Last updated on December 30, 2022 with content updates.
In today’s blog post you are going to learn how to perform face recognition in both images and video streams using:
- OpenCV
- Python
- Deep learning
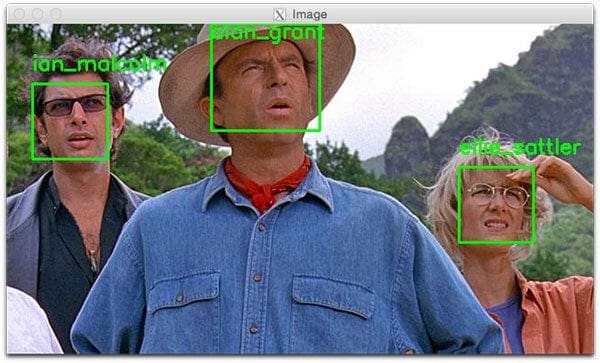
As we’ll see, the deep learning-based facial embeddings we’ll be using here today are both (1) highly accurate and (2) capable of being executed in real-time.
To learn more about face recognition with OpenCV, Python, and deep learning, just keep reading!
Having a face dataset is crucial for building robust face recognition systems. It allows the model to learn diverse features of human faces such as facial structure, skin tone, and expressions, which leads to improved performance in recognizing different individuals.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.
- Update July 2021: Added alternative face recognition methods section, including both deep learning-based and non-deep learning-based approaches.
Face recognition with OpenCV, Python, and deep learning
Inside this tutorial, you will learn how to perform facial recognition using OpenCV, Python, and deep learning.
We’ll start with a brief discussion of how deep learning-based facial recognition works, including the concept of “deep metric learning.”
From there, I will help you install the libraries you need to actually perform face recognition.
Finally, we’ll implement face recognition for both still images and video streams.
As we’ll discover, our face recognition implementation will be capable of running in real-time.
Understanding deep learning face recognition embeddings
So, how does deep learning + face recognition work?
The secret is a technique called deep metric learning.
If you have any prior experience with deep learning you know that we typically train a network to:
- Accept a single input image
- And output a classification/label for that image
However, deep metric learning is different.
Instead of trying to output a single label (or even the coordinates/bounding box of objects in an image), we are instead outputting a real-valued feature vector.
For the dlib facial recognition network, the output feature vector is 128-d (i.e., a list of 128 real-valued numbers) that is used to quantify the face. Training the network is done using triplets:
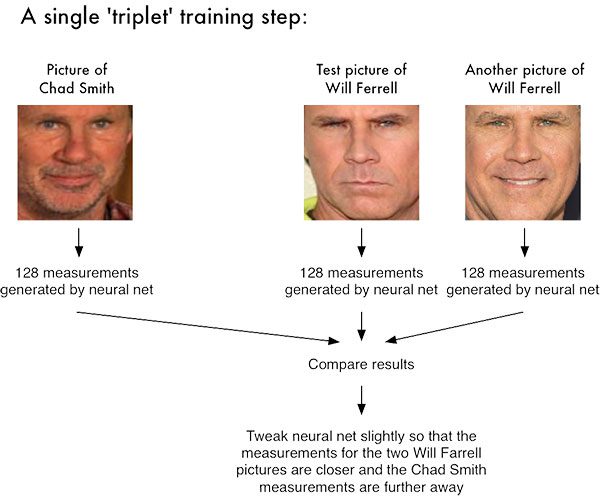
Here we provide three images to the network:
- Two of these images are example faces of the same person.
- The third image is a random face from our dataset and is not the same person as the other two images.
As an example, let’s again consider Figure 1 where we provided three images: one of Chad Smith and two of Will Ferrell.
Our network quantifies the faces, constructing the 128-d embedding (quantification) for each.
From there, the general idea is that we’ll tweak the weights of our neural network so that the 128-d measurements of the two Will Ferrells will be closer to each other and farther from the measurements for Chad Smith.
