PyImageSearch reader José asks:
Hey Adrian, thanks for putting together Deep Learning for Computer Vision with Python. This is by far the best resource I’ve seen for deep learning.
My question is this:
I’m working on a project where I need to classify the scenes of outdoor photographs into four distinct categories: cities, beaches, mountains, and forests.
I’ve found a small dataset (~100 images per class), but my models are quick to overfit and far from accurate.
I’m confident I can solve this project, but I need more data.
What do you suggest?
José has a point — without enough training data, your deep learning and machine learning models can’t learn the underlying, discriminative patterns required to make robust classifications.
Which begs the question:
How in the world do you gather enough images when training deep learning models?
Deep learning algorithms, especially Convolutional Neural Networks, can be data hungry beasts.
And to make matters worse, manually annotating an image dataset can be a time consuming, tedious, and even expensive process.
So is there a way to leverage the power of Google Images to quickly gather training images and thereby cut down on the time it takes to build your dataset?
You bet there is.
In the remainder of today’s blog post I’ll be demonstrating how you can use Google Images to quickly (and easily) gather training data for your deep learning models.
Updated April 20, 2020: The JavaScript in this post has been updated because the previous method was no-longer working. Please refer to the updated code below.
Deep learning and Google Images for training data

Today’s blog post is part one of a three part series on a building a Not Santa app, inspired by the Not Hotdog app in HBO’s Silicon Valley (Season 4, Episode 4).
As a kid Christmas time was my favorite time of the year — and even as an adult I always find myself happier when December rolls around.
Looking back on my childhood, my dad always went out well of his way to ensure Christmas was a magical time.
Without him I don’t think this time of year would mean as much to me (and I certainly wouldn’t be the person I am today).
In order to keep the magic of ole’ Saint Nicholas alive, we’re going to spend the next three blog posts building our Not Santa detector using deep learning:
- Part #1: Gather Santa Clause training data using Google Images (this post).
- Part #2: Train our Not Santa detector using deep learning, Python, and Keras.
- Part #3: Deploy our trained deep learning model to the Raspberry Pi.
Let’s go ahead and get started!
Using Google Images for training data and machine learning models
The method I’m about to share with you for gathering Google Images for deep learning is from a fellow deep learning practitioner and friend of mine, Michael Sollami.
He discussed the exact same technique I’m about to share with you in a blog post of his earlier this year.
Updated April 20, 2020: Michael’s method no longer works with updates to both web browsers and the HTML/CSS used by Google Images to serve search results. I thank Michael for the original inspiration of this blog post. A “Real Big” thanks goes out to my friends and JavaScript experts at RealBigMarketing. RBM’s team developed the code update for this blog post. Thanks!
I’m going to elaborate on these steps and provide further instructions on how you can use this technique to quickly gather training data for deep learning models using Google Images, JavaScript, and a bit of Python.
The first step in using Google Images to gather training data for our Convolutional Neural Network is to head to Google Images and enter a query.
In this case we’ll be using the query term “santa clause”:
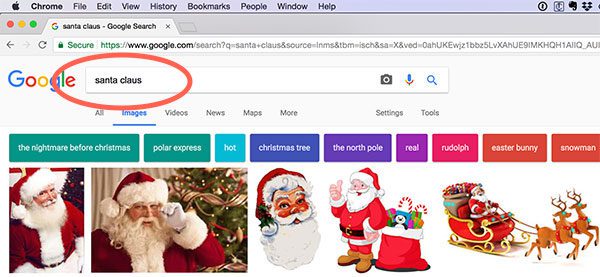
As you can see from the example image above we have our search results.
The next step is to use a tiny bit of JavaScript to gather the image URLs (which we can then download using Python later in this tutorial).
Fire up the JavaScript console (I’ll assume you are using the Chrome web browser, but you can use Firefox as well) by clicking View => Developer => JavaScript Console :
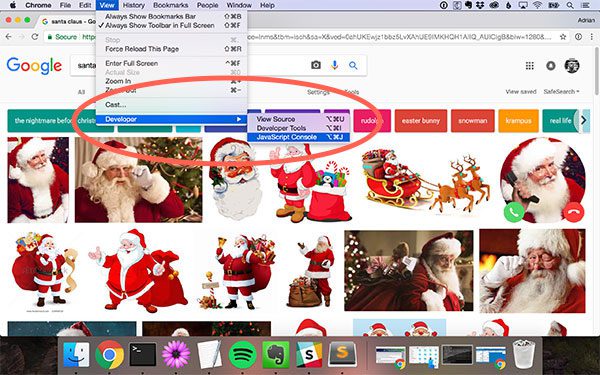
From there, click the Console tab:
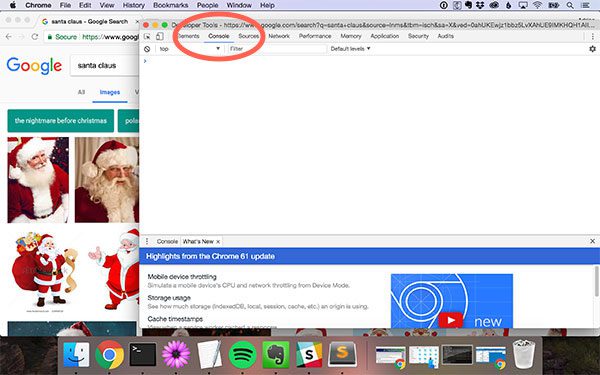
This will enable you to execute JavaScript in a REPL-like manner. The next step is to start scrolling!
