Last updated on July 4, 2021.

Today I’m going to share a little known secret with you regarding the OpenCV library:
You can perform fast, accurate face detection with OpenCV using a pre-trained deep learning face detector model shipped with the library.

You may already know that OpenCV ships out-of-the-box with pre-trained Haar cascades that can be used for face detection…
…but I’m willing to bet that you don’t know about the “hidden” deep learning-based face detector that has been part of OpenCV since OpenCV 3.3.
In the remainder of today’s blog post I’ll discuss:
- Where this “hidden” deep learning face detector lives in the OpenCV library
- How you can perform face detection in images using OpenCV and deep learning
- How you can perform face detection in video using OpenCV and deep learning
As we’ll see, it’s easy to swap out Haar cascades for their more accurate deep learning face detector counterparts.
To learn more about face detection with OpenCV and deep learning, just keep reading!
- Update July 2021: Included a new section on alternative face detection methods you may want to consider for your projects.
Face detection with OpenCV and deep learning
Today’s blog post is broken down into three parts.
In the first part we’ll discuss the origin of the more accurate OpenCV face detectors and where they live inside the OpenCV library.
From there I’ll demonstrate how you can perform face detection in images using OpenCV and deep learning.
I’ll then wrap up the blog post discussing how you can apply face detection to video streams using OpenCV and deep learning as well.
Where do these “better” face detectors live in OpenCV and where did they come from?
Back in August 2017, OpenCV 3.3 was officially released, bringing it with it a highly improved “deep neural networks” (dnn ) module.
This module supports a number of deep learning frameworks, including Caffe, TensorFlow, and Torch/PyTorch.
The primary contributor to the dnn module, Aleksandr Rybnikov, has put a huge amount of work into making this module possible (and we owe him a big round of thanks and applause).
And since the release of OpenCV 3.3, I’ve been sharing a number of deep learning OpenCV tutorials, including:
- Deep Learning with OpenCV
- Object detection with deep learning and OpenCV
- Real-time object detection with deep learning and OpenCV
- Deep learning on the Raspberry Pi with OpenCV
- Raspberry Pi: Deep learning object detection with OpenCV
- Deep learning: How OpenCV’s blobFromImage works
However, what most OpenCV users do not know is that Rybnikov has included a more accurate, deep learning-based face detector included in the official release of OpenCV (although it can be a bit hard to find if you don’t know where to look).
The Caffe-based face detector can be found in the face_detector sub-directory of the dnn samples:

When using OpenCV’s deep neural network module with Caffe models, you’ll need two sets of files:
- The .prototxt file(s) which define the model architecture (i.e., the layers themselves)
- The .caffemodel file which contains the weights for the actual layers
Both files are required when using models trained using Caffe for deep learning.
However, you’ll only find the prototxt files here in the GitHub repo.
The weight files are not included in the OpenCVsamples directory and it requires a bit more digging to find them…
Where can I can I get the more accurate OpenCV face detectors?
For your convenience, I have included both the:
- Caffe prototxt files
- and Caffe model weight files
…inside the “Downloads” section of this blog post.
To skip to the downloads section, just click here.
How does the OpenCV deep learning face detector work?
OpenCV’s deep learning face detector is based on the Single Shot Detector (SSD) framework with a ResNet base network (unlike other OpenCV SSDs that you may have seen which typically use MobileNet as the base network).
A full review of SSDs and ResNet is outside the scope of this blog post, so if you’re interested in learning more about Single Shot Detectors (including how to train your own custom deep learning object detectors), start with this article here on the PyImageSearch blog and then take a look at my book, Deep Learning for Computer Vision with Python, which includes in-depth discussions and code enabling you to train your own object detectors.
Face detection in images with OpenCV and deep learning
In this first example we’ll learn how to apply face detection with OpenCV to single input images.
In the next section we’ll learn how to modify this code and apply face detection with OpenCV to videos, video streams, and webcams.
Open up a new file, name it detect_faces.py , and insert the following code:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Here we are importing our required packages (Lines 2-4) and parsing command line arguments (Lines 7-16).
We have three required arguments:
--image: The path to the input image.--prototxt: The path to the Caffe prototxt file.--model: The path to the pretrained Caffe model.
An optional argument, --confidence , can overwrite the default threshold of 0.5 if you wish.
From there lets load our model and create a blob from our image:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# load the input image and construct an input blob for the image
# by resizing to a fixed 300x300 pixels and then normalizing it
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
First, we load our model using our --prototxt and --model file paths. We store the model as net (Line 20).
Then we load the image (Line 24), extract the dimensions (Line 25), and create a blob (Lines 26 and 27).
The dnn.blobFromImage takes care of pre-processing which includes setting the blob dimensions and normalization. If you’re interested in learning more about thednn.blobFromImage function, I review in detail in this blog post.
Next, we’ll apply face detection:
# pass the blob through the network and obtain the detections and
# predictions
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
To detect faces, we pass the blob through the net on Lines 32 and 33.
And from there we’ll loop over the detections and draw boxes around the detected faces:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box of the face along with the associated
# probability
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
We begin looping over the detections on Line 36.
From there, we extract the confidence (Line 39) and compare it to the confidence threshold (Line 43). We perform this check to filter out weak detections.
If the confidence meets the minimum threshold, we proceed to draw a rectangle and along with the probability of the detection on Lines 46-56.
To accomplish this, we first calculate the (x, y)-coordinates of the bounding box (Lines 46 and 47).
We then build our confidence text string (Line 51) which contains the probability of the detection.
In case the our text would go off-image (such as when the face detection occurs at the very top of an image), we shift it down by 10 pixels (Line 52).
Our face rectangle and confidence text is drawn on the image on Lines 53-56.
From there we loop back for additional detections following the process again. If no detections remain, we’re ready to show our output image on the screen (Lines 59 and 60).
Face detection in images with OpenCV results
Let’s try out the OpenCV deep learning face detector.
Make sure you use the “Downloads” section of this blog post to download:
- The source code used in this blog post
- The Caffe prototxt files for deep learning face detection
- The Caffe weight files used for deep learning face detection
- The example images used in this post
From there, open up a terminal and execute the following command:
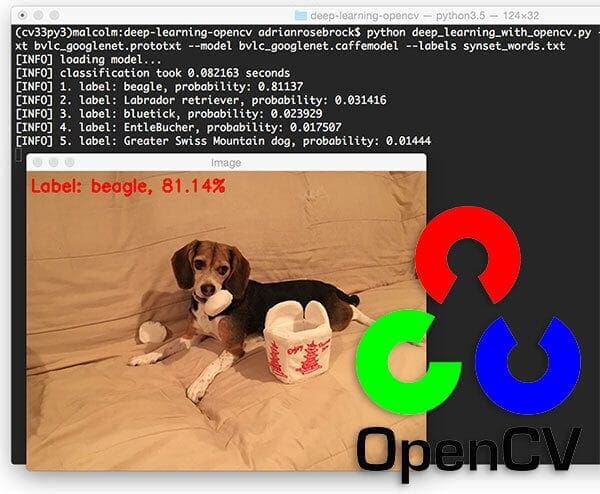
$ python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt \ --model res10_300x300_ssd_iter_140000.caffemodel

The above photo is of me during my first trip to Ybor City in Florida, where chickens are allowed to roam free throughout the city. There are even laws protecting the chickens which I thought was very cool. Even though I grew up in rural farmland, I was still totally surprised to see a rooster crossing the road — which of course spawned many “Why did the chicken cross the road?” jokes.
Here you can see my face is detected with 74.30% confidence, even though my face is at an angle. OpenCV’s Haar cascades are notorious for missing faces that are not at a “straight on” angle, but by using OpenCV’s deep learning face detectors, we are able to detect my face.
And now we’ll see how another example works, this time with three faces:
$ python detect_faces.py --image iron_chic.jpg --prototxt deploy.prototxt.txt \ --model res10_300x300_ssd_iter_140000.caffemodel

This photo was taken in Gainesville, FL after one of my favorite bands finished up a show at Loosey’s, a popular bar and music venue in the area. Here you can see my fiancée (left), me (middle), and Jason (right), a member of the band.
I’m incredibly impressed that OpenCV can detect Trisha’s face, despite the lighting conditions and shadows cast on her face in the dark venue (and with 86.81% probability!)
Again, this just goes to show how much better (in terms of accuracy) the deep learning OpenCV face detectors are over their standard Haar cascade counterparts shipped with the library.
Face detection in video and webcam with OpenCV and deep learning
Now that we have learned how to apply face detection with OpenCV to single images, let’s also apply face detection to videos, video streams, and webcams.
Luckily for us, most of our code in the previous section on face detection with OpenCV in single images can be reused here!
Open up a new file, name it detect_faces_video.py , and insert the following code:
# import the necessary packages
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Compared to above, we will need to import three additional packages: VideoStream , imutils , and time .
If you don’t have imutils in your virtual environment, you can install it via:
$ pip install imutils
Our command line arguments are mostly the same, except we do not have an --image path argument this time. We’ll be using our webcam’s video feed instead.
From there we’ll load our model and initialize the video stream:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
Loading the model is the same as above.
We initialize a VideoStream object specifying camera with index zero as the source (in general this would be your laptop’s built in camera or your desktop’s first camera detected).
A few quick notes here:
- Raspberry Pi + picamera users can replace Line 25 with
vs = VideoStream(usePiCamera=True).start()if you wish to use the Raspberry Pi camera module. - If you to parse a video file (rather than a video stream) swap out the
VideoStreamclass forFileVideoStream. You can learn more about the FileVideoStream class in this blog post.
We then allow the camera sensor to warm up for 2 seconds (Line 26).
From there we loop over the frames and compute face detections with OpenCV:
# loop over the frames from the video stream while True: # grab the frame from the threaded video stream and resize it # to have a maximum width of 400 pixels frame = vs.read() frame = imutils.resize(frame, width=400) # grab the frame dimensions and convert it to a blob (h, w) = frame.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0)) # pass the blob through the network and obtain the detections and # predictions net.setInput(blob) detections = net.forward()
This block should look mostly familiar to the static image version in the previous section.
In this block, we’re reading a frame from the video stream (Line 32), creating a blob (Lines 37 and 38), and passing the blob through the deep neural net to obtain face detections (Lines 42 and 43).
We can now loop over the detections, compare to the confidence threshold, and draw face boxes + confidence values on the screen:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence < args["confidence"]:
continue
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box of the face along with the associated
# probability
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
For a detailed review of this code block, please review the previous section where we perform face detection to still, static images. The code here is nearly identical.
Now that our OpenCV face detections have been drawn, let’s display the frame on the screen and wait for a keypress:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
We display the frame on the screen until the “q” key is pressed at which point we break out of the loop and perform cleanup.
Face detection in video and webcam with OpenCV results
To try out the OpenCV deep learning face detector make sure you use the “Downloads” section of this blog post to grab:
- The source code used in this blog post
- The Caffe prototxt files for deep learning face detection
- The Caffe weight files used for deep learning face detection
Once you have downloaded the files, running the deep learning OpenCV face detector with a webcam feed is easy with this simple command:
$ python detect_faces_video.py --prototxt deploy.prototxt.txt \ --model res10_300x300_ssd_iter_140000.caffemodel
You can see a full video demonstration, including my commentary, in the following video:
Other face detection methods to consider
This tutorial covered how to use OpenCV’s “hidden” pre-trained deep learning face detector. This model is a good balance of both speed and accuracy.
However, there are other face detection methods that you may want to consider for your projects:
- Face detection with Haar cascades: Extremely fast but prone to false-positives and in general less accurate than deep learning-based face detectors
- Face detection with dlib (HOG and CNN): HOG is more accurate than Haar cascades but computationally more expensive. Dlib’s CNN face detector is the most accurate of the bunch but cannot run in real-time without a GPU.