Our network architecture for face recognition is based on ResNet-34 from the Deep Residual Learning for Image Recognition paper by He et al., but with fewer layers and the number of filters reduced by half.
The network itself was trained by Davis King on a dataset of ≈3 million images. On the Labeled Faces in the Wild (LFW) dataset the network compares to other state-of-the-art methods, reaching 99.38% accuracy.
Both Davis King (the creator of dlib) and Adam Geitgey (the author of the face_recognition module we’ll be using shortly) have written detailed articles on how deep learning-based facial recognition works:
- High Quality Face Recognition with Deep Metric Learning (Davis)
- Modern Face Recognition with Deep Learning (Adam)
I would highly encourage you to read the above articles for more details on how deep learning facial embeddings work.
Install your face recognition libraries
In order to perform face recognition with Python and OpenCV we need to install two additional libraries:
The dlib library, maintained by Davis King, contains our implementation of “deep metric learning” which is used to construct our face embeddings used for the actual recognition process.
The face_recognition library, created by Adam Geitgey, wraps around dlib’s facial recognition functionality, making it easier to work with.
I assume that you have OpenCV installed on your system. If not, no worries — just visit my OpenCV install tutorials page and follow the guide appropriate for your system.
From there, let’s install dlib and the face_recognition packages.
Note: For the following installs, ensure you are in a Python virtual environment if you’re using one. I highly recommend virtual environments for isolating your projects — it is a Python best practice. If you’ve followed my OpenCV install guides (and installed virtualenv + virtualenvwrapper ) then you can use the workon command prior to installing dlib and face_recognition.
Installing dlib without GPU support
If you do not have a GPU you can install dlib using pip by following this guide:
$ workon # optional $ pip install dlib
Or you can compile from source:
$ workon <your env name here> # optional $ git clone https://github.com/davisking/dlib.git $ cd dlib $ mkdir build $ cd build $ cmake .. -DUSE_AVX_INSTRUCTIONS=1 $ cmake --build . $ cd .. $ python setup.py install --yes USE_AVX_INSTRUCTIONS
Installing dlib with GPU support (optional)
If you do have a CUDA compatible GPU you can install dlib with GPU support, making facial recognition faster and more efficient.
For this, I recommend installing dlib from source as you’ll have more control over the build:
$ workon <your env name here> # optional $ git clone https://github.com/davisking/dlib.git $ cd dlib $ mkdir build $ cd build $ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1 $ cmake --build . $ cd .. $ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA
Install the face_recognition package
The face_recognition module is installable via a simple pip command:
$ workon <your env name here> # optional $ pip install face_recognition
Install imutils
You’ll also need my package of convenience functions, imutils. You may install it in your Python virtual environment via pip:
$ workon <your env name here> # optional $ pip install imutils
Our face recognition dataset

Since Jurassic Park (1993) is my favorite movie of all time, and in honor of Jurassic World: Fallen Kingdom (2018) being released this Friday in the U.S., we are going to apply face recognition to a sample of the characters in the films:
- Alan Grant, paleontologist (22 images)
- Claire Dearing, park operations manager (53 images)
- Ellie Sattler, paleobotanist (31 images)
- Ian Malcolm, mathematician (41 images)
- John Hammond, businessman/Jurassic Park owner (36 images)
- Owen Grady, dinosaur researcher (35 images)
This dataset was constructed in < 30 minutes using the method discussed in my How to (quickly) build a deep learning image dataset tutorial. Given this dataset of images we’ll:
- Create the 128-d embeddings for each face in the dataset
- Use these embeddings to recognize the faces of the characters in both images and video streams
Face recognition project structure
Our project structure can be seen by examining the output from the tree command:
$ tree --filelimit 10 --dirsfirst . ├── dataset │ ├── alan_grant [22 entries] │ ├── claire_dearing [53 entries] │ ├── ellie_sattler [31 entries] │ ├── ian_malcolm [41 entries] │ ├── john_hammond [36 entries] │ └── owen_grady [35 entries] ├── examples │ ├── example_01.png │ ├── example_02.png │ └── example_03.png ├── output │ └── lunch_scene_output.avi ├── videos │ └── lunch_scene.mp4 ├── search_bing_api.py ├── encode_faces.py ├── recognize_faces_image.py ├── recognize_faces_video.py ├── recognize_faces_video_file.py └── encodings.pickle 10 directories, 11 files
Our project has 4 top-level directories:
dataset/: Contains face images for six characters organized into subdirectories based on their respective names.examples/: Has three face images for testing that are not in the dataset.output/: This is where you can store your processed face recognition videos. I’m leaving one of mine in the folder — the classic “lunch scene” from the original Jurassic Park movie.videos/: Input videos should be stored in this folder. This folder also contains the “lunch scene” video but it hasn’t undergone our face recognition system yet.
