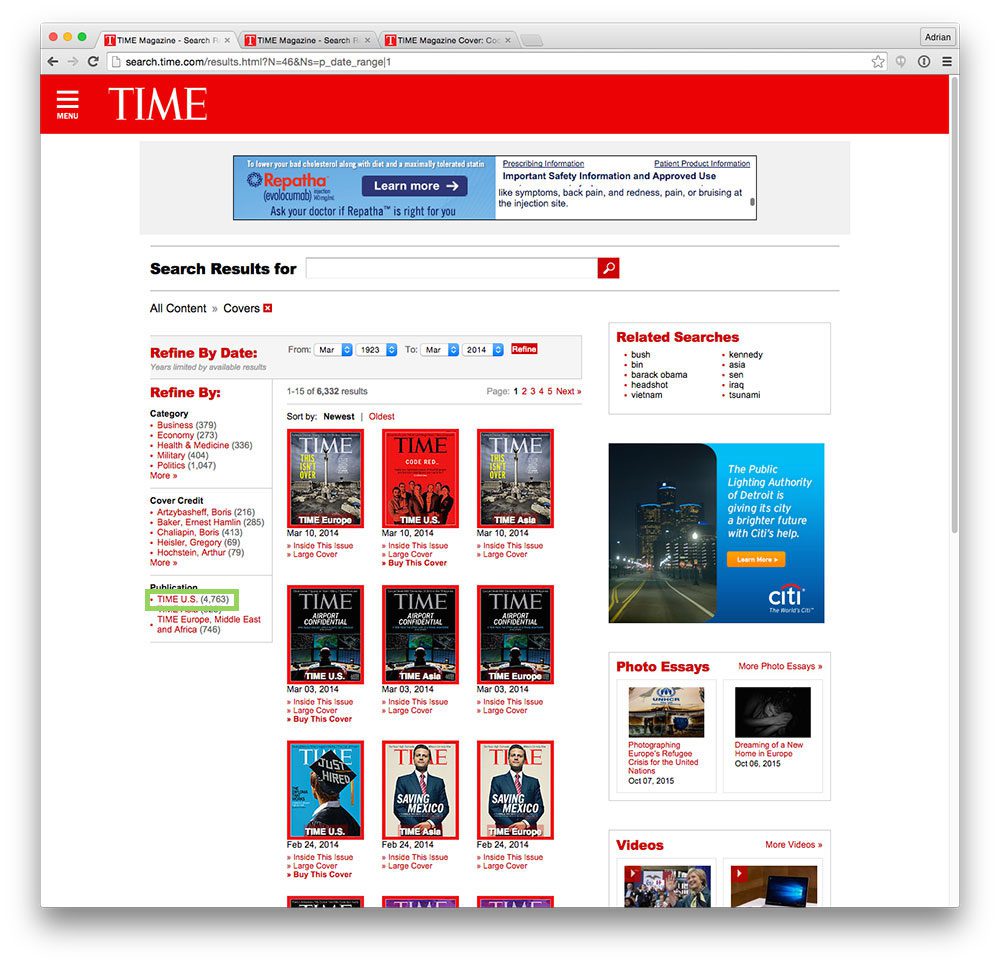
One of the awesome aspects of Scrapy is the ability to traverse the Document Object Model (DOM) using simple CSS and XPath selectors. On Line 12 we traverse the DOM and grab the href (i.e. URL) of the link that contains the text TIME U.S. . I have highlighted the “TIME U.S.” link in the screenshot below:
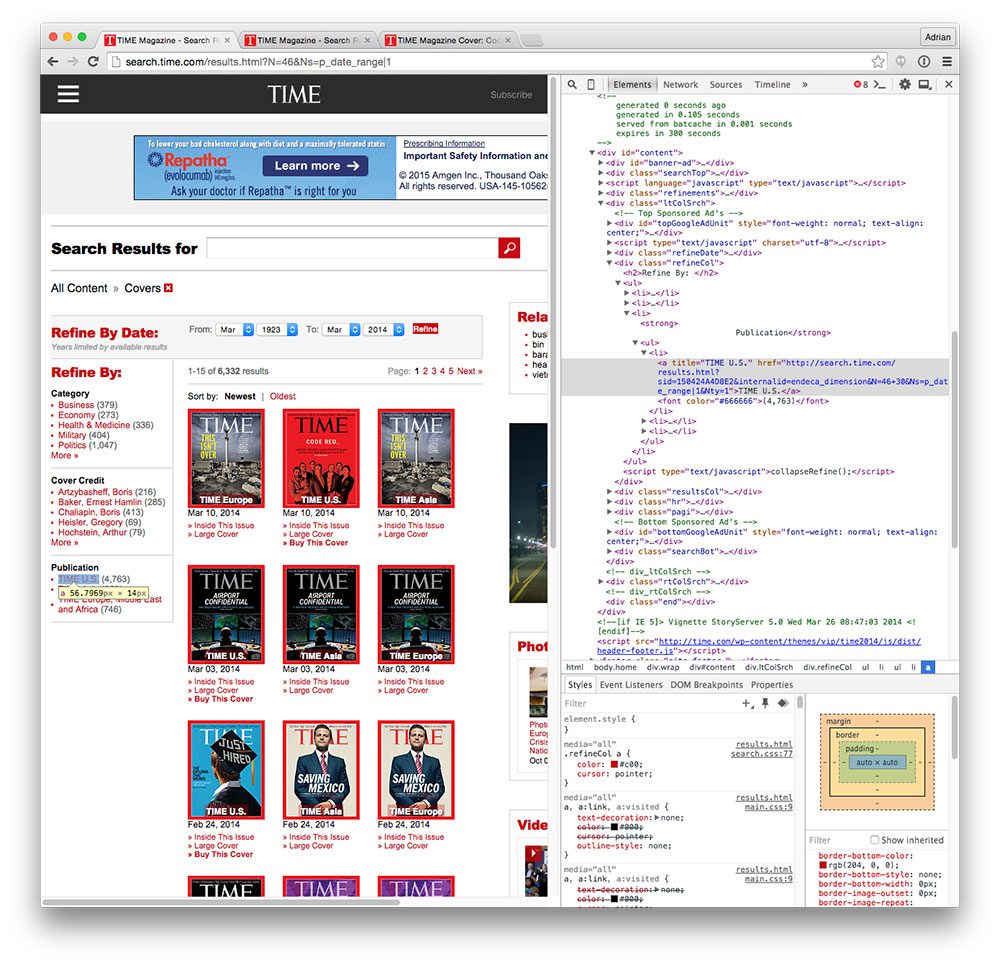
I was able to obtain this CSS selector by using the Chrome browser, right clicking on the link element, selecting Inspect Element”, and using Chrome’s developer tools to traverse the DOM:
Now that we have the URL of the link, we yield a Request to that page (which is essentially telling Scrapy to “click that link”), indicating that the parse_page method should be used to handle parsing it.
A screenshot of the “TIME U.S.” page can be seen below:
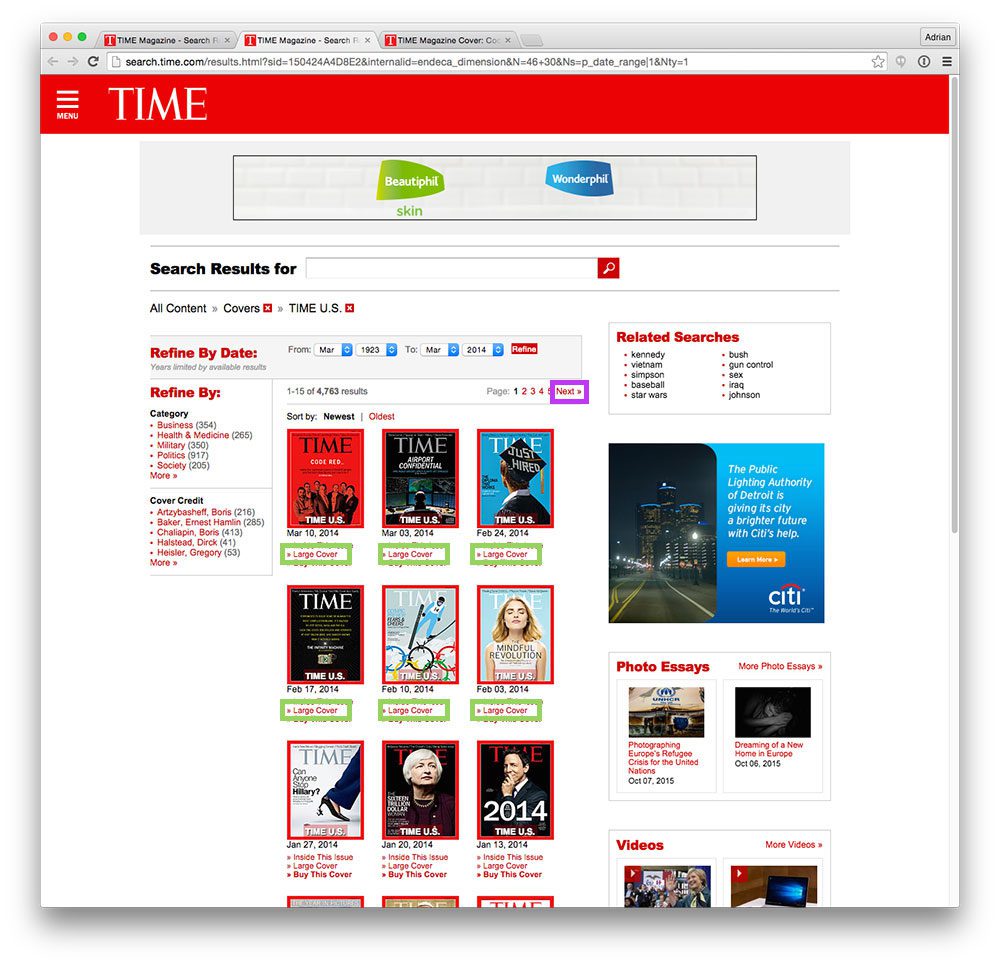
We have two primary goals in parsing this page:
- Goal #1: Grab the URLs of all links with the text “Large Cover” (highlighted in green in the figure above).
- Goal #2: Once we have grabbed all the “Large Cover” links, we need to click the “Next” button (highlighted in purple), allowing us to follow the pagination and parse all issues of Time and grab their respective covers.
