
Ever wonder what it’s like to work as a computer vision researcher or developer?
You’re not alone.
Over the past few years running PyImageSearch I have received emails and inquiries that are “outside” traditional computer vision and OpenCV questions.
They instead focus on something much more personal — my daily life.
PyImageSearch reader Jared, asked:
“What is it like being a computer vision researcher and developer? What do you actually do day-to-day?”
Another reader, Miguel, inquired:
“You’ve written a computer vision book and a course. And now you’re starting a new book on deep learning? How do you get all this done? What’s your secret?”
Saanvi’s suggestion is one of my personal favorites:
“Adrian, you should write your next book on productivity.”
Now that the Deep Learning for Computer vision with Python Kickstarter campaign is online, I’ve been getting more of these questions than ever.
Because of this, I thought I could do something a little different today — give you an exclusive, behind the scenes look at:
- How I spend my day.
- What it’s like balancing my role as a computer vision researcher/developer with a writer on PyImageSearch.
- The habits and practices I’ve spent years perfecting to help me get shit done.
To see what it’s like to live a day in my shoes, keep reading.
Morning (5:15AM – 12:00PM)
The follow blog post follows my daily activities on Monday, January 23rd.
Getting out of bed

5:20AM.
My alarm goes off on my iPhone.
I reach over and turn it off after a few seconds, readjusting to consciousness.
Time to get out of bed.
I don’t think twice about it.
I don’t check Facebook notifications. I don’t look a Twitter. And I don’t even think about checking email.
I sit up
Stretch.
And immediately drink 12oz of water from the Nalgene on my nightstand.
The water helps start my metabolism, flushes out toxins built up from the night before, and most importantly, helps me hydrate — at this point I’ve gone ~8 hours without water and I need to rehydrate. Your brain tissue is 75% water after all.
This 12oz of water is the first of ~200oz I’ll consume throughout the rest of the day.
The day has started and I only have one goal: get shit done.
Caffeinate (strategically)

My work day starts immediately.
I walk from the bedroom to the kitchen and prepare a nice hot cup of coffee — this is the only caffeine I will consume the entire day.
Don’t get me wrong:
I love coffee.
But I’m also a strong believer in the strategic use of caffeine (whether in coffee or tea form).
Back in graduate school I would drink a large mug of coffee in the morning followed by a massive iced coffee from Dunkin Donuts soon after lunch. By the afternoon I felt exhausted. I didn’t realize my caffeine intake was actually hurting my productivity.
Caffeine may give you a short term jolt of energy, but it also comes with a crash later on in the day. Therefore, we can actually view consuming caffeine as borrowing energy from later in the day. That energy and focus have to come from somewhere. And unfortunately, that “loan” must be paid in the afternoon during our crash.
Two years ago I stopped consuming large amounts of caffeine.
Now all I have is a (very) strong dark roast in the morning with a splash of heavy cream. The heavy cream contains fats that help jumpstart by brain. I avoid sugar as much as possible.
Check on neural network training
I’m currently running a Kickstarter campaign to fund the creation of my new book, Deep Learning for Computer Vision with Python.
For this book I am running a bunch of experiments where I train various network architectures (AlexNet, VGGNet, SqueezeNet, GoogLeNet, ResNet, etc.) on the massive ImageNet dataset.
I currently have experiments running for both VGGNet and SqueezeNet. These networks have been training overnight so I need to:
- Inspect their accuracy/loss curves.
- Determine if the networks are overfitting (or at risk for overfitting).
- Adjust any relevant hyperparameters (i.e., learning rate, weight decay) and restart training.
- Estimate when I should check the networks again.