Keep scrolling until you have found all relevant images to your query.
From there, we manually intervene with JavaScript. Switch back to the JavaScript console and copy + paste the following function into the console to simulate a right click on an image:
/**
* simulate a right-click event so we can grab the image URL using the
* context menu alleviating the need to navigate to another page
*
* attributed to @jmiserez: http://pyimg.co/9qe7y
*
* @param {object} element DOM Element
*
* @return {void}
*/
function simulateRightClick( element ) {
var event1 = new MouseEvent( 'mousedown', {
bubbles: true,
cancelable: false,
view: window,
button: 2,
buttons: 2,
clientX: element.getBoundingClientRect().x,
clientY: element.getBoundingClientRect().y
} );
element.dispatchEvent( event1 );
var event2 = new MouseEvent( 'mouseup', {
bubbles: true,
cancelable: false,
view: window,
button: 2,
buttons: 0,
clientX: element.getBoundingClientRect().x,
clientY: element.getBoundingClientRect().y
} );
element.dispatchEvent( event2 );
var event3 = new MouseEvent( 'contextmenu', {
bubbles: true,
cancelable: false,
view: window,
button: 2,
buttons: 0,
clientX: element.getBoundingClientRect().x,
clientY: element.getBoundingClientRect().y
} );
element.dispatchEvent( event3 );
}
This function effectively simulates right clicking on an image shown in your browser. Notice how the click involves dispatching both a mousedown and mouseup event followed by activating the context menu.
Next we’ll define a function to extract the URL:
/**
* grabs a URL Parameter from a query string because Google Images
* stores the full image URL in a query parameter
*
* @param {string} queryString The Query String
* @param {string} key The key to grab a value for
*
* @return {string} value
*/
function getURLParam( queryString, key ) {
var vars = queryString.replace( /^\?/, '' ).split( '&' );
for ( let i = 0; i < vars.length; i++ ) {
let pair = vars[ i ].split( '=' );
if ( pair[0] == key ) {
return pair[1];
}
}
return false;
}
Each image URL is stored in a query string. The snippet above pulls the URL out of the query.
Our next function assembles all the URLs in a convenient text file:
/**
* Generate and automatically download a txt file from the URL contents
*
* @param {string} contents The contents to download
*
* @return {void}
*/
function createDownload( contents ) {
var hiddenElement = document.createElement( 'a' );
hiddenElement.href = 'data:attachment/text,' + encodeURI( contents );
hiddenElement.target = '_blank';
hiddenElement.download = 'urls.txt';
hiddenElement.click();
}
Each of our URLs will be in the contents parameter passed to our createDownload function. Here we first create a hiddenElement. We then populate it with the contents, create a destination link with a filename of urls.txt, and simulate a click of the element.
Ultimately when the createDownload function runs, your browser will trigger a download. Depending on your browser settings, your download may go to your default download location or you may be prompted to select a name and location for your image URLs file download.
Our last function brings the components together:
/**
* grab all URLs va a Promise that resolves once all URLs have been
* acquired
*
* @return {object} Promise object
*/
function grabUrls() {
var urls = [];
return new Promise( function( resolve, reject ) {
var count = document.querySelectorAll(
'.isv-r a:first-of-type' ).length,
index = 0;
Array.prototype.forEach.call( document.querySelectorAll(
'.isv-r a:first-of-type' ), function( element ) {
// using the right click menu Google will generate the
// full-size URL; won't work in Internet Explorer
// (http://pyimg.co/byukr)
simulateRightClick( element.querySelector( ':scope img' ) );
// Wait for it to appear on the <a> element
var interval = setInterval( function() {
if ( element.href.trim() !== '' ) {
clearInterval( interval );
// extract the full-size version of the image
let googleUrl = element.href.replace( /.*(\?)/, '$1' ),
fullImageUrl = decodeURIComponent(
getURLParam( googleUrl, 'imgurl' ) );
if ( fullImageUrl !== 'false' ) {
urls.push( fullImageUrl );
}
// sometimes the URL returns a "false" string and
// we still want to count those so our Promise
// resolves
index++;
if ( index == ( count - 1 ) ) {
resolve( urls );
}
}
}, 10 );
} );
} );
}
Our grabUrls function creates what JavaScript calls a Promise. Given that this is a Python blog, I’ll draw parallels from JavaScript’s Promise to Python’s async / await — a similar concept which RealPython discusses and provides template for (for the inquisitive few).
