
Over the past few weeks we have been discussing facial landmarks and the role they play in computer vision and image processing.
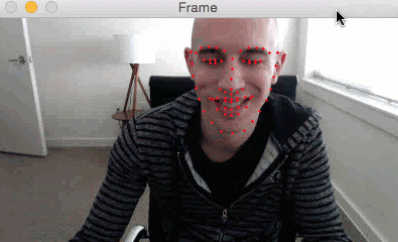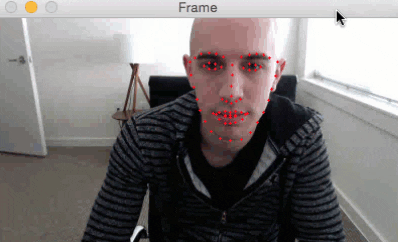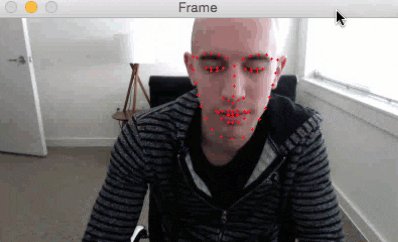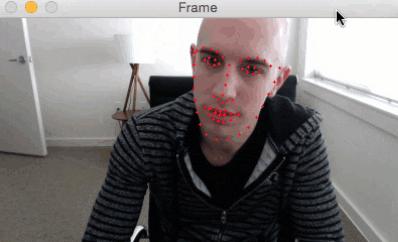
We’ve started off by learning how to detect facial landmarks in an image.
We then discovered how to label and annotate each of the facial regions, such as eyes, eyebrows, nose, mouth, and jawline.
Today we are going to expand our implementation of facial landmarks to work in real-time video streams, paving the way for more real-world applications, including next week’s tutorial on blink detection.
To learn how to detect facial landmarks in video streams in real-time, just keep reading.
Real-time facial landmark detection with OpenCV, Python, and dlib
The first part of this blog post will provide an implementation of real-time facial landmark detection for usage in video streams utilizing Python, OpenCV, and dlib.
We’ll then test our implementation and use it to detect facial landmarks in videos.
Facial landmarks in video streams
Let’s go ahead and get this facial landmark example started.
Open up a new file, name it video_facial_landmarks.py , and insert the following code:
# import the necessary packages from imutils.video import VideoStream from imutils import face_utils import datetime import argparse import imutils import time import dlib import cv2
Lines 2-9 import our required Python packages.
We’ll be using the face_utils sub-module of imutils, so if you haven’t installed/upgraded to the latest version, take a second and do so now:
$ pip install --upgrade imutils
Note: If you are using Python virtual environments, take care to ensure you are installing/upgrading imutils in your proper environment.
We’ll also be using the VideoStream implementation inside of imutils , allowing you to access your webcam/USB camera/Raspberry Pi camera module in a more efficient, faster, treaded manner. You can read more about the VideoStream class and how it accomplishes a higher frame throughout in this blog post.
If you would like to instead work with video files rather than video streams, be sure to reference this blog post on efficient frame polling from a pre-recorded video file, replacing VideoStream with FileVideoStream .
For our facial landmark implementation we’ll be using the dlib library. You can learn how to install dlib on your system in this tutorial (if you haven’t done so already).
Next, let’s parse our command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-r", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
args = vars(ap.parse_args())
Our script requires one command line argument, followed by a second optional one, each detailed below:
--shape-predictor: The path to dlib’s pre-trained facial landmark detector. Use the “Downloads” section of this blog post to download an archive of the code + facial landmark predictor file.--picamera: An optional command line argument, this switch indicates whether the Raspberry Pi camera module should be used instead of the default webcam/USB camera. Supply a value > 0 to use your Raspberry Pi camera.
Now that our command line arguments have been parsed, we need to initialize dlib’s HOG + Linear SVM-based face detector and then load the facial landmark predictor from disk:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
The next code block simply handles initializing our VideoStream and allowing the camera sensor to warm up:
# initialize the video stream and allow the cammera sensor to warmup
print("[INFO] camera sensor warming up...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
The heart of our video processing pipeline can be found inside the while loop below:
# loop over the frames from the video stream while True: # grab the frame from the threaded video stream, resize it to # have a maximum width of 400 pixels, and convert it to # grayscale frame = vs.read() frame = imutils.resize(frame, width=400) gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # detect faces in the grayscale frame rects = detector(gray, 0)
On Line 31 we start an infinite loop that we can only break out of if we decide to exit the script by pressing the q key on our keyboard.
Line 35 grabs the next frame from our video stream.
We then preprocess this frame by resizing it to have a width of 400 pixels and convert it to grayscale (Lines 36 an 37).
Before we can detect facial landmarks in our frame, we first need to localize the face — this is accomplished on Line 40 via the detector which returns the bounding box (x, y)-coordinates for each face in the image.
Now that we have detected the faces in the video stream, the next step is to apply the facial landmark predictor to each face ROI:
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
On Line 43 we loop over each of the detected faces.
Line 47 applies the facial landmark detector to the face region, returning a shape object which we convert to a NumPy array (Line 48).
Lines 52 and 53 then draw a series of circles on the output frame , visualizing each of the facial landmarks. To understand what facial region (i.e., nose, eyes, mouth, etc.) each (x, y)-coordinate maps to, please refer to this blog post.
Lines 56 and 57 display the output frame to our screen. If the q key is pressed, we break from the loop and stop the script (Lines 60 and 61).
Finally, Lines 64 and 65 do a bit of cleanup:
# do a bit of cleanup cv2.destroyAllWindows() vs.stop()
As you can see, there are very little differences between detecting facial landmarks in images versus detecting facial landmarks in video streams — the main differences in the code simply involve setting up our video stream pointers and then polling the stream for frames.
The actual process of detecting facial landmarks is the same, only instead of detecting facial landmarks in a single image we are now detecting facial landmarks in a series of frames.
Real-time facial landmark results
To test our real-time facial landmark detector using OpenCV, Python, and dlib, make sure you use the “Downloads” section of this blog post to download an archive of the code, project structure, and facial landmark predictor model.
If you are using a standard webcam/USB camera, you can execute the following command to start the video facial landmark predictor:
$ python video_facial_landmarks.py \ --shape-predictor shape_predictor_68_face_landmarks.dat
Otherwise, if you are on your Raspberry Pi, make sure you append the --picamera 1 switch to the command:
$ python video_facial_landmarks.py \ --shape-predictor shape_predictor_68_face_landmarks.dat \ --picamera 1
Here is a short GIF of the output where you can see that facial landmarks have been successfully detected on my face in real-time:
I have included a full video output below as well:
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we extended our previous tutorials on facial landmarks and applied them to the task of real-time detection.
As our results demonstrated, we are fully capable of detecting facial landmarks in a video stream in real-time using a system with a modest CPU.
Now that we understand how to access a video stream and apply facial landmark detection, we can move on to next week’s real-world computer vision application — blink detection.
To be notified when the blink detection tutorial goes live, be sure to enter your email address in the form below — this is a tutorial you won’t want to miss!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