We also have 6 files in the root directory:
search_bing_api.py: Step 1 is to build a dataset (I’ve already done this for you). To learn how to use the Bing API to build a dataset with my script, just see this blog post.encode_faces.py: Encodings (128-d vectors) for faces are built with this script.recognize_faces_image.py: Recognize faces in a single image (based on encodings from your dataset).recognize_faces_video.py: Recognize faces in a live video stream from your webcam and output a video.recognize_faces_video_file.py: Recognize faces in a video file residing on disk and output the processed video to disk. I won’t be discussing this file today as the bones are from the same skeleton as the video stream file.encodings.pickle: Facial recognition encodings are generated from your dataset viaencode_faces.pyand then serialized to disk.
After a dataset of images is created (with search_bing_api.py), we’ll run encode_faces.py to build the embeddings.
From there, we’ll run the recognize scripts to actually recognize the faces.
Encoding the faces using OpenCV and deep learning

face_recognition module method generates a 128-d real-valued number feature vector per face.Before we can recognize faces in images and videos, we first need to quantify the faces in our training set. Keep in mind that we are not actually training a network here — the network has already been trained to create 128-d embeddings on a dataset of ~3 million images.
We certainly could train a network from scratch or even fine-tune the weights of an existing model but that is more than likely overkill for many projects. Furthermore, you would need a lot of images to train the network from scratch.
Instead, it’s easier to use the pre-trained network and then use it to construct 128-d embeddings for each of the 218 faces in our dataset.
Then, during classification, we can use a simple k-NN model + votes to make the final face classification. Other traditional machine learning models can be used here as well.
To construct our face embeddings open up encode_faces.py from the “Downloads” associated with this blog post:
# import the necessary packages from imutils import paths import face_recognition import argparse import pickle import cv2 import os
First, we need to import required packages. Again, take note that this script requires imutils, face_recognition, and OpenCV installed. Scroll up to the “Install your face recognition libraries” to make sure you have the libraries ready to go on your system.
Let’s handle our command line arguments that are processed at runtime with argparse :
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
If you’re new to PyImageSearch, let me direct your attention to the above code block which will become familiar to you as you read more of my blog posts. We’re using argparse to parse command line arguments. When you run a Python program in your command line, you can provide additional information to the script without leaving your terminal. Lines 10-17 do not need to be modified as they parse input coming from the terminal. Check out my blog post about command line arguments if these lines look unfamiliar.
Let’s list out the argument flags and discuss them:
--dataset: The path to our dataset (we created a dataset withsearch_bing_api.pydescribed in method #2 of last week’s blog post).--encodings: Our face encodings are written to the file that this argument points to.--detection-method: Before we can encode faces in images we first need to detect them. Or two face detection methods include eitherhogorcnn. Those two flags are the only ones that will work for--detection-method.
Now that we’ve defined our arguments, let’s grab the paths to the files in our dataset (as well as perform two initializations):
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the list of known encodings and known names
knownEncodings = []
knownNames = []
Line 21 uses the path to our input dataset directory to build a list of all imagePaths contained therein.