Below follows our implementation of the parse_page method to accomplish exactly this:
def parse_page(self, response):
# loop over all cover link elements that link off to the large
# cover of the magazine and yield a request to grab the cove
# data and image
for href in response.xpath("//a[contains(., 'Large Cover')]"):
yield scrapy.Request(href.xpath("@href").extract_first(),
self.parse_covers)
# extract the 'Next' link from the pagination, load it, and
# parse it
next = response.css("div.pages").xpath("a[contains(., 'Next')]")
yield scrapy.Request(next.xpath("@href").extract_first(), self.parse_page)
We start off on Line 19 by looping over all link elements that contain the text Large Cover . For each of these links, we “click” it, and yield a request to that page using the parse_covers method (which we’ll define in a few minutes).
Then, once we have generated requests to all cover pages, it’s safe to click the Next button and use the same parse_page method to extract data from the following page as well — this process is repeated until we have exhausted the pagination of magazine issues and there are no further pages in the pagination to process.
The last step is to extract the title , pubDate , and store the Time cover image itself. An example screenshot of a cover page from Time can be seen below:
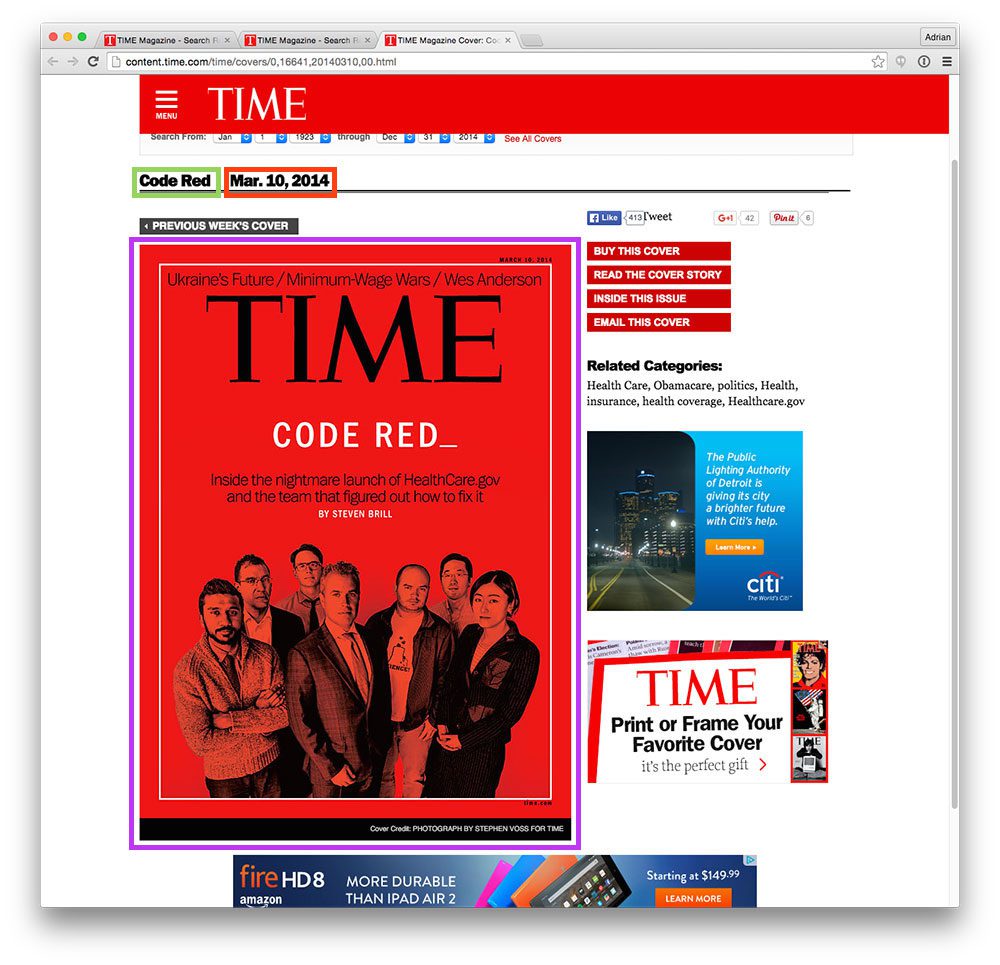
Here I have highlighted the issue name in green, the publication date in red, and the cover image itself in purple. All that’s left to do is define the parse_covers method to extract this data:
def parse_covers(self, response):
# grab the URL of the cover image
img = response.css(".art-cover-photo figure a img").xpath("@src")
imageURL = img.extract_first()
# grab the title and publication date of the current issue
title = response.css(".content-main-aside h1::text").extract_first()
year = response.css(".content-main-aside h1 time a::text").extract_first()
month = response.css(".content-main-aside h1 time::text").extract_first()[:-2]
# parse the date
date = "{} {}".format(month, year).replace(".", "")
d = datetime.datetime.strptime(date, "%b %d %Y")
pub = "{}-{}-{}".format(d.year, str(d.month).zfill(2), str(d.day).zfill(2))
# yield the result
yield MagazineCover(title=title, pubDate=pub, file_urls=[imageURL])
Just as the other parse methods, the parse_covers method is also straightforward. Lines 30 and 31 extract the URL of the cover image.
Lines 33 grabs the title of the magazine issue, while Lines 35 and 36 extract the publication year and month.
However, the publication date could use a little formatting — let’s create a consisting formatting in year-month-day . While it’s not entirely obvious at this moment why this date formatting is useful, it will be very obvious in next week’s post when we actually perform a temporal image analysis on the magazine covers themselves.
Finally, Line 44 yields a MagazineCover object including the title , pubDate , and imageURL (which will be downloaded and stored on disk).
Running the spider
To run our Scrapy spider to scrape images, just execute the following command:
$ scrapy crawl pyimagesearch-cover-spider -o output.json
This will kick off the image scraping process, serializing each MagazineCover item to an output file, output.json . The resulting scraped images will be stored in full , a sub-directory that Scrapy creates automatically in the output directory that we specified via the FILES_STORE option in settings.py above.