The promise is that all image URLs will be obtained via the right-click context menu simulation.
Our final snippet which you need to paste into the Javascript console is what calls our grabUrls function:
/**
* Call the main function to grab the URLs and initiate the download
*/
grabUrls().then( function( urls ) {
urls = urls.join( '\n' );
createDownload( urls );
} );
Our main entry point to start execution is this call to grabUrls. Notice how each URL is joined by a newline character so that each URL is on its own line in the text file. As you can see, the createDownload function is called from here as the final step.
While this method calls our functions we defined in the JavaScript console directly, alternatively, you could use the logic to create a Chrome Browser plugin without too much hassle. This is left as an exercise for you to complete.
After executing the above snippet you’ll have a file named urls.txt in your default Downloads directory.
If you are having trouble following this guide, please see the video at the very top of this blog post where I provide step-by-step instructions. And as another reminder, the code shown above is an update to this blog post. The YouTube video at the top of this post will not and does not match this updated code, but the manual JavaScript console intervention is the same. Simply paste each snippet into the console until you have your URLs text file.
Downloading Google Images using Python
Now that we have our urls.txt file, we need to download each of the individual images.
Using Python and the requests library, this is quite easy.
If you don’t already have requests installed on your machine you’ll want to install it now (taking care to use the workon command first if you are using Python virtual environments):
$ workon cv $ pip install requests
From there, open up a new file, name it download_images.py , and insert the following code:
# import the necessary packages from imutils import paths import argparse import requests import cv2 import os
Here we are just importing required packages. Notice requests on Line 4 — this will be the package we use for downloading the image content.
Next, we’ll parse command line arguments and load our urls from disk into memory:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-u", "--urls", required=True,
help="path to file containing image URLs")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
# grab the list of URLs from the input file, then initialize the
# total number of images downloaded thus far
rows = open(args["urls"]).read().strip().split("\n")
total = 0
Command line argument parsing is handled on Lines 9-14 — we only require two:
--urls: The path to the file containing image URLs generated by the Javascript trick above.--output: The path to the output directory where we’ll store our images downloaded from Google Images.
From there, we load each URL from the file into a list on Line 18. We also initialize a counter, total , to count the files we’ve downloaded.
Next we’ll loop over the URLs and attempt to download each image:
# loop the URLs
for url in rows:
try:
# try to download the image
r = requests.get(url, timeout=60)
# save the image to disk
p = os.path.sep.join([args["output"], "{}.jpg".format(
str(total).zfill(8))])
f = open(p, "wb")
f.write(r.content)
f.close()
# update the counter
print("[INFO] downloaded: {}".format(p))
total += 1
# handle if any exceptions are thrown during the download process
except:
print("[INFO] error downloading {}...skipping".format(p))
Using requests , we just need to specify the url and a timeout for the download. We attempt to download the image file into a variable, r , which holds the binary file (along with HTTP headers, etc.) in memory temporarily (Line 25).
Let’s go ahead and save the image to disk.
The first thing we’ll need is a valid path and filename. Lines 28 and 29 generate a path + filename, p , which will count up incrementally from 00000000.jpg .
We then create a file pointer, f , specifying our path, p , and indicating that we want write mode in binary format ("wb" ) on Line 30.
Subsequently, we write our files contents (r.content ) and then close the file (Lines 31 and 32).
And finally, we update our total count of downloaded images.
If any errors are encountered along the way (and there will be some errors — you should expect them whenever trying to automatically download unconstrained images/pages on the web), the exception is handled and a message is printed to the terminal (Lines 39 and 40).
Now we’ll do a step that shouldn’t be left out!
We’ll loop through all files we’ve just downloaded and try to open them with OpenCV. If the file can’t be opened with OpenCV, we delete it and move on. This is covered in our last code block:
# loop over the image paths we just downloaded
for imagePath in paths.list_images(args["output"]):
# initialize if the image should be deleted or not
delete = False
# try to load the image
try:
image = cv2.imread(imagePath)
# if the image is `None` then we could not properly load it
# from disk, so delete it
if image is None:
delete = True
# if OpenCV cannot load the image then the image is likely
# corrupt so we should delete it
except:
print("Except")
delete = True
# check to see if the image should be deleted
if delete:
print("[INFO] deleting {}".format(imagePath))
os.remove(imagePath)
As we loop over each file, we’ll initialize a delete flag to False (Line 45).