We also need to initialize two lists before our loop, knownEncodings and knownNames , respectively. These two lists will contain the face encodings and corresponding names for each person in the dataset (Lines 24 and 25).
It’s time to begin looping over our Jurassic Park character faces!
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the input image and convert it from BGR (OpenCV ordering)
# to dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
This loop will cycle 218 times corresponding to our 218 face images in the dataset. We’re looping over the paths to each of the images on Line 28.
From there, we’ll extract the name of the person from the imagePath (as our subdirectory is named appropriately) on Line 32.
Then let’s load the image while passing the imagePath to cv2.imread (Line 36).
OpenCV orders color channels in BGR, but the dlib actually expects RGB. The face_recognition module uses dlib, so before we proceed, let’s swap color spaces on Line 37, naming the new image rgb.
Next, let’s localize the face and compute encodings:
# detect the (x, y)-coordinates of the bounding boxes # corresponding to each face in the input image boxes = face_recognition.face_locations(rgb, model=args["detection_method"]) # compute the facial embedding for the face encodings = face_recognition.face_encodings(rgb, boxes) # loop over the encodings for encoding in encodings: # add each encoding + name to our set of known names and # encodings knownEncodings.append(encoding) knownNames.append(name)
This is the fun part of the script!
For each iteration of the loop, we’re going to detect a face (or possibly multiple faces and assume that it is the same person in multiple locations of the image — this assumption may or may not hold true in your own images so be careful here).
For example, let’s say that rgb contains a picture (or pictures) of Ellie Sattler’s face.
Lines 41 and 42 actually find/localize the faces of her resulting in a list of face boxes. We pass two parameters to the face_recognition.face_locations method:
rgb: Our RGB image.model: Eithercnnorhog(this value is contained within our command line arguments dictionary associated with the"detection_method"key). The CNN method is more accurate but slower. HOG is faster but less accurate.
Then, we’re going to turn the bounding boxes of Ellie Sattler’s face into a list of 128 numbers on Line 45. This is known as encoding the face into a vector and the face_recognition.face_encodings method handles it for us.
From there we just need to append the Ellie Sattler encoding and name to the appropriate list (knownEncodings and knownNames).
We’ll continue to do this for all 218 images in the dataset.
What would be the point of encoding the images unless we could use the encodings in another script which handles the recognition?
Let’s take care of that now:
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
Line 56 constructs a dictionary with two keys — "encodings" and "names".
From there Lines 57-59 dump the names and encodings to disk for future recall.
How should I run the encode_faces.py script in the terminal?
To create our facial embeddings open up a terminal and execute the following command:
$ python encode_faces.py --dataset dataset --encodings encodings.pickle [INFO] quantifying faces... [INFO] processing image 1/218 [INFO] processing image 2/218 [INFO] processing image 3/218 ... [INFO] processing image 216/218 [INFO] processing image 217/218 [INFO] processing image 218/218 [INFO] serializing encodings... $ ls -lh encodings* -rw-r--r--@ 1 adrian staff 234K May 29 13:03 encodings.pickle
As you can see from our output, we now have a file named encodings.pickle — this file contains the 128-d face embeddings for each face in our dataset.
On my Titan X GPU, processing the entire dataset took a little over a minute, but if you’re using a CPU, be prepared to wait awhile for this script to complete!
On my Macbook Pro (no GPU), encoding 218 images required 21min 20sec.
You should expect much faster speeds if you have a GPU and compiled dlib with GPU support.
Recognizing faces in images

face_recognition Python module.Now that we have created our 128-d face embeddings for each image in our dataset, we are now ready to recognize faces in image using OpenCV, Python, and deep learning.
Open up recognize_faces_image.py and insert the following code (or better yet, grab the files and image data associated with this blog post from the “Downloads” section found at the bottom of this post, and follow along):
# import the necessary packages
import face_recognition
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
This script requires just four imports on Lines 2-5. The face_recognition module will do the heavy lifting and OpenCV will help us to load, convert, and display the processed image.