- Multi-task Cascaded Convolutional Networks (MTCNNs): Very accurate deep learning-based face detector. Easily compatible with both Keras and TensorFlow.
Finally, I highly suggest you read my Face detection tips, suggestions, and best practices tutorial where I detail the pros and cons of each face detection method.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post you discovered a little known secret about the OpenCV library — OpenCV ships out-of-the-box with a more accurate face detector (as compared to OpenCV’s Haar cascades).
The more accurate OpenCV face detector is deep learning based, and in particular, utilizes the Single Shot Detector (SSD) framework with ResNet as the base network.
Thanks to the hard work of Aleksandr Rybnikov and the other contributors to OpenCV’s dnn module, we can enjoy these more accurate OpenCV face detectors in our own applications.
The deep learning face detectors can be hard to find in the OpenCV library, so
for your convenience, I have gathered the Caffe prototxt and weight files for you — just use the “Downloads” form below to download the (more accurate) deep learning-based OpenCV face detector.
See you next week with another great computer vision + deep learning tutorial!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

How well does the new OpenCV model recognize faces of various skin tones? Do we know how it was trained?
I have not performed an exhaustive evaluation for various skin tones so I’m not sure. That would make for a interesting article. If I cannot write one I would love to see one written by a PyImageSearch reader. The GitHub repo has more information on the training process.
hai adrian, how are you,
by the way i am getting an error ” usage: face_001.py [-h] -p PROTOTXT -m MODEL [-c CONFIDENCE]
face_001.py: error: the following arguments are required: -p/–prototxt, -m/–model”
while i copied the sam code for streaming in oythin
Kindly read up on command line arguments and your error will be resolved 🙂
Try to run it as shown in the tutorial, That mean, type in all the arguments asked. lastly one error I had struggled to fix, in case you’re facing it was, the file name i passed couldn’t be read when passed in as shown in the tutorial(am using Window OS), so I’ve used the assignment operator and it worked.
example –prototxt=deploy.prototxt.txt –model=………and so on, try that if you encounter a read Model error. In addition, much appreciated your generosity @Adrian Rosebrock for giving us this course for free, this information worth a price.
Hi,
I Have learnd your content that Face detection with OpenCV and deep learning.It is very useful to me. I thank you very much. But, I still want to ask ,is there any content about multi-frame information fusion on Video face detection?
Empirically it’s showing a fairly stark training bias towards the lightest faces (not just lighter). It hallucinates faces in concrete, flowers, car wheels, maple tree leaves while missing out actual dark toned faces. This is for high resolution images (4MP-8MP), where peoples faces end up being relatively small. Tried at various scales, but doesn’t change the results.
Not surprising as most of the face data sets seem to reflect this bias, despite some clear attempts to include diversity.
what’s different this method with haar cascade’s face detection ?
This method uses deep learning, in particular a Single Shot Detector (SSD) with ResNet base network architecture. That is the difference.
Hi Adrian, big fan of your blog. I was amazed when I tried out the results myself! Saved me a lot of hassle. However, I was wondering how I could add a face recognition feature on top of this. Would help a lot if you could explain. Cheers!
Hey Sampreet, I’ll likely be covering facial recognition soon but I would also suggest taking a look at the PyImageSearch Gurus course where I cover facial recognition in depth.
hey Adrian!I want to know why detections[0, 0, i, 2] can respect the confidence and how could we draw a rectangle ?it troubles me so long and i really want to know what does the function net.forward() return.
Hi Adrian ,
This is amazing code and its wonderful as its working great on one of my video , I would be happy to learn more about how exactly the model was trained more about its architecture , Please suggest .
Thanks in Advance ,
Palbha
What’s the difference of this implementation compared to YOLO face detection in terms of performance?
https://pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
Sounds nice, but how is the the performance? There are a lot of face detection frameworks but they are not even near real time.
Please see the video where I provide a live demonstration. This face detector can be used in real-time.
Thanks for the reply, Adran! I think it is still a bit slow for our family album including 40k pictures, but it is worth a trial then 🙂
Hi Adrian, nice to know ..is this detector faster than dlib’s detector? thanks much!
I haven’t tested them side-by-side, but it should be comparably fast to dlib’s HOG + Linear SVM detector.
Hey Adrian,
First off, I want to thank you for the great work you’ve done so far. Your blog is the basis for the computer vision startup we’re founding.
Coming back to this specific blog post, I haven’t tested it yet, but how do you think the speed of this DNN will compare to Haar cascades on a Raspberry Pi? On my computer, I’m seeing about a 25% slowdown.
Which would you choose for detecting faces on a Pi where both speed and accuracy were equally important?
Haar cascades will be the fastest here, but the deep learning face detector will give you the most accuracy. As for which one to choose, that really depends on your project. If you’re looking to detect faces that will naturally have more variability in viewing angle, use the deep learning detector. If the faces will almost always be “straight on” then the Haar cascades will likely be sufficient. Again, it really depends on the project.
Comparing the two, the deep learning method takes typically more than ten times as the Haar cascade method on my RPi. I have a haar cascade function (working on a somewhat smaller image and converted to grayscale), taking about .06 second to process a single frame; for the deep learning function is taking about .68 second. Also CPU usage is about 11% for the haar cascade, and about 43% for the deep learning method.
For my purpose (face tracking — panning/tilting the camera as you move, for example), it is great having detection that works other than straight on perspectives. For that it is the preferable technique. But at the same time, I am concerned about having resources for other concurrent tasks. What ways may there be to better tune the deep learning algorithm, if any?
You mean tune the deep learning model for faster predictions?
Not sure about Haar cascades but this deepnet runs on my rpi3 at about 1fps, maybe a bit slower. So that is still usable for some projects although difficult for realtime applications. I am trying to control servos of a pan tilt camera mount and there is so much delay in the feedback loop that it is tricky to manage (if you guys have a suggestion of an algo that is robust to such delay I would take it).
Tks Andrian for the great tutorial, as always.
This is awesome to hear OpenCV now ships with the dnn module.
If you wanted to take this a step further to start recognizing particular faces, would you have to go back to deep learning to actually teach the faces? Would there be a way to leverage this to assist in the collection of labeled samples?
Thanks!
Facial recognition is a two stage process. The first stage is detecting the presence of a face in an image but not knowing “who” the actual face is. The second stage is taking each detected face and recognizing it. For this, you would need a dedicated facial recognition algorithm. I actually discuss how to create a Python script to assist in collecting labeled faces (as you suggested) inside the PyImageSearch Gurus course. From there you’ll be able to build your own facial recognizer.
One of the post I was eagerly looking for. Thanks adrian for this post. You are the best when it comes to computer vision.
Thank you swapnil! 🙂
Very nice !!!! I look forward to playing with this example.
Now how do we train this deep model to recognize “Our” faces 😉
I think this is in the right direction and away from eigenfaces which I noticed don’t seem to be accurate. (Not an exhaustive test on my part) I can still see using a har cascade in front of the this deep learning SSD. Har is so fast I think the two algo stacked together make sense.
Thanks again !!!!
There are a bunch of ways to perform face recognition using deep learning. One of my favorites is to use deep learning embeddings of the faces. I’ll cover this is well in the future.
Hi Adrian. Thanks for the great tutorial!
Thanks so much Phillity, I’m happy you enjoyed it! 🙂
great tutorial!!!!
Thank you Ray, I’m glad you enjoyed it! 🙂
first off, great tut as usual ! excellent !
i wonder if there are some helper functions accompanying with the package that i can use to extract extra information of face’s parts like : eyes, nose, ears , forehead … positions .
If not then is there any packages to do such extraction after detecting using this dnn
thanks
It sounds like you’re referring to facial landmarks. See this post for more details, including code.
You have explained well about face detection in opencv but can we use opencv deep learning faces for landmark detection i means can you help me in this that i give image as an input to opencv caffee model and it return me array of faces which can be passed one by one to the dlib landmarks detector?
Your deep learning face detector will give you the bounding boxes of the faces. Loop over the faces one-by-one and then pass into into dlib’s landmark detector function.
Thank you for your efforts and sharing.
I really like to read your posts!!
Thanks Han, I’m glad you’re enjoying them!
Great, Is there something new for full body detection?
What specifically regarding full body detection? Detecting the presence of a body in an image? Localizing each of the arms, legs, joints, etc.?
Thanks Adrian,
Brilliant stuff as usual, I managed to replicate that in C++ but still very slow on my RPi.
Any idea if Movidius stick can be used to boost the recognition part here?
Regards,
Mark
I haven’t tried this code on the Movidius but from the previous post I used a Caffe model weights + architecture for a MobileNet + SSD. It seems to reason that a ResNet + SSD would work as well. I would try loading the face detector via the Movidius but I get the feeling that you might have to work with it a bit.
Hi
Adrian ,Could you post a post article about this? I have a little trouble with movidius
I’ll be covering both face detection and face recognition using the Movidius in my upcoming Raspberry Pi + Computer Vision book. Stay tuned!
Hi Adrian
thanks again for your amazing articles!
When are you going to release the book on Raspberry PI and Movidius?
I want to implement an edge based face recognition system, and Movidius looks like the right choice.
I’ll be releasing it later in 2019! 🙂 We’ll be doing face recognition with Movidius inside the book as well.
Adrian, thank you for this post and some excellent insight into OpenCV. Can you elaborate on why you chose to use the VideoStream feature of imutils? I have a non-traditional set up (Rpi3 with custom ARM64 (aarch64) kernel. I’ve compiled OpenCV and everything looks good there but the imutils – vs.read() call is returning null. I was thinking about going to OpenCV.videoCapture but thought I would ask the above question before I started. Thanks!
The VideoStream is my implementation of a faster, threaded frame polling class. It is compatible with both USB/built-in webcams along with the Raspberry Pi camera module. You could use OpenCV’s cv2.VideoCapture function but you’ll get an extra performance boost from VideoStream which is a must when working with the Raspberry Pi. You can read more about the VideoStream class here.
Hey Adrian,
I find the tutorial very useful with the differences between SSD and HOG detection are night and day. Can you suggest me where I can find the Face Recognition Using Deep Learning in OpenCV? Thanks!
Hey Anish — I cover face recognition inside the PyImageSearch Gurus course. You can also work through Deep Learning for Computer Vision with Python where I discuss how to train your own networks on custom datasets (such as faces).
This is super cool Adrian. It is very reliable. In traditional face detection, I have had issues when the face leaves the frame and re-enters. This is so exciting. Thank you so very much for writing this blog.
Thanks Dominic, I’m glad you enjoyed the post! 🙂
Hi Adrian,
Thanks for your great article. It’s really helpful! I have couple of notes based on my observation while testing your code.
I am writing now my thesis at Amsterdam University of Applied Sciences, and it’s about Facial detection and recognition on children. My target group is children aged between 0 and 12 years old.
I am stil busy with researching, but I tried your code just to build a fast proof-of-concept and it didn’t work well in the beginning. I have adjusted 3 parameters and it did it well.
Those parameters were:
1) –confidence, which is now 0.40
2) x and y while calling cv2.dnn.blobFromImage(). In your original code it’s 300*300 in my code I just changed to be the height of the input image.
Here is the result of the running your code without changing anything
https://imgur.com/a/BdcPl
here the result after changing the parameters (the confidence doesn’t matter 0.4 or 0.5)
https://imgur.com/a/QQFrN
Do you have any explanation?
Kind regards, Peshmerge
The confidence is the minimum probability. It is used to filter out weak(er) detections. You can set the confidence as you see best fit for your project/application.
Thanks for you reply! To be honest adjusting the x and y just made the difference for me! I wonder why did you choose to give it 300*300?