First up is VGGNet:
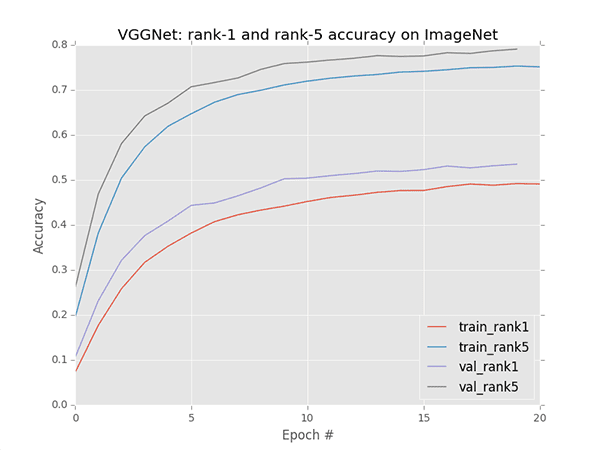
After just 20 epochs of training VGGNet is hitting 53.52% rank-1 accuracy.
Accuracy (and loss, not pictured) are starting to stagnate slightly — I will likely have to lower the learning rate from 1e-2 to 1e-3 within the next 20 epochs.
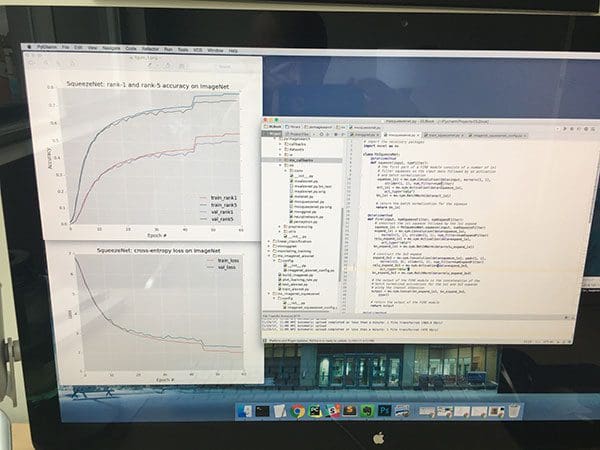
Then comes SqueezeNet:
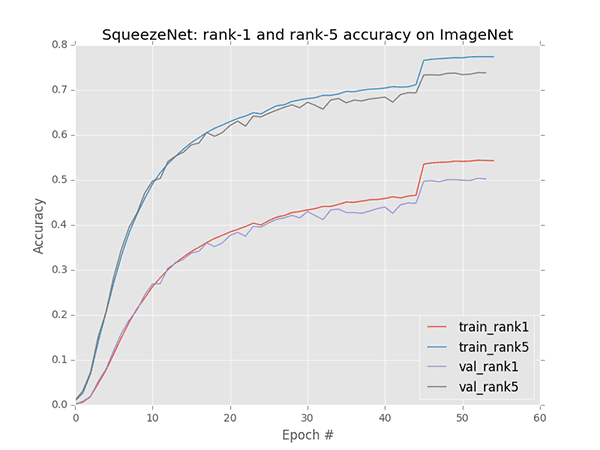
Epochs 0-45 were trained with a 1e-2 learning rate. As training and validation accuracy/loss started to diverge around epoch 45 I updated the learning rate to be 1e-3.
However, we can now see that learning is quite stagnated and unable to get above the 50.2% rank-1 hump.
We are also getting a bit of overfitting, but nothing too terribly concerning (yet).
I’m going to change the learning rate to 1e-4, but I’m not really expecting any more large gains in accuracy out of the experiment at this point.
Future experiments with include replacing the default activation function (ReLU) with a leaky ReLU variant (such as ELU). I’m also considering playing around with adding BatchNorm layers to the architecture as I’m unaware of any previous SqueezeNet experiments that have done this, but I have seen it (successfully) work before with other micro-architectures such as GoogLeNet and ResNet (experimenting is half the fun, after all).
The reason why I spend the first 10 minutes of my morning look at training progress is so I can update any relevant hyperparameters and continue training the network.
Some of these networks can take a long time to train (VGGNet is currently taking ~2.9 hours per epoch) so it’s important to spend time looking at the accuracy/loss, then moving on with your day (and trying not to think about them again until you have more data to make an informed decision with).