We’ll parse three command line arguments on Lines 8-15:
--encodings: The path to the pickle file containing our face encodings.--image: This is the image that is undergoing facial recognition.--detection-method: You should be familiar with this one by now — we’re either going to use ahogorcnnmethod depending on the capability of your system. For speed, choosehogand for accuracy, choosecnn.
IMPORTANT! If you are:
- Running the face recognition code on a CPU
- OR you using a Raspberry Pi
- …you’ll want to set the
--detection-methodtohogas the CNN face detector is (1) slow without a GPU and (2) the Raspberry Pi won’t have enough memory to run the CNN either.
From there, let’s load the pre-computed encodings + face names and then construct the 128-d face encoding for the input image:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# load the input image and convert it from BGR to RGB
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes corresponding
# to each face in the input image, then compute the facial embeddings
# for each face
print("[INFO] recognizing faces...")
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
# initialize the list of names for each face detected
names = []
Line 19 loads our pickled encodings and face names from disk. We’ll need this data later during the actual face recognition step.
Then, on Lines 22 and 23 we load and convert the input image to rgb color channel ordering (just as we did in the encode_faces.py script).
We then proceed to detect all faces in the input image and compute their 128-d encodings on Lines 29-31 (these lines should also look familiar).
Now is a good time to initialize a list of names for each face that is detected — this list will be populated in the next step.
Next, let’s loop over the facial encodings:
# loop over the facial embeddings for encoding in encodings: # attempt to match each face in the input image to our known # encodings matches = face_recognition.compare_faces(data["encodings"], encoding) name = "Unknown"
On Line 37, we begin to loop over the face encodings computed from our input image.
Then the facial recognition magic happens!
We attempt to match each face in the input image (encoding) to our known encodings dataset (held in data["encodings"]) using face_recognition.compare_faces (Lines 40 and 41).
This function returns a list of True /False values, one for each image in our dataset. For our Jurassic Park example, there are 218 images in the dataset and therefore the returned list will have 218 boolean values.
Internally, the compare_faces function is computing the Euclidean distance between the candidate embedding and all faces in our dataset:
- If the distance is below some tolerance (the smaller the tolerance, the more strict our facial recognition system will be) then we return
True, indicating the faces match. - Otherwise, if the distance is above the tolerance threshold we return
Falseas the faces do not match.
Essentially, we are utilizing a “more fancy” k-NN model for classification. Be sure to refer to the compare_faces implementation for more details.
The name variable will eventually hold the name string of the person — for now, we leave it as "Unknown" in case there are no “votes” (Line 42).
Given our matches list we can compute the number of “votes” for each name (number of True values associated with each name), tally up the votes, and select the person’s name with the most corresponding votes:
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number of
# votes (note: in the event of an unlikely tie Python will
# select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
If there are any True votes in matches (Line 45) we need to determine the indexes of where these True values are in matches. We do just that on Line 49 where we construct a simple list of matchedIdxs which might look like this for example_01.png:
(Pdb) matchedIdxs [35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 71, 72, 73, 74, 75]
We then initialize a dictionary called counts which will hold the character name as the key and the number of votes as the value (Line 50).
From there, let’s loop over the matchedIdxs and set the value associated with each name while incrementing it as necessary in counts . The counts dictionary might look like this for a high vote score for Ian Malcolm:
(Pdb) counts
{'ian_malcolm': 40}
Recall that we only have 41 pictures of Ian in the dataset, so a score of 40 with no votes for anybody else is extremely high.
Line 61 extracts the name with the most votes from counts , in this case, it would be 'ian_malcolm'.
The second iteration of our loop (as there are two faces in our example image) of the main facial encodings loop yields the following for counts:
(Pdb) counts
{'alan_grant': 5}
That is definitely a smaller vote score, but still, there is only one name in the dictionary so we likely have found Alan Grant.