Then we’ll try to load the image file on Line 49.
If the image is loaded as None , or if there’s an exception, we’ll set delete = True (Lines 53 and 54 and Lines 58-60).
Common reasons for an image being unable to load include an error during the download (such as a file not downloading completely), a corrupt image, or an image file format that OpenCV cannot read.
Lastly if the delete flag was set, we call os.remove to delete the image on Lines 63-65.
That’s all there is to the Google Images downloader script — it’s pretty self-explanatory.
To download our example images, make sure you use the “Downloads” section of this blog post to download the script and example urls.txt file.
From there, open up a terminal and execute the following command:
$ python download_images.py --urls urls.txt --output images/santa [INFO] downloaded: images/santa/00000000.jpg [INFO] downloaded: images/santa/00000001.jpg [INFO] downloaded: images/santa/00000002.jpg [INFO] downloaded: images/santa/00000003.jpg ... [INFO] downloaded: images/santa/00000519.jpg [INFO] error downloading images/santa/00000519.jpg...skipping [INFO] downloaded: images/santa/00000520.jpg ... [INFO] deleting images/santa/00000211.jpg [INFO] deleting images/santa/00000199.jpg ...
As you can see, example images from Google Images are being downloaded to my machine as training data.
The error you see in the output is normal — you should expect these. You should also expect some images to be corrupt and unable to open — these images get deleted from our dataset.
Pruning irrelevant images from our dataset
Of course, not every image we downloaded is relevant.
To resolve this, we need to do a bit of manual inspection.
My favorite way to do this is to use the default tools on my macOS machine. I can open up Finder and browse the images in the “Cover Flow” view:
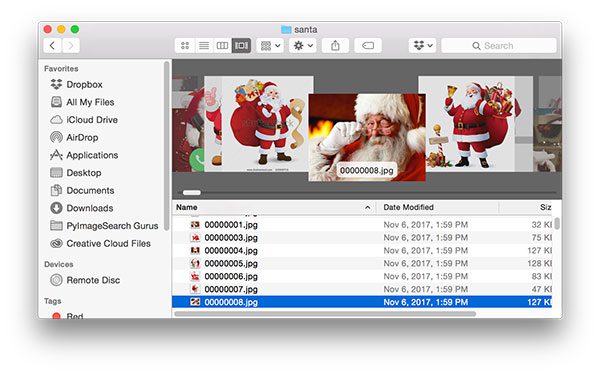
I can then easily scroll through my downloaded images.
Images that are not relevant can easily moved to the Trash using <cmd> + <delete> — similar shortcuts exist on other operating systems as well. After pruning my downloaded images I have a total of 461 images as training to our Not Santa app.
In next week’s blog post I’ll demonstrate how we can use Python and Keras to train a Convolutional Neural Network to detect if Santa Clause is in an input image.
The complete Google Images + deep learning pipeline
I have put together a step-by-step video that demonstrates me performing the above steps to gather deep learning training data using Google Images.
Be sure to take a look!
Note: Keep in mind that this video was created in 2017 to accompany the original article; however, this blog post has now been updated in April 2020. While the methodology using your browser’s javascript console is the same, the JavaScript slightly different, new, and improved.
Wondering about duplicate images in your dataset?
As you scroll through your new local dataset you’re probably thinking:
So how do I get rid of all these duplicate images? Will they affect my deep learning model at training time?
There will be duplicate images in your dataset using the Google Images method. There’s no way around it.
And if you leave them in for your training exercise, your model may form a bias towards a particular image it sees multiple times.
At this point you need to de-duplicate your dataset.
You could, of course, manually remove the duplicates, but that would take time that most of us don’t have.
Therefore, head on over to my tutorial on how to Detect and remove duplicate images from a dataset for deep learning. There, you will learn what image hashing is and how it will help you to automatically remove duplicates with a simple Python script.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post you learned how to:
- Use Google Images to search for example images.
- Grab the image URLs via a small amount of JavaScript.
- Download the images using Python and the requests library.
Using this method we downloaded ~550 images.
We then manually inspected the images and removed non-relevant ones, trimming the dataset down to ~460 images.
In next week’s blog post we’ll learn how to train a deep learning model that will be used in our Not Santa app.
To be notified when the next post in this series goes live, be sure to enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