When I first started working with deep learning I was guilty of making a critical mistake: looking at my loss/accuracy plots too often.
When training deep neural networks you often need the context of 10-15 epochs to make informed decisions regarding updating learning rates and which epoch you restart training at. Without this context you’ll find yourself spinning your wheels and overthinking the training process.
Let your network train.
The results will come in.
And then you’ll be able to make an informed decision on how to continue.
What about email?
You might be wondering why I’m not popping open my inbox and reading through my email?
The answer is because my mornings are my most productive and creative time of the day, thus I guard this time very closely. These hours of the day are the equivalent to by Biological Prime Time where I have the most energy and are most likely to be hyper productive.
In short, my goal for this time of day is to reach flow state as soon as possible and maintain it for as long as possible.
I classify email as a procedural task — read email, reply, and repeat until inbox is empty. It’s not task that requires creative energy.
On the other hand, there are a lot of tasks I undertake that are creative in nature. Examples include:
- Writing a new blog post/tutorial.
- Outlining a chapter in my upcoming deep learning book.
- Working on a tricky piece of code.
- Researching a new algorithm.
All of these tasks require a bit of extra brainpower stemming from the creative side. I spend my mornings working on these types of tasks. Email has its place, just not until later in the day.
Planning my “3 Big Things”
I first heard the phrase “relentless execution” from Rob Walling a year or two ago at a conference. The cornerstone of the idea is something we’re all familiar with:
- Break a complex project down into smaller pieces/sub-pieces.
- Individually complete each piece.
- Combine the pieces together to form the solution to the problem.
The concept of relentless execution focuses on Step #2. Once we’ve identified the parts that make up the whole, we need to relentlessly and consistently complete them on a day-to-day basis.
This also goes hand-in-hand with incremental improvement — small, consistent daily changes added up over a period of time yield large growth.
To facilitate this process I spend every Sunday morning planning out the tasks that I want to get done the following week. You can think of this list as an informal sprint task list that developers use, except:
- This list combines business and software tasks.
- Is done on a weekly basis rather than every 2-3 weeks.
Every morning I take three of the tasks from my weekly list and add them to my 3 Big Things I aim to accomplish for the day:

Today my three big tasks are:
- Document “A day in my life” (which allowed me to write this blog post).
- Plan out the Kickstarter stretch goals for my deep learning book (which you can find here).
- Start working with age/gender classification (one chapter in my upcoming deep learning book will demonstrate how to use CNNs to classify the age and gender of a person from a photo; more on that later in this post).
Again, Being productive and solving challenging problems isn’t about solving them all at once. Instead, break down large, complex problems into smaller pieces and solve each of them individually. Doing this on a daily basis guarantees you incremental “wins” which add up in the long run. Not to mention, aiming for smaller wins in the short term allows you to create momentum and gives your brain a nice endorphin rush.
If you haven’t noticed yet, I’m a big productivity geek so if you’re interested in learning more about productivity hacks you can apply to your own life, check out The Productivity Project: Accomplishing More by Managing your Time, Attention, and Energy by Chris Bailey.
I normally don’t recommend productivity books (since they tend to rehash the same material), but Chris’ is the real deal.
Start on item #1
After I’ve mapped out my “3 Big Things” for the day I immediately jump into the first one.
Today is a special case since I’m already documenting my day and will be for the rest of the day.
I then move into #2, planning out the Kickstarter stretch goals. I’ll continue doing this task until breakfast.
Breakfast
My mother always told me that breakfast is the most important meal of the day — I never believed her, but then again, that might be because I didn’t get out of bed until 10:30AM when I was in college.
It wasn’t until I started getting up around 5AM in the morning every day that my perspective shifted and I realized breakfast is the most important meal (at least for me).
Having a large healthy breakfast of proteins, fats, and veggies ensures that I’ll be able to come off the caffeine high and continue to be productive, even towards the end of the morning. Furthermore, going with a high protein, high fat diet ensures the fats deliver a longer, sustainable energy burn throughout the rest of the day — this is also beneficial when I go to the gym in the mid-afternoon.