Note: The PDB Python Debugger was used to verify values of the counts dictionary. PDB usage is outside the scope of this blog post; however, you can discover how to use it on the Python docs page.
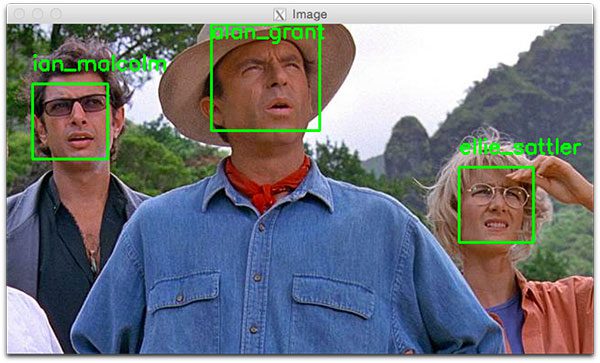
As shown in Figure 5 below, both Ian Malcolm and Alan Grant have been correctly recognized, so this part of the script is working well.
Let’s move on and loop over the bounding boxes and labeled names for each person and draw them on our output image for visualization purposes:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# draw the predicted face name on the image
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
On Line 67, we begin looping over the detected face bounding boxes and predicted names. To create an iterable object so we can easily loop through the values, we call zip(boxes, names) resulting in tuples that we can extract the box coordinates and name from.
We use the box coordinates to draw a green rectangle on Line 69.
We also use the coordinates to calculate where we should draw the text for the person’s name (Line 70) followed by actually placing the name text on the image (Lines 71 and 72). If the face bounding box is at the very top of the image, we need to move the text below the top of the box (handled on Line 70), otherwise, the text would be cut off.
We then proceed to display the image until a key is pressed (Lines 75 and 76).
How should you run the facial recognition Python script?
Using your terminal, first ensure you’re in your respective Python correct virtual environment with the workon command (if you are using a virtual environment, of course).
Then run the script while providing the two command line arguments at a minimum. If you choose to use the HoG method, be sure to pass --detection-method hog as well (otherwise it will default to the deep learning detector).
Let’s go for it!
To recognize a face using OpenCV and Python open up your terminal and execute our script:
$ python recognize_faces_image.py --encodings encodings.pickle \ --image examples/example_01.png [INFO] loading encodings... [INFO] recognizing faces...

A second face recognition example follows:
$ python recognize_faces_image.py --encodings encodings.pickle \ --image examples/example_03.png [INFO] loading encodings... [INFO] recognizing faces...
Recognizing faces in video
Now that we have applied face recognition to images let’s also apply face recognition to videos (in real-time) as well.
Important Performance Note: The CNN face recognizer should only be used in real-time if you are working with a GPU (you can use it with a CPU, but expect less than 0.5 FPS which makes for a choppy video). Alternatively (you are using a CPU), you should use the HoG method (or even OpenCV Haar cascades covered in a future blog post) and expect adequate speeds.
The following script draws many parallels from the previous recognize_faces_image.py script. Therefore I’ll be breezing past what we’ve already covered and just review the video components so that you understand what is going on.
Once you’ve grabbed the “Downloads”, open up recognize_faces_video.py and follow along:
# import the necessary packages
from imutils.video import VideoStream
import face_recognition
import argparse
import imutils
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-o", "--output", type=str,
help="path to output video")
ap.add_argument("-y", "--display", type=int, default=1,
help="whether or not to display output frame to screen")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
We import packages on Lines 2-8 and then proceed to parse our command line arguments on Lines 11-20.
We have four command line arguments, two of which you should recognize from above (--encodings and --detection-method). The other two arguments are:
--output: The path to the output video.--display: A flag which instructs the script to display the frame to the screen. A value of1displays and a value of0will not display the output frames to our screen.