300×300 is the typical input image size for SSDs and Faster R-CNNs.
hey Adrian
I applied the same code on my raspberry pi 3 but it work very slowly and reboot after few scond each time I run the code
Hey Amal — the OpenCV deep learning face detector will certainly run slow on the Pi. For fast, but less accurate face detection you should use Haar cascades. As for the Pi automatically rebooting, I’m not sure what the problem is. It sounds like a hardware problem or your Pi is overheating.
Hi Adrian,
Is there a good way to covert Caffe based code to Keras? Using Caffe in the production os kind of hassle.
thanks,
Ed.
I would start by going through this resource which includes a number of deep learning model/weight converters.
I tried to run the compiled graph on movidius, but I’am a little bit confused about the retruned value from graph.GetResult(): an array of shape (1407,)!
For sure a made some mistake…
The output has to be interpreted as in https://pyimagesearch.com/2018/02/19/real-time-object-detection-on-the-raspberry-pi-with-the-movidius-ncs/
The array of 1407 is right. The first element (output[0]) is a number describing all valid boxes found.
But I still get a dinfferent output on my computer… The bounding boxes are not in the right position and the max confidence is around 40%
Any tips on where that could come from or where to look?
Regards =)
Hi Adrian
This is a bit off topic, but I was wondering if you would be so kind as to write an article on making a “people counting” with OpenCV — that is, a program that counts people going in and out of a building via a live webcam feed. There are no great resources available online for this, so if you would write one I’m sure it would drive plenty of traffic to your site. It’s a win for both of us!
Thanks
Thank you for the suggestion. I will certainly consider it for the future.
Some folks have trained a head detector for people counting to get around occlusion issues…
hi
I am new to OpenCV it would be a great help if you tell how to add the path in argument parse (line 8 in the code)
Take a look at this post to get started with command line arguments.
hi, can someone help me with this error:
[INFO] loading model…
[INFO] starting video stream…
Traceback (most recent call last):
…
(h, w) = image.shape[:2]
AttributeError: ‘NoneType’ object has no attribute ‘shape’
OpenCV cannot access your webcam. See this post for more details.
This code is not working for a group photo with 50 people.
That’s not too surprising. If there are 50 people in the photo the faces are likely very small. Try increasing the resolution of the image before passing it into the network for detection.
I want to create my own training set. How to train my own neural network in python for my college project?
I demonstrate how to train your first Convolutional Neural Network in this post. I would suggest starting there. If you’re interested in a deeper dive and understanding of how to train your own custom networks I would suggest Deep Learning for Computer Vision with Python where I discuss deep learning + computer vision in detail (including how to train your own custom networks). I hope that helps point you in the right direction!
This means that these files are not opensource and we can’t generate these files by own and using these files will create copyright issue?
You would need to check the license associated with each model you wanted to use. Some are allowed for open source projects, others are just academic, and some do not allow commercial use. Typically if you wanted to use a model without restrictions you would need to train it yourself.
Congratulations Adrian, great post.
I am Brazilian would like to know if it has a way to decrease the quality of the image, or the frames per second, it was very slow running on the raspberry
This method really isn’t meant to be ran on the Raspberry Pi. You can decrease the resolution of the input image but it will still be too slow. See this post for more details. For the Raspberry Pi you should consider using Haar cascades if you need speed.
Can you please tell me what went wrong?
[INFO] loading model…
OpenCV(3.4.1) Error: Unspecified error (FAILED: fs.is_open(). Can’t open “res10_300x300_ssd_iter_140000.caffemode”) in ReadProtoFromBinaryFile, file /home/pi/opencv-3.4.1/modules/dnn/src/caffe/caffe_io.cpp, line 1126
Traceback (most recent call last):
File “detect_faces.py”, line 23, in
net = cv2.dnn.readNetFromCaffe(args[“prototxt”], args[“model”])
(-2) FAILED: fs.is_open(). Can’t open “res10_300x300_ssd_iter_140000.caffemode” in function ReadProtoFromBinaryFile
It looks like your path to the input .caffemodel file is incorrect. This is most likely due to not correctly specifying the command line arguments path. If you’re new to command line arguments, that’s okay, but you should read up on them first.
first copy and paste in the cmd the `python detect_faces.py –image rooster.jpg –prototxt deploy.prototxt.txt` and then do the same with the rest `–model res10_300x300_ssd_iter_140000.caffemodel`
please let us know how to add PROTOTXT and MODEL path
Take a look at command line arguments.
Hi,Adrian,Thank you very much for your generosity.I am very fortunate to meet you here.
I read carefully your blogs about object detection and pi project many times.It is undeniable that these has helped me very much and has given me a lot of inspiration.I admire your knowledge and ability, I almost became your fan.
I‘m a ’sophomore and I am really interested in computer vision.I want to train my object detection model In defining the scene after read your blog three weeks ago(Real-time object detection with deep learning and OpenCV),it’s great and very funny.so I use these days to search about object detection papers amd I know YOLO SSD are great. so I successfully configured the environment about caffe-ssd(git clone https://github.com/weiliu89/caffe.git ) on Ubuntu16.04 .It can run about ssd_pascal_webcam.py and ssd_pascal_video.py, but when I run exmples/ssd/ssd_pascal.py to train pascal VOC data,I got an error.I spent three days trying to fix this error. I can’t remember how many times it was recompiled, but the problem persists. I asked Github but I didn’t get a reply.(The error issues:https://github.com/weiliu89/caffe/issues/875)
I remember I received your patient reply. It feels warm. I would like you to take a look at this error and give me some advice to work it if you have time and like to do.Thanks again.
Hey Chopin — thank you for the kind words, I really appreciate that. Your comment really made my day 🙂
While I’ve used Caffe quite a bit to train image classification networks I must admit that I have not used it to build an LMDB database and train it for object detection via an SSD so I’m not sure what the exact error is. Most of the work I’ve done with object detection involve either Keras, mxnet, or the TensorFlow Object Detection API (TFOD API). I would recommend starting with the TFOD API to get your feet wet.
Hi Adrian,
I tried this code using the Movidius and the Raspberry Pi. I interpreted the output similar to this post of yours:
https://pyimagesearch.com/2018/02/19/real-time-object-detection-on-the-raspberry-pi-with-the-movidius-ncs/
Unfortunately the face/faces are not detected in the right positions. The maximum confidence of all bounding boxes is around 40 %.
Any advice on how I can update the model for usage on the Movidius?
Thanks a lot!
Hey Cedric — are you confident that it’s the model itself? If the bounding boxes are in an incorrect position there might be a bug in decoding the (x, y)-coordinates from the model.
Hi Adrian,
I did the same try, and got an (1407,) array. the result structure is strange. Do you have any example for this caffe model? I think it maybe movidius isse.
This definitely sounds like a Movidius issue; however, I must admit that I’m not sure what the error is.
Hey Adrian ! Everytime I’m looking for some help on a computer vision project, I come back to one of your tutorials. They are just excellent, clear and complete ! Thanks a lot for this you’re really helping me !
Thanks so much Martin, I really appreciate that! 🙂
I tried the script and overall it works well. However, I noticed that when I moved my face to be very close to my camera, it started drawing a second rectangle adjacent to the correctly identified one. This issue appeared more easily (meaning that the distance between the face and the camera is shorter) when I increase the image size of the frame input (e.g. from width=300 -> width=300) to cv2.dnn.blobFromImage. Any advice on why it’s happening and how to fix would be much appreciated!
Object detectors are not perfect so you are bound to see some false-positives. The SSD algorithm works (at a very simplistic level) by dividing your image into boxes and classifying each of them, class-wise. Since your face most of the frame being close up to the camera, there are likely a large number of boxes that contain face-like regions. This would imply why you may see a detection adjacent to the real one.
so,is there any ways to fix the problem?
I found that if I change the size input for blob with the same model, the performance changes a lot. I solved this by simple initializing a new model if I want to perform inference on images with a new size.
Hey Adrian ! Thanks again for this post, it is great !
I need to recognize smaller faces on my video stream. Is it possible to adjust some parameters here to fit my problem without training my own model ? Maybe something in the blobToImage function ? I lack time and compute power.
Yes, you’ll want to modify this line:
And change it o:
blob = cv2.dnn.blobFromImage(cv2.resize(image, (NEW_WIDTH, NEW_HEIGHT)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
Using the larger values.
Cool thanks ! I also read the blob tutorial but I didn’t really get why you need to resize the image. Also, what is the other size parameter (the provided (300,300) ) ?
should this size match the resize image ?
It’s interesting that all the folks that tried the code are getting decent results with an obviously incorrect mean value 🙂
Just for fun I tried 177 instead of the 117 it should have been. The results are the same, so doesn’t look like the color norm is doing much to skew inference results. Maybe only useful to converge better during training..
I am noticing the same thing.
Hi Adrian,
I have a question! Can I give feedback back to OpenCV to edit the model? I will explain what I mean. For example, I run the program on an image to detect faces, but what I get is that one of the detected objects isn’t a face, the program just identify it as a face. Is there a way which I can return value/parameter back to the program such that it edit it’s model and learn that that detected object isn’t a face so that it will correct itself!
I hope my question is clear!
Kind regards,
Peshmerge
There are less parameters to tune with the CNN-based detectors, as opposed to HOG + Linear SVM or Haar cascades, which is both a good thing and a bad thing. I would suggest trying different image sizes, both smaller and larger, to see if it has an impact on the quality of your detections.
Thanks Adrian!
drawing multiple boxes for single face
Hi,
I think that the mean value for the colors should be 104, 117, 123 instead of 104, 177, 123 (it is the mean value used in the training prototxt)
Hi Adrian,
Thanks again for the great post. I just have a simple question.
Which training dataset is used for this res10_300x300_ssd_iter_140000 model?
I have searched a lot online but the only thing I have found is this link : https://github.com/opencv/opencv/blob/master/samples/dnn/face_detector/how_to_train_face_detector.txt
The link says “The model was trained in Caffe framework on some huge and available online dataset.”
Do you know the dataset in which the model is trained?
Kind Regards
Yunui
I do not know off the top of my head. You would need to reach out to Aleksandr Rybnikov, the creator of the model and “dnn” module in OpenCV.
I asked him and it’s the WIDER face dataset. He blurred small <30px faces.
Thanks so much for checking, Andy!!
Face recognition is in the process of registering. If more than one person passes in front of the camera, faces are confused. How can I separate them? You help me.
You would need to detect both faces in the frame and identify each of them individually. Whatever model you are using for detection should localize each. If a face is too obfuscated you will not be able to recognize it.
Hi Adrian!
Is it possible to count the number of people in the screen at the same with this code? (Using a webcam)
Thx!
Mat
Yep. You can create a “counter” variable that counts the total number of faces. Something like:
count = 0 ... if confidence > args["confidence"]: count += 1 ...Would work well.
If you’re new to working with OpenCV and computer vision for these types of applications I would suggest reading through Practical Python and OpenCV. Inside you’ll learn the fundamentals of computer vision and image processing — I also include chapters on face counting as well which would resolve your exact question.
Now I want to display the serial number of face like “Face1” etc, or like the total number of faces being detected at a given instance , at the top of the video , how can I do that ?
You’ll want to use the
cv2.putTextfunction.Hello,
This is exactly what I’ve been looking for. But where exactly do you put it in the code? Every place I tried, it just starts counting non-stop.
Regards
Hi Adrian
Thanks for this great post.
If one wants to combine multiple detectors to get a higher accuracy, what approach do you suggest? Will it be useful?
Thanks
I’m not sure what you mean by “combine” in this context. Are you referring combining Haar cascades, HOG + Linear SVM, and deep learning-based detectors into a sort of “meta” detector?
Yes, how do we do that?