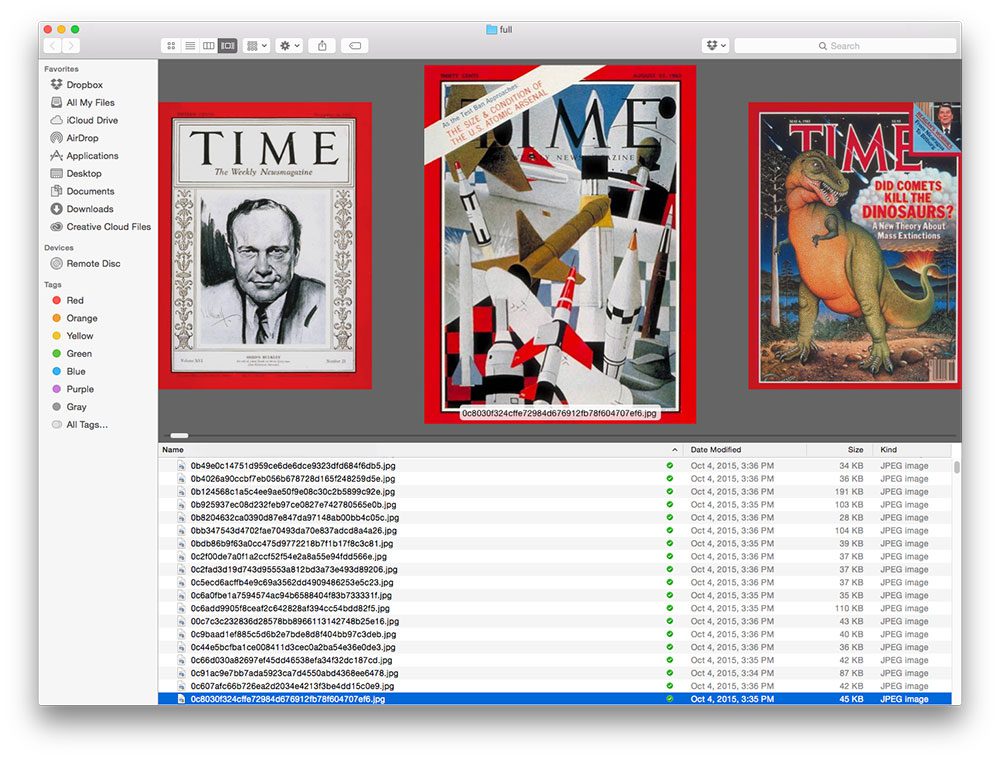
Below follows a screenshot of the image scraping process running:
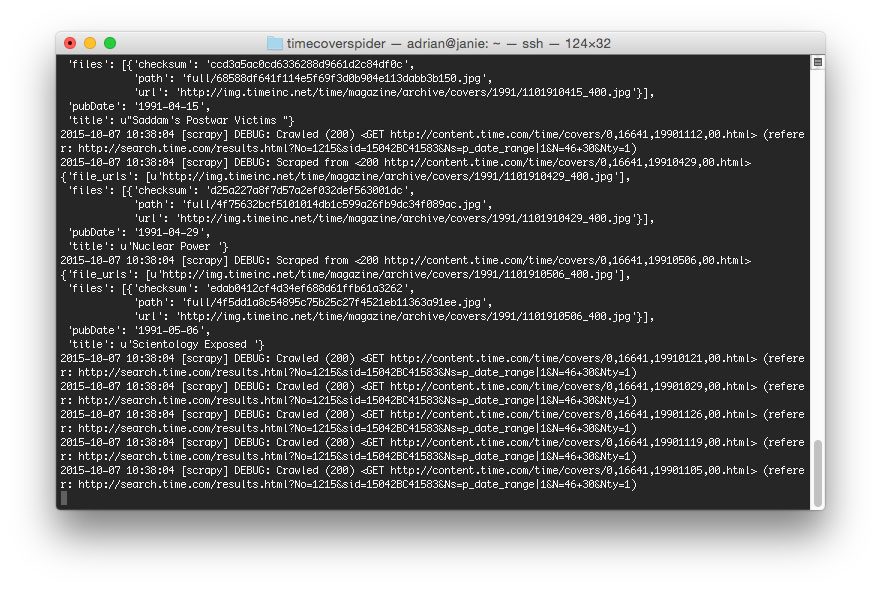
On my system, the entire scrape to grab all Time magazine covers using Python + Scrapy took a speedy 2m 23s — not bad for nearly 4,000 images!