From there we’ll load our encodings and start our VideoStream:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# initialize the video stream and pointer to output video file, then
# allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
writer = None
time.sleep(2.0)
To access our camera we’re using the VideoStream class from imutils. Line 29 starts the stream. If you have multiple cameras on your system (such as a built-in webcam and an external USB cam), you can change the src=0 to src=1 and so forth.
We’ll be optionally writing processed video frames to disk later, so we initialize writer to None (Line 30). Sleeping for 2 complete seconds allows our camera to warm up (Line 31).
From there we’ll start a while loop and begin to grab and process frames:
# loop over frames from the video file stream while True: # grab the frame from the threaded video stream frame = vs.read() # convert the input frame from BGR to RGB then resize it to have # a width of 750px (to speedup processing) rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) rgb = imutils.resize(frame, width=750) r = frame.shape[1] / float(rgb.shape[1]) # detect the (x, y)-coordinates of the bounding boxes # corresponding to each face in the input frame, then compute # the facial embeddings for each face boxes = face_recognition.face_locations(rgb, model=args["detection_method"]) encodings = face_recognition.face_encodings(rgb, boxes) names = []
Our loop begins on Line 34 and the first step we take is to grab a frame from the video stream (Line 36).
The remaining Lines 40-50 in the above code block are nearly identical to the lines in the previous script with the exception being that this is a video frame and not a static image. Essentially we read the frame, preprocess, and then detect face bounding boxes + calculate encodings for each bounding box.
Next, let’s loop over the facial encodings associated with the faces we have just found:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number
# of votes (note: in the event of an unlikely tie Python
# will select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
In this code block, we loop over each of the encodings and attempt to match the face. If there are matches found, we count the votes for each name in the dataset. We then extract the highest vote count and that is the name associated with the face. These lines are identical to the previous script we reviewed, so let’s move on.
In this next block, we loop over the recognized faces and proceed to draw a box around the face and the display name of the person above the face:
# loop over the recognized faces for ((top, right, bottom, left), name) in zip(boxes, names): # rescale the face coordinates top = int(top * r) right = int(right * r) bottom = int(bottom * r) left = int(left * r) # draw the predicted face name on the image cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 2) y = top - 15 if top - 15 > 15 else top + 15 cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
Those lines are identical too, so let’s focus on the video-related code.
Optionally, we’re going to write the frame to disk, so let’s see how writing video to disk with OpenCV works:
# if the video writer is None *AND* we are supposed to write # the output video to disk initialize the writer if writer is None and args["output"] is not None: fourcc = cv2.VideoWriter_fourcc(*"MJPG") writer = cv2.VideoWriter(args["output"], fourcc, 20, (frame.shape[1], frame.shape[0]), True) # if the writer is not None, write the frame with recognized # faces to disk if writer is not None: writer.write(frame)
Assuming we have an output file path provided in the command line arguments and we haven’t already initialized a video writer (Line 99), let’s go ahead and initialize it.
On Line 100, we initialize the VideoWriter_fourcc. FourCC is a 4-character code and in our case, we’re going to use the “MJPG” 4-character code.
From there, we’ll pass that object into the VideoWriter along with our output file path, frames per second target, and frame dimensions (Lines 101 and 102).
Finally, if the writer exists, we can go ahead and write a frame to disk (Lines 106 and 107).
Let’s handle whether or not we should display the face recognition video frames on the screen:
# check to see if we are supposed to display the output frame to
# the screen
if args["display"] > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
If our display command line argument is set, we go ahead and display the frame (Line 112) and check if the quit key ("q") has been pressed (Lines 113-116), at which point we’d break out of the loop (Line 117).
Lastly, let’s perform our housekeeping duties:
# do a bit of cleanup cv2.destroyAllWindows() vs.stop() # check to see if the video writer point needs to be released if writer is not None: writer.release()
In Lines 120-125, we clean up and release the display, video stream, and video writer.
Are you ready to see the script in action?