You would apply each of them independently and then apply non-maxima suppression.
Hi. I’m running the code on a google colab python notebook, with the required files uploaded to my drive. I’m getting the following output on running the code:
[INFO] loading model…
[INFO] computing object detections…
[ INFO:0] Initialize OpenCL runtime…
: cannot connect to X server
Please advise.
Great article, though.
I’m not familiar with the Google cloud setup here, but I assume the Google cloud notebook does not have an X server installed. You won’t be able to access your webcam or display a video stream using the notebook. I would suggest executing the code on your local system.
Hello, I need information on facial recognition and not just facial detection.
Can you help me?
Hey Pierre, thanks for the comment. I cover facial recognition inside the PyImageSearch Gurus course. Be sure to give it a look!
As usual a very good post. I have a question, what if I use Mobilenet for SSD, will it be faster than the given by Opencv, also what are the accuracy tradeoffs of using Mobilenet. Since we are pushing towards embedded system, what according to you is the best system to run on raspberry pi (with good accuracy)?
I would suggest you read the MobileNet and SSD papers to understand speed/accuracy tradeoffs. The gist is that using MobileNet as a base network to an SSD is typically faster but less accurate. Again, you’ll want to read the papers for more details.
Hey Adrian,
thanks so much for the useful tutorials and code! They helped me a lot. I have a somewhat weird question: is there any way to implement the 5-point landmark detection (from your later post: https://pyimagesearch.com/2018/04/02/faster-facial-landmark-detector-with-dlib/) with the deep learning face detection? Because the DL face detection works better with profile views of the face and this would be sth really useful for my research. Thanks for your help! Cheers
Yes. Once you have the bounding box coordinates of the face you can convert them to a dlib “rectangle” object and then apply the facial landmark detector. This post shows you how to do it but you’ll want to swap out the 68-point detector for the 5-point detector.
Is there some way to specify the camera to be used with the code? I have multiple cameras and want to specify the one for face detection. I am using a udev rule that creates a symlink for each camera, so that there are unique names for them, such as “/dev/vidFaceDetector”
I noticed that if I put the Ubuntu assigned name, such as “/dev/video1” into line 25, it works:
vs = VideoStream(‘/dev/video1’).start()
but putting in the symlink name does not:
vs = VideoStream(‘/dev/vidFaceDetector’).start()
but the Ubuntu assigned name changes, so it is no more useful than just the index number.
here is the error that occurs when using the symlink:
[INFO] starting video stream…
Unable to stop the stream: Inappropriate ioctl for device
Sorry for the string of replies, there does not seem to be a way to edit the original one.
I tried to see if I could get the ubuntu assigned name from the symlink using
for camera in glob.glob(“/dev/vid*”):
print(camera, os.readlink(camera))
but the output is the bus address:
/dev/vidFaceDetector bus/usb/001/006
Is there a way to map the bus address to the corresponding “/dev/videoX” device?
This is a great question and I remember another reading asking the same question on another blog post. To be totally candid I do not know the solution to this problem as I’ve never encountered it but it apparently does happen. I would suggest either (1) posting on the official OpenCV forums or (2) opening an Issue on OpenCV’s GitHub.
If you do find out the solution can you come back and post it on this thread so others can learn from it as well?
Thanks so much!
Hi,
I can make your code work by adjusting (300, 300) to the size of images I have and it is normally working perfectly. However now I have to use 12 MP (4056×3040) images. I adjusted the size argument in blobFromImage function in the same way I used to, but somehow it is not working anymore. I also tried to adjust the input_shape part in deploy.prototxt.txt file but I couldn’t get any result.
Do you have any advice for this problem ?
Thanks so much
Correct, this network is fully convolutional so you can update the size of the input images and it should still work. As far as your 12MP images go, I’m not sure what the problem is there. What were the previous image sizes you were using that the network was still working?
Hi Adrian,
Thanks for the awesome article! However, I was unable to understand why did the detect_faces.py would only detect faces. There are only 2 things that seem to do the trick
1. deploy.prototxt file
2. res10_300x300_ssd_iter_140000.caffemodel
The prototxt file, shows the configuration of the model, so I assume the “res10_300x300_ssd_iter_140000.caffemodel” is responsible for the face detection.
So, I wanted to know whether is it possible to replace the above model weights with any other model weights used for detecting other objects (say car, tree, street light, etc) as well as prototxt file & follow the rest of the tutorial as it is and expect it to work just fine?
Could you point me to some other example for detecting other object that you know of following the similar approach?
Correct, the .prototxt file contains the model definition and the .caffemodel contains the actual weights for the model. Together, they are used to detect objects in images — in this case faces. You can replace these files with other models trained on various objects and recognize them as well.
Hey great post! I had one question. Is this algorithm cloud based or can also work on edge?
This algorithm is not cloud-based. It will run locally.
hey adrian! What is the use of opencl in this algorithm?
Sorry, are you asking how to use OpenCL with this example? Or what OpenCL is?
Hi Adrian,
Should this work ok with dlib’s 68 point facial landmark predictor? I tried taking the bounding box from this tutorial and passing it to dlib’s keypoint predictor, but it’s really unstable, ie, when moving my head side to side (pitch-wise) the points are predicted incorrectly and moving everywhere. I even cropped the bounding box to make it square to pass to dlib, and it still didn’t work there well. It seemed like dlib’s HOG face detector worked better. Any idea why? Thanks so much!
OpenCV and dlib order bounding box coordinates differently so I think that might be your issue. Take a look at this blog post where I take the bounding box coordinates from a Haar cascade and construct a dlib rectangle object from it. You should do the same with the deep learning face detection coordinates.
Hi Adrian,
Really great post you’re having.
But I got some error while running the command
net = cv2.dnn.readNetFromCafee(args[“prototxt”], args[“model”])
AttributeError: ‘module’ object has no attribute ‘dnn’
I tried to search online for the solution, also read this post comment.
And I still can’t point out which way to solve this error. :'(
You need at least OpenCV 3.3 (or greater) to access the “dnn” module — previous versions of OpenCV do not have it. You’ll want to re-compile and re-install OpenCV.
I run:
$pkg-config –modversion opencv
And it giving me:
3.4.1
Is there any way how to access the dnn or at least check it?
I am redo all the process installation for OpenCV, I follow exactly like written on: https://pyimagesearch.com/2018/05/28/ubuntu-18-04-how-to-install-opencv/
But then I realize something weird.
All is fine until this step:
$ls /usr/local/lib/python3.6/site-packages/
There’s no “site-packages”…. -__-” I don’t understand why….
If there isn’t a “site-packages” directory there should definitely be a “dist-packages” directory. Can you check there?
Hi Adrian,
I had the same error but I m using the Ubuntu Virtual Machine from your book package – how do I reinstall OpenCV onto this?
If you would like to install a new version of OpenCV on the VM (or any machine) you would follow my OpenCV install tutorials.
I needed to do
$conda remove opencv
$conda install -c conda-forge opencv=4.1.
for this code to work for me. Before I had errors like others here.
Hi Adrian,
Couldn’t we deploy it via Flask + Apache on Raspberry Pi? When i try it i have got 504 Timeout Error. Have you ever tried this model as a web application?
It’s totally possible to use this code as a web application. Have you tried using this blog post as a starting point?
Does this require installing OpenCV with CUDA support?
No, this method will work on your CPU. In fact, I gathered the results and demos for this post using my CPU.
Does this algorithm do non-max suppression as well? I suspect it’s not because when I feed it to the dlib landmark predictor, it goes crazy. Maybe it’s because has multiple boxes around the face in one frame?
Yes, the algorithm is internally doing NMS. I’m not sure what you mean by the dlib landmark predictor going crazy though. Keep in mind that OpenCV orders coordinates differently than dlib. You’ll need to rearrange the coordinates as I do in this post.
Hi Adrian,
Great post! Very helpful. I have two questions:
1) I have replicated this solution using C++, but for some reason the framerate is not as good as the Python version, despite the input blob being created and passed through the model in the exact same way (i.e. resized to 300×300). Relevant code:
=================
// Downsample frame for input to model
cv::Mat blobFrame;
cv::resize(rawFrame, blobFrame, cv::Size(300, 300), 0, 0, cv::INTER_AREA);
// Prepare blob and pass through the network
cv::Mat blob = cv::dnn::blobFromImage(blobFrame, 1.0, cv::Size(300, 300), cv::Scalar(104.0, 177.0, 123.0);
net.setInput(blob);
cv::Mat detections = net.forward();
=================
If I comment out net.forward(), everything runs at a smooth framerate. I’m using OpenCV 3.4.1 on Ubuntu. I don’t expect you to magically know what my problem is from the limited information I have provided, but I’m just hoping you might have encountered this before. Others seem to have encountered it as well: http://www.died.tw/2017/11/opencv-dnn-speed-compare-in-python-c-c.html
2) Can the model be used for commercial applications? I think I found the original source (https://github.com/opencv/opencv_3rdparty/tree/dnn_samples_face_detector_20170830), but it doesn’t have any info on usage.
Hey Rohan, I have not encountered this before, actually. I’m not sure why the C++ version would be running slower than the Python version. My only guess here is that you’re not threading your video stream like I do in this blog post which in turn reduces your FPS throughput rate. Take a look at this blog post for more information on threading.
As for your second question, I did not train the model so I do not want to speak on behalf of anyone. You should post the question on the OpenCV GitHub page.
Thanks Adrian. I implemented a threaded version in C++ and gained a noticeable improvement, though it’s still not quite as smooth as the Python version (but still usable).
Will post a question to the author as suggested.
Hey there! What is the angle detection of the face detector
Dear Adrian, would the following 2 changes make the fps faster for Raspberry pi?
1) Change 300×300 to 150×150 in lines 37 & 38 of detect_faces_video.py?
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (150, 150)), 1.0,
(150, 150), (104.0, 177.0, 123.0))
2) Use gray image instead of RGB?
Thanks,
Razmik Karabed
Hey Razmik — I suggest you try and see! PyImageSearch is an educational blog. I always do my best to help readers but I also suggest readers play with the code. Try new things! Experiment! Update the code, get an error, resolve it, and keep going. Learn by doing — that’s how I learned.
The only hint I’ll give you is that the network was trained on RGB images so you won’t be able to use a single channel grayscale image.
Hi Adrian:
I praise you for being a best teacher.
After playing with the code, I learned:
1) Changing 300×300 to 100×100 increases the fps for Raspberry pi significantly, but
2) using gray images fails as you kindly hinted.
Would any of the classes you teach or your recent book on deep learning cover face detection of networks trained with grayscale instead of RGB?
Hey Razmik — it’s totally possible to perform face recognition using grayscale images, it’s just a matter of training your network on them. I demonstrate how to train networks for smile detection and facial expression/emotion recognition inside Deep Learning for Computer Vision with Python. That would be my ideal course/book suggestion for you.
When you say using gray images fails, do you mean the performance is bad, or you actually get an error?
Cause the error probably would have to do with a discrepancy of expected and given image shapes (300x300x3 vs 300×300). The easy work-around to use grayscale images with networks trained on RGB is to just copy the pixel data into the extra channels, such that you have 3 channels all with the same values. np.stack() will probably work (https://stackoverflow.com/questions/40119743/convert-a-grayscale-image-to-a-3-channel-image)
Hi, thank you for the great post!
I am using your code and I am wondering what is the range of the detection box values. I thought it should be [0,1], but the range I got for detections[0,0,:,:] is [-0.16, 4.98]. And the boxes with values all within [0,1] have much smaller confidence while the maximum confidence is around 0.7.
Is it because I am working with small images (usually 100*50 in size)? If so, how can I modify the code accordingly?
Thank you!