For the health geeks out there (like me) I’m referring to a paleo-esque diet, a diet that consists predominantly of veggies, fruits, nuts, roots, and meats. Dairy products (there is no lactose in heavy cream), grains, and processed foods are avoided.
There are many variations and interpretations of the paleo diet and it’s taken me a few years to zero-in on what works for me. For example, I’ve been able to add in small amounts of dairy (like cheese) into my diet without adverse affects. The fun part about these types of diets is finding what works for you personally.
In my case, I’m fortunate enough to have a fiancé that prepares breakfast every morning (yes, every morning). I’m extremely lucky and grateful to have hit such a jackpot.
At around 7:45AM her and I eat breakfast together before she heads off to work. Doing this ensures we have quality time together every morning:

Today I’m having:
- Three eggs scrambled with sausage, onions, peppers, and spinach.
- Two slices of bacon.
- A handful of orange slices.
Her and I have breakfast together and then around 8:15AM I go back to work.
Turning off notifications
After breakfast all notifications go off so I can reach and maintain flow state.
My iPhone is silenced.
Slack is shut down.
I don’t even think about checking Facebook, Twitter, or reddit.
Next I put on Gunnar eye glasses (to reduce eye strain; I have issues with ocular migraines if I strain my eyes too long under stressful situations) and noise canceling headphones to ensure I’m not disturbed:

Lastly, I even turn off the actual clock on my desktop:
Time is constant distraction. It’s too easy to look up from your work and think “Man, I’ve been at this for 40 minutes” and then allow your mind to wonder. In short, looking at the clock breaks flow state.
Instead, turn off your clock and stop caring — you’ll realize that time is relative and you’ll break from flow when you’re naturally tired.
Now that I’m “in the zone” my goal is to finish up planning the Kickstarter stretch goals along with creating visualizations for GoogLeNet’s Inception module and ResNet’s Residual module:
By 10:54AM I have finished planning the Kickstarter stretch goals and the network module visualizations.
From there I come out of flow so I can share the latest PyImageSearch blog post on social media (since it’s a Monday and new posts are published on Mondays):
Before lunch I check-in on SqueezeNet again and see that loss and accuracy have topped out. I’m also seeing the threat of overfitting becoming bothersome (but again, not terrible):
I log the results to my lab journal and then update the code to experiment with BatchNorm. I kick the experiment off — and then it’s time for lunch.
Lunch
My ideal time to eat lunch is between 11:00-11:30AM.
I normally eat leftovers from dinner the night before or a salad from the shop down the street. Since I don’t have any leftovers from last night, I opted for a salad:

On my salad I have roasted turkey, tomato, avocado (healthy fats!) and yes, a tiny bit of cheese. As I mentioned above, I’ve tweaked my own personal paleo diet over the years and found I can consume small amounts of dairy without it affecting my energy levels or overall health.
At this point I start consuming my daily allotment of coconut water (about 300mL) along with my regular water. Coconut water helps reduce cortisol levels which in turn reduces stress. It’s also a good source of potassium.
Meditation and mindfulness
After lunch I spend 10-15 minutes meditating. I personally like to use the Calm app:
A bit of mindfulness allows me to re-center myself and continue with my day.
Afternoon (12:00PM – 5PM)
I start off my afternoon by picking the next uncompleted task off my “3 Big Things” list and cranking away on it. I continue to keep notifications off and keep my noise canceling headphones on.
If I’m outline a tutorial or writing a blog post I tend to go for instrumental music. This Will Destroy You, Explosions in the Sky, and God is an Astronaut are personal favorites for these types of task. The lack of lyrics allows me to not get distracted (I tend to sing along if there are lyrics).
On the other hand, if I’m writing code I normally default to music with lyrics — genres such as ska, punk, and hardcore are my favorite. I’ve spent countless hours in my lifetime coding to bands such as Minor Threat, Dillinger Four, and The Mighty Mighty Bosstones.