To demonstrate real-time face recognition with OpenCV and Python in action, open up a terminal and execute the following command:
$ python recognize_faces_video.py --encodings encodings.pickle \ --output output/webcam_face_recognition_output.avi --display 1 [INFO] loading encodings... [INFO] starting video stream...
Below you can find an output example video that I recorded demonstrating the face recognition system in action:
Face recognition in video files
As I mentioned in our “Face recognition project structure” section, there’s an additional script included in the “Downloads” for this blog post — recognize_faces_video_file.py.
This file is essentially the same as the one we just reviewed for the webcam except it will take an input video file and generate an output video file if you’d like.
I applied our face recognition code to the popular “lunch scene” from the original Jurassic Park movie where the cast is sitting around a table sharing their concerns with the park:
$ python recognize_faces_video_file.py --encodings encodings.pickle \ --input videos/lunch_scene.mp4 --output output/lunch_scene_output.avi \ --display 0
Here’s the result:
Note: Recall that our model was trained on four members of the original cast: Alan Grant, Ellie Sattler, Ian Malcolm, and John Hammond. The model was not trained on Donald Gennaro (the lawyer) which is why his face is labeled as “Unknown”. This behavior was by design (not an accident) to show that our face recognition system can recognize faces it was trained on while leaving faces it cannot recognize as “Unknown”.
And in the following video I have put together a “highlight reel” of Jurassic Park and Jurassic World clips, mainly from the trailers:
As we can see, our face recognition and OpenCV code works quite well!
Can I use this face recognizer code on the Raspberry Pi?
Kinda, sorta. There are a few limitations though:
- The Raspberry Pi does not have enough memory to utilize the more accurate CNN-based face detector…
- …so we are limited to HOG instead
- Except that HOG is far too slow on the Pi for real-time face detection…
- …so we need to utilize OpenCV’s Haar cascades
And once you get it running you can expect only 1-2 FPS, and even reaching that level of FPS takes a few tricks.
The good news is that I’ll be back next week to discuss how to run our face recognizer on the Raspberry Pi, so stay tuned!
Alternative face recognition methods
The face recognition method we used inside this tutorial was based on a combination of Davis King’s dlib library and Adam Geitgey’s face_recognition module.
Davis has provided a ResNet-based siamese network that is super useful for face recognition tasks. Adam’s library provides a wrapper around dlib to make the face recognition functionality easier to use.
However, there are other face recognition methods that can be used, including both deep learning-based and traditional computer vision-based approaches.
To start, take a look at this tutorial on OpenCV Face Recognition which is a pure OpenCV-based face recognizer (i.e., no other libraries, such as dlib, scikit-image, etc., are required to perform face recognition). That said, dlib’s face recognizer does tend to be a bit more accurate, so keep that in mind when implementing face recognition models of your own.
For non-deep learning-based face recognition, I suggest taking a look at both Eigenfaces and Local Binary Patterns (LBPs) for face recognition:
These methods are less accurate than their deep learning-based face recognition counterparts, but tend to be much more computationally efficient and will run faster on embedded systems.
Face Recognition Application ideas
What can’t you build with face recognition? Seriously, it’s so useful to be able to recognize a person’s face.
Here are just a few ideas of what you can build
- Security
- Account logon
- Marketing applications
- Sales workflow
- Social media engagement meter
- Healthcare patient ID
- Voting ID
- Education safety and notification to parents and teachers
- Gaming ID and age determination to avoid collecting data on minors
- Library card replacement
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to perform face recognition with OpenCV, Python, and deep learning.
Additionally, we made use of Davis King’s dlib library and Adam Geitgey’s face_recognition module which wraps around dlib’s deep metric learning, making facial recognition easier to accomplish.
As we found out, our face recognition implementation is both:
- Accurate
- Capable of being executed in real-time with a GPU
I hope you enjoyed today’s blog post on face recognition!
To download the source code to this post, and be notified when future tutorials are published here on PyImageSearch, just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