Alright, I change the line
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
to
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) * np.array([w, h, w, h]) / 300
to multiply the box with image size : 300 * 300 ratio.
And it works now.
I am just in LOVE with this blog and the work you put in every tutorial.
thanks loads! 🙂
Thank you, I appreciate that 🙂
Can we use it with Dlib ? I mean face detection using this and recognition using dlib for 128D vector for face.
Yes. In fact, that’s exactly what I did in this post.
Hi All,
I am able to detect the human faces. But unable recognize the face if it is animal.
Is there any API for recognizing the faces of Animal?
Not that I know of. You would likely need to train a network to detect animal faces.
Hi,
maybe there is something wrong with machine but even with your code I get this error
usage: detect_faces.py [-h] -p PROTOTXT -m MODEL [-c CONFIDENCE]
detect_faces.py: error: the following arguments are required: -m/–model
any workaround?
If you’re new to command line arguments, that’s okay, but you need to read up on them first. Read the tutorial I just linked you to and you’ll gain a new understanding and be able to execute the script 🙂
After running this code as it is. I get these exceptions:
ipykernel_launcher.py: error: the following arguments are required: -i/–image, -p/–prototxt, -m/–model
You’re using Jupyter Notebooks to run the code, which is fine, but you’ll need to read this post to understand command line arguments first. Once you understand how to use them you can update the code.
Thank You so much dear <3 Really helped..
It Is posible to ruin this example online opencv2?
Good tutorial!
Just to clarify, do you mean OpenCV 2.4? If so, no, you need OpenCV 3.3+ for this example.
Hi Adrian,
Thank you for the tutorial,
I tried it and it worked well
I face a problem while executing video face detection, once the exit condition is met the video display window closes but the python kernel remains busy for indefinite amount of time till I manually close it from task manager.
I have tried with waitkey value but of no use,
Have you encountered similar issue before?
Thanks
Hey Prashant, I have not encountered that error before. Are you using the example images/videos from this post or your own? Additionally, what OS are you using?
Error happens when I use web-cam stream face detect, other wise the code runs fine. I was using these codes on windows system in jupyter notebook setup installed using anaconda
Hi Adrian thanks for this implementation.. In my raspberry pi 3b+ it is slow… Can i record video or take picture during recognition of a person using usb web cam..
Yes. You can use the
cv2.imwritefunction to write images to disk andcv2.VideoWriterto write videos to dask.Hi Adrian,
Thank you very much for these codes, it’s working great. In my case I want to track both hands and face. How to extract the skin tones from the face ? so that I can track the hands. Thanks in advance.
You can detect skin tones but a more robust method would be to use a hand detector, similar to how we detected the face in the image. You could also detect the entire body and then “fit” a skeleton to the body. I’ll be covering that in a future blog post so stay tuned!
Thanks Adrian, awaiting for the future blog post.
hey Adrian
while executing source code for single input image face detection i face the following problem please help me
…
Can’t open “deploy.prototxt.txt” in function ‘ReadProtoFromTextFile’
See my reply to Martina Rathna
How to detect face using c++ and opencv & dnn model?
Sorry, I only provide Python code here on the PyImageSearch blog. Best of luck with the project!
hi Adrian, thanks for a great post. One question though, how did you arrive at the mean value for scaling (104.0, 177.0, 123.0)?
They are the mean RGB values across all pixels in the training set. We use them to perform mean subtraction.
and one more query, blobFromImage already does resize. Then why should we pass resized image cv2.resize(image, (300,300))
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,(300, 300), (104.0, 177.0, 123.0))
Hi Adrian:
I’m a big fan of your work, thank for share all this knowledge!!.
I have a problem with this example, i don get any detection with a confidence value major to 0.2, i’m sure that dnn is feed with a good quality picture with a big face, if i take the first detection it detect always “airplane” with 0.13 confidence… but the rectangle is wrong… what do you think that could cause this bad detection?
The code in this blog post covers face detection. It doesn’t have an “airplane” class so I’m a bit confused what you are referring to.
Hi Adrian,
Superb work mate. I am really happy with this work of you. I was really irritated with the accuracy of haar cascaded classifier. This was superb. I really enjoyed it. Now i wish to go through your guidance to build a face recognizer program which recognize our face. Once again thank alot Adrian. Superb post…
Thanks Jasen! I’m so happy you found the post helpful 🙂 If you’re interested in performing face recognition make sure you read this post to get started.
Hi Adrian,thanks for your sharing.
I just have one questions: may I use it by Tensorflow rather than Caffe?
The code used here assumes a Caffe model. OpenCV supports some TensorFlow models but the bindings can be a bit buggy at times. Typically I recommend loading your model and then predicting via strict TensorFlow rather than trying to use pure OpenCV.
Wow
Amazing tutorial and example, thanks.
Greetings from Finland
-e-
Thanks Eero, I’m glad you found it helpful! 🙂
…
AttributeError: module ‘cv2.dnn’ has no attribute ‘blobFromImage’
Getting this error unable to resolve this
Make sure you are running OpenCV 3.3 or newer. You need OpenCV 3.3 or better to access the “dnn” module.
Hey adrian I like how to summarize information about the different open-souced NNs available. May I suggest it would we wonderful if you could analize the intuition behind the architecture of the the networks (perhaps as a link or separate post).
A few comments and questions about this tutorial:
The accuracy is not good. Can’t detect skin color variation. Gives close to 50-60 percent accuracy to images that are not close to a face.
My question is :
Should I expect such accuracy for any network which is small?
What if I use GoogleLeNet?
How do these CNN test accuracy then? Isn’t their test set bias itself?
On a related note:
Can I read a tensorflow mode myself I created (saved tf.train.saver module) using with cv2.readNet? What format should my network be of? Is there a particular way I should save the model in order to read it in opencv?
Hey Shubhayu — I actually discuss the theory, intuitions, and implementations behind various architectures inside Deep Learning for Computer Vision with Python. I would suggest starting there.
There could be underlying bias in the dataset itself that was used to train the face detector. Keep in mind that I did not train this face detector. I would suggest gathering your own face detection dataset and/or training your own model on images that your system is likely to encounter in the real-world. That is by far the best way to ensure the highest accuracy rather than relying on off-the-shelf solutions.
Hey! Can you please tell me how can I detect walls and ceilings in a room using OpenCV.
I would suggest taking a look at semantic segmentation algorithms.
Hey Adrian, I have a similar project, could you tell me how to detect different objects but only plastics. How can I train my model to detect only plastic models from the image?
Hey Rahil — do you have an example image of what you’re working with? Are you trying to detect plastic objects or simply recognize texture?
I need to detect plastic objects from an image of a garbage dump. If I take a picture of a garbage dump it should highlight the images which are plastic.
There are two ways to approach such a problem. The first one is via “object detection” but I think you’ll have better luck with semantic segmentation. You’ll likely need to train or fine-tune your own model on plastic images though. I can’t think of a “plastics” dataset off the top of my head so you may need to create one.
Hi Adrian
Thank you very much for the tips 🙂 It is really really useful. I was using haar cascades and it had some false positive. But this is way better than that. I am using this one a emotion detection system. for that I need to get face coordinates as output like from the haar cascades. Any tips or reference on how to achieve it?
OpenCV’s deep learning face detector tends to be more accurate than Haar cascades. I would give that a shot.
What I meant is I previously used Haar, but now I am using the model that you used in this post. (I am not native english speaker, I tthink therefore you misunderstood my english) However, to the emotion detection system, I need to take face cordinates as input (like what we get from haar) I can’t find a way to do it using this model. That is my problem 🙁
Line 47 will give you the bounding box coordinates of the face. You can use coordinates instead of the Haar cascade coordinates.
Thank you very much for everything 🙂 I fully implement my emotion detection system. <3
Did it 🙂 btw this model has a limitation. It does not identify relatively far images. 🙁 Even photos showing full body, does not corp well with this 🙁
i get this error plz help someone
ModuleNotFoundError: No module named ‘cv2’
You need to install OpenCV on your system. Please refer to one of my OpenCV install guides.
confidence = detections[0, 0, i, 2]
can’t understand why do we put ‘2’ there. And why the shape of our detections is (1,1,98,7).
Thank you.
The face detector returns an array with the format:
[batchId, classId, confidence, left, top, right, bottom]
The “2” is the index of the “confidence” value in the array.
Hi Adrian,
Awesome tutorial. I love to read your posts.
I tried for both images as well as webcam, it works well.
I encounter a problem while executing video face detection using a mp4 file, at the last frame of the video, the display window freezes until I manually close it.
Have you encountered similar issue before? What might be the reason?
Thanks
Hm, that is strange. Unfortunately I have not encountered that problem before so I’m not sure what the root cause is.
use the condition
if (cv2.waitkey(0)==ord(‘q’)):
cv2.destroyAllWindows()
Can’t open “deploy.prototxt.txt\” in function ‘cv::dnn::ReadProtoFromTextFile’
please help with it.
thanks
Double-check your path to the input prototxt file as your current path is incorrect, leading to OpenCV throwing an error when trying to load a nonexistent file.
Thanks for this great guide Adrian. I managed to get it up and running and it works well except for a few cases. I have two examples of frontal face shots (like a mug shot) where the face is detected perfectly, but then another face is detected where there is clearly no face. The second incorrect detection is slightly out of the bounds of the image. Both detections have a confidence of around 98%. I could just ignore the detections that fall outside the image, but I’m afraid that there is something happening that I don’t understand that will come back to bite me later.
I have the same problem with this, the detection result with the highest precision is outside the image boundary. Could anyone share with any idea or solution about this situation?
Thanks a lot in advance!
Hi Adrian,
How is NMS handled in this pipeline?
Regards,
Andreas
Thanks bro.. I’m still writting my Master education research and you are my saviour.
I’m happy I could help you along your journey. Best of luck with your MSc!
hi adrian ,
how to prevent a high resolution image from getting cropped?
I’m not sure what you mean by “prevent a high resolution from getting cropped”? Could you elaborate?
Hello Adrian, great post, thank you very much. I have a problem and that’s when I run:
python face_detector.py –image imagen1.jpg –prototxt deploy.prototxt –model res10_300x300_ssd_iter_140000_fp16.caffemodel
Returns the following error
…
Can’t open “deploy.prototxt” in function ‘ReadProtoFromTextFile’
I have OpenCV4 installed on ubuntu 16.06 and the files .prototxt .caffemodel in the folder opencv / samples / dnn / faces_detector
Thanks for your help
Double-check the path to your deploy.prototxt file — the file does not exist on your system. Make sure you use the “Downloads” section of the blog post to download the source code, model files, and example images.
How I can use VGGFace16 caffe for this. I try but didn’t work.
Can you make a tutorial for face recognition with VGGFace?
Why specifically do you want to use VGGFace? Have you tried using my other tutorials on face recognition?
1. OpenCV Face Recognition
2. Face recognition with OpenCV, Python, and deep learning
Hi Adrian,
Thanks for your great tutoral,so how can I detect the face’s x/y/z rotate angle? and how to detect the gender of a face(female,or male)?
Thanks!
hi adrian, i am getting a segmentation fault error while i ran the code in my pi
Which line is specifically throwing that error?
Hey Adrian,
I love your work, but I am having a hard time understanding the output of net.forward().
The documentation says it’s a “blob for first output of specified layer,” (if I am reading things correctly), however, it’s clearly different than the blob I give it. The shape of the output is something like [1, 1, 200, 7] where the third value seems to be the only thing that changes depending on the image — I think that’s the number of “detected faces” based on your tutorial.
My input blob, on the other hand (as you said in https://pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/) is [num_images, num_channels, width, height].
Can you point me to a resource that explains what is returned in more detail? Thanks!