Today I’m starting some experiments for the age and gender classification chapter of my upcoming deep learning book. Given a photo of a person the goal is to:
- Detect the face in the image.
- Determine the age of the person.
- Approximate the gender of the person.
Deep learning algorithms have been quite successful for this specific task and will make for an excellent chapter in the book.
To start, I download the IMDB-WIKI face image dataset and start exploring.
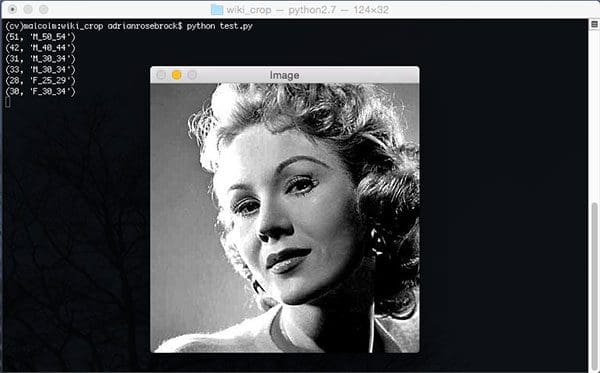
My first task is to understand the .mat annotation file included with the dataset. After ~45 minutes of hacking I’m able to extract the date of birth, age, and bounding box for each face in the dataset:
I then take a subset of the data and attempt to fine-tune VGG16 on the data as an initial trial run:
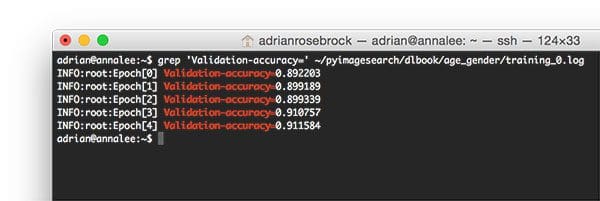
As the above screenshot demonstrates, after only a 5 epochs I’m getting 91%+ gender classification accuracy. This initial experiment is successful and warrants more exploration into fine-tuning VGG16.
Around 2:30-3PM I head to the gym for 1-1.5 hours.
Fitness is a huge part of my life.
I’ve played sports since I was a kid — soccer, baseball, basketball, you name it.
During my first year of graduate school I started weight lifting. I spent about a year lifting with a friend, and then when he graduated, I spent another year working out solo.
From there I found I got bored of the regular gym routine and started doing CrossFit. That eventually led me to olympic lifting. I now do a hybrid of olympic lifting (for strength) and CrossFit (for stamina).
The important takeaway here is the physical exercise is key to a healthy life. It doesn’t have to be much — just getting out of your chair (or better yet, use a standing desk) and going for a walk around the block can dramatically increase your productivity (and save you from heart issues). Find out what works for you and keep doing it. But also be mindful of what worked for you five years ago may not be working for you now.
Once I get back to the gym I shower and log back in to my computer.
Evening (5PM – 8PM)
At this point in the day the creative portion of my brain is exhausted. I’ve been up for approximately 12 hours and I’m hitting the natural cycle of my day where I have less energy.
That said, I can still handle procedural tasks without a problem, thus I spend much of this time reading and replying to emails.
If I don’t have any emails to answer, I might work on a bit of code.
Night (8PM – 10:30PM)
Once 8PM rolls around I try to disconnect as much as possible.
My laptop goes into sleep mood and I try to stay off my phone.
I normally like to unwind at the end of the night playing whatever my favorite RPG is at the moment:

I just beat The Witcher III: Wild Hunt (a game that has made its way into my “all time favorites list”) so I’m currently I’m playing through Final Fantasy VI (called Final Fantasy III in North America) on the SNES.
After a bit of gaming I might watch a bit of TV before calling it a night.
Then, it’s off to bed — ready to “relentlessly execute” the following morning.
If you enjoyed this blog post and want to be notified when future tutorials are published, please enter your email address in the form below.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