Our complete set of Time magazine covers
Now that our spider has finished scraping the Time magazine covers, let’s take a look at our output.json file:
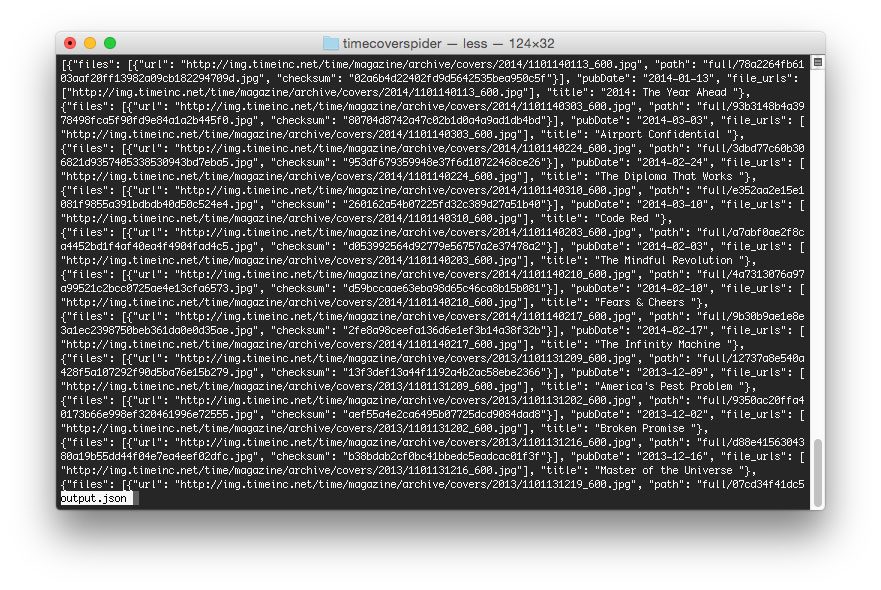
To inspect them individually, let’s fire up a Python shell and see what we’re working with:
$ python
>>> import json
>>> data = open("output.json").read()
>>> data = json.loads(data)
>>> len(data)
3969
As we can see, we have scraped a total of 3,969 images.
Each entry in the data list is a dictionary, which essentially maps to our MagazineCover data model:
>>> data[0]
{u'files': [{u'url': u'http://img.timeinc.net/time/magazine/archive/covers/2014/1101140113_600.jpg', u'path': u'full/78a2264fb6103aaf20ff13982a09cb182294709d.jpg', u'checksum': u'02a6b4d22402fd9d5642535bea950c5f'}], u'file_urls': [u'http://img.timeinc.net/time/magazine/archive/covers/2014/1101140113_600.jpg'], u'pubDate': u'2014-01-13', u'title': u'2014: The Year Ahead '}
>>> data[0].keys()
[u'files', u'file_urls', u'pubDate', u'title']
We can easily grab the path to the Time cover image like this:
>>> print("Title: {}\nFile Path: {}".format(data[0]["title"], data[0]["files"][0]["path"]))
Title: 2014: The Year Ahead
File Path: full/78a2264fb6103aaf20ff13982a09cb182294709d.jpg
Inspecting the output/full directory we can see we have our 3,969 images:
$ cd output/full/
$ ls -l *.jpg | wc -l
3969
So now that we have all of these images, the big question is: “What are we going to do with them?!”
I’ll be answering that question over the next few blog posts. We’ll be spending some time analyzing this dataset using computer vision and image processing techniques, so don’t worry, your bandwidth wasn’t wasted for nothing!
Note: If Scrapy is not working for you (or if you don’t want to bother setting it up), no worries — I have included the output.json and raw, scraped .jpg images in the source code download of the post found at the bottom of this page. You’ll still be able to follow along through the upcoming PyImageSearch posts without a problem.
What's next? We recommend PyImageSearch University.

84 total classes • 114+ hours of on-demand code walkthrough videos • Last updated: February 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 84 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 84 Certificates of Completion
- ✓ 114+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 536+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we learned how to use Python scrape all cover images of Time magazine. To accomplish this task, we utilized Scrapy, a fast and powerful web scraping framework. Overall, our entire spider file consisted of less than 44 lines of code which really demonstrates the power and abstraction behind the Scrapy libray.
So now that we have this dataset of Time magazine covers, what are we going to do with them?
Well, this is a computer vision blog after all — so next week we’ll start with a visual analytics project where we perform a temporal investigation of the cover images. This is a really cool project and I’m super excited about it!
Be sure to sign up for PyImageSearch newsletter using the form at the bottom of this post — you won’t want to miss the followup posts as we analyze the Time magazine cover dataset!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