Hey Dilon, are you struggling with the format of the blob itself? Or the returned detection array? I think you may be confusing the two. To get started, refer to this tutorial on how blobFromImage works. From there you’ll understand the concept of a blob and how it relates to the forward pass of the network.
Adrian,
Thanks for your swift reply. I was confused with the returned detection array. I was looking in the OpenCV documentation for how to know which parts of the array correspond to what, but I could not find anything. Any advice on this regard? Thanks!
Wow! I stumbled upon this post and just had to try it out. The sources worked immediately out of the box, with good results on personal images incl. faces partially covered by helmets (when kayaking) or jackets (on a windy mountain walk). Just with a few lines of magic code, pretty cool! Thanks for sharing.
Thanks Hartmut! 😀
In this particular line of code:
for i in range(0, detections.shape[2]):
what does detections.shape[2] represent? why not detections[1] or any other variable?
Sorry if this is silly, but I’m new to computer vision.
The
detections.shape[2]is the number of detected objects.In regards to the face detection lesson. The file “res10_300x300_ssd_iter_140000.caffemodel”
What application reads this, or is this just a raw binary file used by the deep learning stuff.
Some recommendations: Like you do with the Downloads section, can you please put in a link to the comments section at the top instead of having me scroll down the thousands of comments to get to the end so I can post a comment. For some reason, I can’t get access to the scrubber on the right.
Also, I’m visually challenged, and regardless of the font size I choose, the lines representing the text letters are too thin, and of course we have no control over the font “thickness”
Great course by the way.
John
It’s a raw binary file that is generated by Caffe and then read by OpenCV. Thank you for the suggestions as well, I will consider them 🙂
Also,
How do I read these comments in the order of most recent first.
John
There isn’t a method to sort the comments but the comments themselves are actually pre-sorted. Older comments at the top, newer comments at the bottom.
HI Adrian,
Excellent tutorial but getting very poor results with the opencv dnn detector for images i have. Much worse than the haarscascade for example, which has worked ok on the sample images i have. Not entirely sure what i could be doing wrong
It appears that i only start to detect faces in my images if i lower the confidence factor well below 0.5. In most cases almost down to 0.1, and with those vaues, i get lots of false positives.
My sample pictures are of people running towards the camera, not entirely frontal, but i would say at no worse of an angle than your rooster picture.
Cheers
Richard
That’s very odd that Haar cascades would be performing better than the deep learning face detector. It may be a strange anomaly of your data and perhaps the CNN was never trained on that data but it seems unlikely. I’m honestly not sure why that may be.
Hi Adrian,
Yes, it’s very frustrating as the haarscaar cascade is pretty slow, and still isn’t fully accurate in detecting all of the faces.
I’d be happy to share the images with you if you could offer any further observations? You have my email address via this submission if you want to get in touch,
Failing that do you know who formally developed the underlying deep learning model and might be able to offer a definitive view?
Many thanks
Richard
The model is supplied by the official OpenCV repo. I would suggest asking them as they might be able to shed more light on the matter.
Hi Adrian,
Thanks a lot for your detailed post. It is really helpful.
I’m trying to run the command in Jupyter notebook and it keeps throwing the error as argparse is meant for command line.
I’ve tried to use the %system magic command within Jupyter notebook to run the varse() command and it still throws me an error
/bin/sh: 1: Syntax error: “(” unexpected
Can you please let me know if there is a way for me to run this in notebook.
Define
argsas a dictionary and hardcode any values. See this post for an example.Hi Dilip,
As you are running directly from Jupyter notebook you do not need to use the args command(that is for programmers running code from the terminal) instead you can directly throw the file path
Eg: – net = cv2.dnn.readNetFromCaffe(args[“prototxt”], args[“model”])
Replace args[“prototxt”] with the address(location) where the file is placed in your machine.(C:/:Users……..)
Hello Adrian,
I wanted to ask you that can we set limit for face detection that it detect faces at particular angle only? I want that my face detector detects only front faces and not when someone has turned their face even slightly.What can i do?
Thanks in advance.
1. Detect all faces
2. Loop over faces and compute the angle of rotation of the face
3. Discard any faces that are rotated too much
This tutorial will help you compute the face rotation angle.
Hey Adrian;
I heard once that the value of a person is How Much He Gives?
and you are giving a lot
Thanks
Thanks Ibrahim, I appreciate that 🙂
Hi Adrian,
I hope you are having a great day.
I downloaded your code to try it out and while I am getting good results with the two images you provided (for some reason I even got a little bit higher confidence rate on Trisha), it over-detects when I test it with a set of ID like photos.
What it does is that it detects the face (usually at 100% confidence rate but not always) and then it falsely detects an other face on the bottom right corner with varying degrees of confidence, ranging from about 60% to as high as 98%.
Do you have any idea why? If you want, I can take some screenshots or send you some images to try it out yourself.
Thank you so much for all the ressources and hard work you have put into this website, it’s a knowledge goldmine. I wish you all the best. God bless you.
Best regards.
Are you using your own images when testing the face detector? It’s hard to say without seeing your exact images but typically it’s because you’re trying to detect faces at viewing angles, etc. that the model was not trained to detect.
Hi Adrian, thank you for having taken the time to answer.
These are photos for ID cards. Each photo contains only one person looking straight at the camera, most of them have been taken by professional photographers. But the script detects two faces, their face and also the region of their left shoulder (bottom right of the image).
The thing is that this false positive has quite a high confidence rate.
Regarding me, I go around this issue by only using the first detection since the actual face was always the first one.
If you never encountered this issue and would like to explore it to enlighten us, I can email you some photos. One more thing, these are scanned photos.
OpenCV’s face detector was not trained on scanned images of ID cards. The scanning may add some sort of artifact that causes the face detector to “think” there is a face there. Since ID cards for most regions have the face in the same location you could potentially discard any faces that are not where they “should” be on the ID card.
Hello M ,
Observed same issue .. i think its a bug , you can report it to opencv issues .
Quick solution is .. find overlapped face detection and discard one with lower (top left corner). I did same and resolved this issue .
I meet the same situation but how can you find the overlapped area with which command
can you teach me?
Hi Adrian,
The python script fails to work on some images. I downloaded a couple of images from google, it worked on some pics, but did not recognise a few images. I found it strange, because a few pics that had trees, it detected only one face. It did not detect any face for some high resolution pics
High resolution images may look appeasing to the high but the additional detail only hurts performance of CV systems. Try resizing the image to have a maximum of 512-1024px along the largest dimension.
Hey Adrian , great tut as always 🙂
Quick finding is that i tried opencv native facemark for landmark detection (FacemarkLBF) with this DNN based opencv face detector. Predicted landmark is not that accurate for profile face (with vary in Yaw angle).
where as its working better with Haar cascade based face detection. Any particular reason ?? training own model with DNN based face detector would work better ?? thanks in advance
Face detection is a required first step to finding facial landmarks. DNN-based face detectors tend to be significantly more accurate than Haar cascades.
Hello adrian ..
Indeed Face detection is a required first step to finding facial landmarks, My question is
1. I detect face with Opencv DNN based face detection
2. Given this region to Landmark detection , result is not accurate , points are not fitting face …
I think may be issue is face detector bounding box… (Due to anchors as per SSD, its rectangle most of time )
Any other insight or solution is appreciated … thanks adrian for Prompt reply
Have you tried with dlib’s facial landmark detector? I don’t think it’s the face detector itself, but perhaps an issue with OpenCV’s facial landmarks being less accurate.
Hi Andran! Thank you so much for this post!
I have one question about setting camera resolution.
Is there any way to get maxium resolution of my webcam?
I’ve been googling for that but couldn’t find any solution..
You can remove the call to
imutils.resize. which resizes your frame. That will ensure you have the raw frame size itself from your webcam.Hi Adrian,
congratulations, this course is really well done!
Do you have some advice if it is vehicles instead of faces? I would like to count and classify (let’s say “cars”, “Bicycles”, “Pedestrians”) vehicles, real time is not required. What approach would you suggest?
A great first start would be to modify my OpenCV People Counter. In that tutorial I use a model pre-trained on the COCO dataset which includes classes for people, cars, bikes, etc.
Holy Moly! First lesson in the free series, first project, success first time on windows AND raspberry Pi. Dude, you rock with code and teaching! This is the FIRST lesson I have done where everything worked in both environments, and I have been to LOTS of blogs and instructions. I am not quite ready to jump into the deep end of the pool with your paid lessons, but you should consider a Patreon account. For those of use with a little less disposable income, it is a nice way to give back to great resources like you.
Thank you so much for the kind words, Bob — I really appreciate that! I hope you continue to get value out of the PyImageSearch blog. I’ll also consider a Patreon account as well.
Thanks Adrian!
but how can i fix it I’m beginner
error: the following arguments are required: -p/–prototxt, -m/–model
It’s okay if you are new to Python and command line arguments but make sure you read up on them before continuing. From there you’ll have the knowledge to solve your error.
First of all , cheers to Adrian for making this amazing course accessible to all of us .
While implementing the face_detects file , the output to an image of mine is an AttributeError saying NoneType has no shape . Can anyone help with this ?
and also it is giving no prediction in some images ..
Double-check your path to your input image dataset. The path to your input image is likely incorrect, causing
cv2.imreadto return “None”.Hi, Anubhav
Can we reshape some facial parts like beauty plus app using this framework.
Thanks
Oh. My. Word. The performance of the video version blows me away. Out of the box. Wow. Thanks for coding these demos. I’m not sure I have anything useful to do with this exactly as is, but I’m going to study it and ponder. With adaptation, I can definitely use it. Got to learn training, categorization, internals… Great stuff.
Thanks Bill!
Hi
The code works first time using a standard windows cmd console on my Windows 7 laptop,
but …weirdly … does not work reliably when run in Visual studio 2017 on the same machine.
Now this seems to suggest that something in Visual Studio 2017 on a windows 7 machine is wrong. As part of testing the code, I reduced the size of the face in the rooster.jpg file ( by selecting that area and resizing using the “paint” app.)
The code still successfully detects the face when run in the windows cmd console,
but when run in Visual Studio 2017, the response is
(h,w) = image.shape[2] attribute error has no attribute ‘shape’
Same code, same argument files, same folder …problem with Visual Studio !
I did some debugging;-
visual studio works with the supplied rooster.jpg file
visual Studio does not work with the modified rooster_2.jpg file (reduced face size), but it worked with that rooster_2 file when run in in a cmd console (not VS)
I guess that’s an FYI for other users of Visual Studio, not a defect in the code ?
So …. Folks …
Watch out if using Visual Studio … try the code out first in a standard windows console !!
Thanks for sharing!
Is it possible to filter out non-frontal and obstructed faces?
No, this method will simply return the bounding box of a detected face. It does not distinguish between obstructed faces.
Hey Adrian, thank you for your work first ! I was wondering how to count how many people you have at the same time if that’s possible, cause i’d like tu use it for my kiosk to count how many people are passing by !
Thanks
See my OpenCV People Counter tutorial.
Thank you i just found this after i posted my question ! Your tutorials are really great thank you for that ! I’m trying ti implement a gender and age recognition to my code to you have advices for an easy way to do it ?
I cover both of those topics inside my book (including code) inside my book, Deep Learning for Computer Vision with Python.
Hi Adrian,
Could you tell me how cane we solve RSNA xray bone age detection problem ?
Sorry, I do not have any tutorials on that subject.
Dear Adrian,
I am a newbie in video analytics. Would you be able to explain more on the following line. May I know how do you know what is being returned from net.forward. I can’t seem to find the output definition from the prototxt.
detections = net.forward()
confidence = detections[0, 0, i, 2]
Thanks
Best,
Calista
Sorry, are you trying to understand what is contained in the “detections” array? Are you using the same face detector used in this tutorial? Or a different one?
Hi Adrian,
I have gone through this course and I found it fruitful. Have practiced both face and video detections. Great effort, thumbs up!
Now, I want to save these faces with their names for future use. How can I do that?
You want to save the images to disk? If so, use the “cv2.imwrite” function:
cv2.imwrite("path/to/your/image.jpg", image)Thanks Muhammad, I’m glad you enjoyed the crash course!
Hi Adrian, an so grateful for all the things you have been doing. But am still a beginner in this stuff, so kind of confused. Downloaded the source code for this blog post but don’t know where exactly to include the path of the various files needed.
It’s okay if you are new, I would just recommend reading this post on command line arguments to help you understand how the file paths are set.
How can i pass multiple images to the net here. I tired blobfromimages and fed into the net. but the prediction shape looks erroneous
Prediction shape for single image: (1, 1, 106, 7)
Prediction shape for batch of two image: (1, 1, 216, 7)
I made a batch of two images with the same sample image you provided in your example.
Please comment
I figured out that it in last axis, there is a variable indicating the image in batch.
Can you please describe all the dimensions of both “detections” variable in the program and also all the 7 elements of the last axis.
Thank you
The 7 elements are:
1. Batch ID
2. Class ID
3. Confidence
4. Left
5. Top
6. Right
7. Bottom
Hi! I was very helpful with your tutorial, but I have a logitech c920 camera, and when I run the code and it shows me the live video, it runs at 10 fps or less, which part of the code should I edit to record at 30 fps?
I think you have a misunderstanding of how computer vision algorithms work. Computer vision algorithms are not magic. They consume CPU cycles and can be computationally expensive. It’s not your webcam that’s making the algorithm run slow, it’s your CPU. Your CPU simply cannot process that many frames that quickly.
Hi,
detection array has shape (1, 1, 108, 7). You have already explained definition of last dimension. What first three dimensions signify? Can you please point me to definition of this structure?
The 7 values returned are:
1. Batch ID
2. Class ID
3. Confidence
4-7. Left, top, right, bottom
Which dataset was used to train the network?
Hi Adrian,
just thinking it would be unfair to leave this page without congratulate you for your amazing tutorials.
Best regards
Thanks António 🙂
Hi Adrian, Thanks for the great tutorial. I would like to find the head angle and the body angle w.r.t. the camera, do you think using the pose coordinates would be sufficient to find the angle? or using solvePnP function is the right approach? Could you please share the article specific to this? Thank you very much
Thanks for the suggestion, Prashant. I don’t have any tutorials for head pose estimation but I will consider it for the future.
Hi adrian,
I don’t understand which file should I download from github link you shared. There are 9 files there and I am confused that which file is prototxt file and which file coffe train model is.
Please tell which files I have to download from there
Thank you.
You don’t need to download anything from GitHub. Just use the “Downloads” section of this blog post to download the source code, face detector model, and example images.
Hi Adrian
Thanks for the great tutorial. I have a question for you ?
How can i detect real human face not face painted.
Thank a lots
What you’re referring to is called “face liveliness”. I don’t have a tutorial on it currently but I will try to cover one soon!
Hello Dr. Adrian,
it’s a very useful tutorial. Thanks for sharing…
but it is taking too much time to detect faces for 1000 images on CPU (aprox. 1.5 hrs).
Can u please guide me, how can i run this same code on NVIDIA GPU given in.
i want to test this code on GPU for face detection. Do I need to compile OpenCV on NVIDIA GPU CUDA? or any other configuration need on GPU?
Do we have any GPU related blog on this tutorial?
Unfortunately OpenCV does not yet support NVIDIA GPUs for their “dnn” module. They should hopefully be supporting it soon but currently they do not.
Absolutely marvelous! Thank you very much, Adrian!
Thanks Mario!
How ‘blobFromImages’ function will work here?
when we pass images in list to this function, how to get detections for individual images and loop over them to detect face in each image?
would it be faster than ‘blobFromImage’ function?
any thoughts or sample code….plz share
Take a look at this tutorial where I explain the blobFromImage function.
Hi Adrian, Thank you for the post, I have successfully run the demo in my system. It is open it in a frame, but I need to open it in the browser like a web application. Can you please help me how to this?
I’ll be covering that exact use case in my upcoming Computer Vision + Raspberry Pi book, stay tuned!
Hi there
I am searching for help in my project of multilingual text recognition
Objective is to recoginize different language written on an image and my project has to recognize which language it is and then convert it into user friendly language
Say a image has text written in english , spanish and french so my project will first categorize each text language and then convert that text say spanish written text in user friendly english.
Please help me !
Its urgent
I would suggest you apply text detection + OpenCV OCR. Once you have the OCR’d text as a string it should be straightforward to determine language using a pre-trained model (there are many, many libraries and packages that can do that). The first step is to OCR the text which is what I recommend you start with.
Hi Adrian,
Your are a good teacher and can u guide me please about the face recognition based on attendance system
I will be covering that exact topic in my upcoming Computer Vision + Raspberry Pi book, stay tuned!
Hi Adrian, I really enjoyed reading this post and many others in the past. Thanks!
Thanks Anicetus, I’m glad you enjoyed it!
hey, thank you for this great post. I need one help I have to train my own face and if the confidence value is greater than 85 then I need to generate that name in an excel sheet how can I do that please help me thank you.
Take a look at this tutorial where I show you how to obtain the predicted probability of a recognized face.
Sir do we need to know Python before choosing this course?? If it’s the case then I will start learning Python along with the course.
Thanks
My blog posts and courses requires basic programming experience. If you know Python already, great! If not you can learn Python along the way 🙂
for use inside pycharm go to
1) run
2 )edit configurations
(write this line):
–image “rooster.jpg” –prototxt “deploy.prototxt.txt” –model “res10_300x300_ssd_iter_140000.caffemodel”
then can debug !!
Hello,
Thank you for this tutorial it has been great.
I wanted to put at the bottom of the video frame a message saying: ‘Number of people in the room: ‘result’. I know how to put the text but I’m not sure how to quantify the number of rectangles that appear…. any ideas?
I would suggest you use an integer to count the number of detected faces. Loop over the detected faces and if the current detected face passes the minimum confidence threshold value, increment the counter.
Dear Adrian,
Thank you for your reply.
What I did was:
counter=0
…
if confidence > args [‘confidence’]:
counter+=1
The issue is that wherever I put these lines on the code the counter will increment non stop rapidly. Should I create an additional loop for that?
Kind regards
You need to reset the counter at the top of the loop. It sounds like your counter is not being reset.
Thank you for your reply. Much appreciated.
I will give this a try.
Hello! I am a beginner in machine learning and deep learning. I enrolled for your crash course in 17 days. I read the article for day 1. i really understood much of it.
but I am having some doubts on the lines 8,10 and 12. I am not understanding how to enter the paths of image, .prototxt file and .model file. can u please help me with that.
thank you,
Nilutpol
If you’re having trouble supplying the file paths you’ll want to read this tutorial on command line arguments.
Hi Adrian,
Awesome tutorials. I apologize if the question has already been asked and answered. I have gone through this tutorial and the object detection tutorial from Sept. 2017 and was wondering how just the faces are isolated in this tutorial, but all objects are detected in the other tutorial. I compared the code for both tutorials and didn’t see many differences between the two and nothing really stood out.
It’s not the code, it’s the model itself. The object detection model I think you’re referring to was trained on the COCO dataset which includes many common object classes. This model on the other hand was trained on just faces.
Do you know how I can add 3d to the scene? or even attach to the face.
Hi, Adrian.
Thanks for your tutorils.
I would like to detect and segment my own objects.
In other words, I want to implement instance segmentations for my own objects.
How can I do for that?
Regards.
I actually cover how to train your own custom instance segmentation networks inside my book, Deep Learning for Computer Vision with Python. I would suggest starting there. You will learn how to annotate your data and then train the network. I include code as well.
Hello, Adrian.
Thanks for your reply.
I want to implement your projects in iOS or Android or Visual Studio C++.
What should I do?
Best regards.
OpenCV provides iOS, Android, etc. bindings but you’ll want to refer to OpenCV’s documentation as I do not cover them here on the PyImageSearch blog.
Hi, Adrian.
Thanks for your tutorils.
when is your next tutorial coming?
Best,
I post new tutorials every Monday at 10AM EST. You should sign up for the PyImageSearch newsletter to be receive email updates when tutorials are published.
Hi Adrian, Great tutorial
I just want to know that after running detect_faces_video.py for the first time, I got the exact result
And while exiting I get the alert saying that “Python.exe Stopped Working” and Windows is Collecting the Information
After that, on the second try, I can get the video feed but there is no rectangle on the face
opencv = 3.4
python = 3.6
It sounds like you’re using Windows — can you try on an OS other than Windows? Keep in mind that the “face_recognition” library does not officially support Windows.
Hi sir, i have been referring your video’s and blogs for learning object detection and more , i have some doubts like,how confidence is calculated and importance of that and is there any pre-trained model for object detection in opencv like caffe that we used for face detection ?
If you’re interested in understanding how deep learning object detection works start by reading this guide. It will help you get started.
Hy Adrian.
I am trying to follow your code. Face detection model is working perfectly, on the images where face is at distance from the camera. But it quite fails when there is a pic in which face is quite near to camera. I have tested it on on the image (sorry there is no option to post pic),in which face detection quite fails.
Moreover there is a library named as “CVLIB” (which is also DL based), it is also failing in giving required results. (here you can the my query on github ‘ issues portal of CVLIB
https://github.com/arunponnusamy/cvlib/issues/15 ) (e.g Donald Trump image on that link)
Can you slightly guide me that why DL based face detector fail on the images, which are near to camera?
Hi Adrian,
Great tutorial. I wanted to know if a similar architecture exists for a time series data to identify anomalies in the data. A multiple object detection sort of model. The data is 1-D and the model needs to be implemented to get anomalies in the data.
Hi, Adrian:
I download the caffe source code and compile it as C++ static library,I test the face detection caffe model with the static library, but the lib report “norm_param” field is unknown,so is it means that “norm_param” is a custom field implement by OpenCV,not a standard caffe field?
where can I find the deploy.prototxt and res10_300x300_ssd_iter_140000.caffemodel files ?
You can use the “Downloads” section of the tutorial to download the code and face detector model.
Hi Adrian,
great work and thanks.
Now I use 50%CPU of this detection program.
I am considering use GPU to deal with it.Do you have any idea?
Much thanks.
I found answer in this page of your reply,thanks.
Hi Adrian
One thing I don’t understand is why this ResNet10 only detects faces and not any other objects? I looked through the code and it doesn’t filter on any labels as it is sometimes done with other DNNs. Is this trained model specific to face detections and nothing else?
Thanks!
The ResNet implementation used in this post is trained only for face detection. It is not trained to detect other objects.
Hi Adrian. Great post. I have some face dataset and I want to fine-tune this caffe model, can you guide me on how to do this? Thanks.
I don’t have any tutorials on fine-tuning the face recognition network but I’ll definitely consider it for the future.
Hi Adrian,
How can we get the OpenCV file for this source code?
Thanks in advance
You can use the “Downloads” section of the post to download the source code + trained face detector model.
Thanks for this great tutorial!
The face detector work well on streaming (I think someways better than mtcnn not only speed but accuracy if your face not too far from camera) but when I tried with my images downloaded from Google that has about 7 faces (Game of Thrones movies), the results was very bad (only 1 or 2 out of them were detected). What should I do?
Adrian thanks for the tutorial. I have a question. Why do you need to resize the image to (300,300). When you generate a blob, doesn’t that automatically resizes the image. So instead of this:
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0, (300, 300), (104.0, 177.0,123.0))
When I do this, it still works:
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300), (104.0, 177.0, 123.0))
Because (300,300) parameters in the blob definition is for this purpose. I see that you also did the same thing in here :
https://pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/
Am I wrong on this? Thanks.
Hi Adrian, first thanks for the awesome post. I have a question on library we used for video capturing. OpenCV already has VideoCapture function so why we are using imutils library?
The short answer: We use threading to make it more efficient. For the longer answer, see this tutorial.
Hello Adrian, I have question about fps on raspberry pi. How much fps did you get during inference on pi? Please share some light on this, i checked other comments also didn’t found any reference
This tutorial will help you address that question.
Hello Adrian. Above I have asked a question two weeks ago. However, you have not gave an answer still.
Abdullah — I do my best to respond to the majority of the comments I receive on the blog but sometimes I cannot get to them all. Keep in mind that I’m providing this tutorial (and now this comment) to you for free. If you need my help I would strongly encourage you to take a look at the PyImageSearch Gurus course. The course includes private community forums which I participate in daily. If you don’t want to join the course, that’s fine, but kindly be more respectful in the future as I’m already providing you with these guides for free.
Amazing post Adrian!! Thanks a lot! =D By the way, have you made any tutorials on how to distinguish between different faces? (so as to track different people on video)
As a side note to everyone, increasing that “magic” 300 makes things much more precise (at the expense of computing power, of course). I had a photo with a group of 22 people (some closer to the camera, some further from it, some leaning, …). Using 300, the net could identify only 4 people. However, simply changing
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
to
blob = cv2.dnn.blobFromImage(cv2.resize(image, (600, 600)), 1.0,
(600, 600), (104.0, 177.0, 123.0))
led to the identification of all 22 faces.
By “distinguishing between faces” are you looking to perform face recognition and identify each person? Or simply count the number of unique faces?
Hi Adrian, your blogs are awesome!!
Thank you 🙂
Hi Adrian,
I thanks for your blog which I learned a lot about python and RBP. I implement a python binding for face detector based on CNN which can reach 38 FPS on raspberry pi. Check it out on this page: https://github.com/CharlieXie/libfacedetection-python-bindings
regards,
Thanks for sharing, Charlie!
How Can I Detect Multiple Faces Because This Is Right Now Only Detecting Single Image in an Image, So How Can I Modify This to Detect Multiple Faces in an Image? I am Trying to use this as a Face Count
This code will detect multiple faces in an image or video stream.
Hi, Thanks for such a great article. I love the content and practical approach of teaching things.
I have a question, where are the weights available in the opencv repository? I’m not able to find them easily and want to know where they reside.
Thank you
Hey Pawan — just use the “Downloads” section of the tutorial to download the pre-trained face detection weights.
Hey Adrian,
I have to work on NVIDIA Jetson TX2. A simple Face Detection using Haar cascade isn’t an intensive computation as compared to running Deep learning networks, for which the board is actually intended. So, will this algorithm work on the board? If not, can you help?
I provide dedicated help for deep learning-based applications for the Jetson series inside Raspberry Pi for Computer Vision. Pick up a copy and we can definitely talk more about the issue.
I understand that only the front face can be detected through haar cascade xml. Can this method detect slanted faces (diagonal faces)?
The deep learning-based method is more accurate than Haar cascades and can work better with head tilt. It will not work for all titled heads, however.
Hi Adrian,
What exactly is being returned in the detections object?
I can see it’s a (1, 1, 184, 7) array but I’m trying to understand the elements within this array.
Hey Clarke — refer to the comments of the post, I’ve addressed that question a few times. Thanks!
hey Adrian!I want to know why detections[0, 0, i, 2] can respect the confidence and how could we draw a rectangle ?it troubles me so long and i really want to know what does the function net.forward() return.
Hi Adrian,
Thank you very much for your blogs, very easy to understand.
Hi adrian, can u please guide me what shall be used for detection of occluded faces
I am a new in openCV , I want detect face or eye’s user and user’s shoulder.
at the first step I could detect face and eyes.
But unfortunately I can’t detect user’s shoulder.
How can I detect shoulders?
Thankful
Is multiple face detection on webcam possible by OpenCV? If yes then please forward some sources.
This tutorial covers multiple face detection.
Hi Adrian,
I just tested this face detection – works perfect! Much better then haar.
Thank you for sharing!
You are welcome!
Hi Adrian,I am asking this question just from Intuition after going through the code.I understood that blob size is set manually from the code(Correct me if i am wrong).What happens to the accuracy of detection if faces in my image are too small/large compared to blob size that was given?
Thank you so much for a wonderful code and nice explaination
You are welcome, Archie!
Hi Adrian!
First to all, thank you so much for you work and tutorials!
I’m new in the OpenCv way and you are help a lot already!
Here is my question.
I’m trying to merge the counter people and face recognition code, it works, but the rectangle in face recognition works intermittently.
Doy you have some clue abot this?
May be it’s just my compueter, I guest.
Thank you in advance
You mean that the face is not always detected? Keep in mind that face detectors will perform best during frontal views. If there is too much of a profile view the face may not be detected.
Hi, great project!
I just wanted to ask if it is possible to capture the coordinates of the face on the screen?
The coordinates would be in x, y, z.
That’s a separate problem. I would suggest focusing your search on “face/head pose estimation”.
Hi Adrian,
May I know is there a way to detect only the biggest face within the frame using this method? How can I do it?
Loop over the detected faces and examine the bounding box coordinates. Use the bounding box coordinates to compute the area of the face. Then keep track of the largest face using bookkeeping variables.
Awesome work, Adrian!
You are my hero of the day. In less when 2 hours your FREE course helped me to go from 0 (like dreaming “some day I would like to try to use some python library to dig into computer vision”) to actually detecting my face!!!
Most time was used up by installing python, openCV and imutils – after that downloading and running actual code was quite straight-forward.
Hearthly thanks for your work!
That’s awesome Peter, thanks so much for the comment!
Thank you Adrian for this great tutorial. I learnt a lot from you.
Could you please suggest how to detect back and top of head in real time?
Thanks a lot Adrian, your blog is so easy and understandable. Can you please guide me about the custom object detector? I am working on my Final Year Project which is all about the real time gun detection.
Hey Abid, I cover how to train your own custom object detector, including how to train a gun detector, inside my book, Deep Learning for Computer Vision with Python. I suggest you start there.
This code is not providing accuracy.
For ex-There is a photo of multiple persons so it detects some of the faces but not all.
If a photo is of higher pixel then also.
Please provide me a way so to improve the accuracy.
Hi Adrian,
Could you please do a tutorial on combining of object detection and face detection code which need to run parallel in one frame.when a person encounter we need to do face detection.
Thanks in advance.
Hey Adrian, while making the box, we should have start and end as a fraction between 0 and 1 to make the box.
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype(“int”)
However, I found out that some of the detections values were negative and greater than 1. I am not sure about the trained model file, but it should not be going out of the [0, 1] domain. Do you know why it’s happening?
in cv2.dnn.blobfromimage what happens behind when I change the the size parameter. in output I can see more faces detected and accuracy imporved for some images but why ? what is happening in backend?
Why do we use the equation in line 52 (y = startY – 10 if startY – 10 > 10 else startY + 10)? As startY goes from 0 to 20, y counts up to 30, but then abruptly drops to 11 at startY=21. Is there a reason this is desired?
Namely just to ensure the text does not overflow off the top of the frame/screen.
Hi Adrian,
Did you have to configure the Caffe prototext file yourself or is it one of the files available on Caffe’s github page? Your blogs have been very helpful in teaching me about computer vision and its applications.
Thank you in advance.
Hi Sakshi — the face detector that localizes a face is an OpenCV development team provided pre-trained Caffe model. Be sure to refer to the information and links in the “Where do these “better” face detectors live in OpenCV and where did they come from?” and “Where can I can I get the more accurate OpenCV face detectors?” sections. We’re so glad you’re gaining a valuable education by reading PyImageSearch content!
Hi Adrian,
Firstly, thanks for this great content, when I tried running detect.py over different images which were quite bulky in size( around 10 Mb an image) it is showing only a small part of the image, how to deal with this, it’ll be really helpful for me.
Thanks.
You typically wouldn’t process such a large image. Is there a particular reason you are trying to process the original image without resizing?
Hey Adrian,
Have you ever tried to load existing openCV dnn model (graph and weights) and retrain it on your own faces data? I am trying to do that with tensorflow version.
You are doing the lord’s work…
Keep up the amazing work
Thank you for the kind words!
Hi. Adrian.
At first , Thank you for your lesson.
I download and execute your python file.
It acts perfectly, by the way, there is only one problem.
I turn off the png file but the program doesn’t end and I can’t use another command.
I click ctrl+c or ctrl+z several times, but it doesn’t act.
So if I use this program once more, I turn off the vscode or cmd prompt and execute again and it is very tedious.
Could you tell me why it happens.
Sorry to bother you such a simple question.
Sincerely.
You need to click on the window opened by OpenCV and press a key on your keyboard to advance execution of the script.
great!
Thanks, I’m glad you liked it!
Hi Adrian!
Grateful for the detailed tutorial! it helped a lott!
I wanted to know how to do face detection of a video file (mp4), instead of the webcam. I tried VideoStream(“path to the mp4 file”).start().
It did work (my mp4 file was the trailer of “train to busan”). But for some reason the video played super fast, and a lot of frames were skipped. I tried to add waitkey(100), which slowed the video down, but the frames still skipped. Any idea why this is happening?
I tried following one of your tutorials on facial recognition using opencv, the one with the jurassic park clips. But there are a lot of differences in the code, which im unable to undersand
Any help will be really appreciated!!
Keep in mind that the goal of OpenCV is to process images/frames as fast as possible. It doesn’t “care” what the original FPS of the video was, it’s just trying to process those frames as quickly as possible. You can either use “cv2.waitKey” or “time.sleep” calls if you want to slow down the processing.
You don’t mention, either here or in the separate blog post, that the FileVideoStream.read method may not always return an object suitable for resizing. When I did the small modification to read from a file, I took the easy way out and put the imutils.resize() call in a try/except block, and broke out of the loop on the eof “error”.
Hi,
your blogs are great help, Everything that I know till now about Computer vision and detections is from your blogs. Thank you for that 🙂
I was trying to detect eyes along with faces. could you please suggest any pre-trained eye tensorflow model . I guess Haarcascade xml files don’t work with Tensorflow.
Thanks in advance
Thanks for the kind words, Naomi. I’m glad to hear you are enjoying the blog.
As for an eye detector, just use facial landmarks.
Thanks a ton learned a lot , though I am using google collab so the entire code was not running over it but after some research found how to deal with it and after tweaking your code was successfully able to run and get the output.
I am sure many must be using Google collab request you to include some tutorial on collab also mainly marking out some important differences.
#lovingit #thanksaton #keepinspiring.
Thanks,
Ishwar Sukheja
Thanks for the suggestion, Ishwar. I cannot guarantee I’ll cover Google Colab in the future but I will consider it.
excellent tutorial, I am trying to pass the code to a java writing application but I am not getting it, will you have this same example in java?
Sorry, I only provide Python code here on the PyImageSearch blog. Good luck!
Hi Adrian,
Thanks for the great tutorial.
This sample module supports deep learning frameworks Caffe.
Is there a sample that works with TensorFlow/Keras?
You mean you’re trying to perform face detection with Keras/TensorFlow? Is there any particular reason why?
I am not very familiar with cameras, so this might be an elemental question: why do cameras warm up? Is this some sort of delay or something else?
Some cameras perform automatic light sensing and contrast/brightness adjustment. This process takes place automatically as the camera is activated. If you’ve ever turned on your laptop camera on a bright sunny day you’ll see that the feed looks washed out until the camera balances itself.