In this tutorial, you will learn how to change the input shape tensor dimensions for fine-tuning using Keras. After going through this guide you’ll understand how to apply transfer learning to images with different image dimensions than what the CNN was originally trained on.
A few weeks ago I published a tutorial on transfer learning with Keras and deep learning — soon after the tutorial was published, I received a question from Francesca Maepa who asked the following:
Do you know of a good blog or tutorial that shows how to implement transfer learning on a dataset that has a smaller shape than the pre-trained model?
I created a really good pre-trained model, and would like to use some features for the pre-trained model and transfer them to a target domain that is missing certain feature training datasets and I’m not sure if I’m doing it right.
Francesca asks a great question.
Typically we think of Convolutional Neural Networks as accepting fixed size inputs (i.e., 224×224, 227×227, 299×299, etc.).
But what if you wanted to:
- Utilize a pre-trained network for transfer learning…
- …and then update the input shape dimensions to accept images with different dimensions than what the original network was trained on?
Why might you want to utilize different image dimensions?
There are two common reasons:
- Your input image dimensions are considerably smaller than what the CNN was trained on and increasing their size introduces too many artifacts and dramatically hurts loss/accuracy.
- Your images are high resolution and contain small objects that are hard to detect. Resizing to the original input dimensions of the CNN hurts accuracy and you postulate increasing resolution will help improve your model.
In these scenarios, you would wish to update the input shape dimensions of the CNN and then be able to perform transfer learning.
The question then becomes, is such an update possible?
Yes, in fact, it is.
Change input shape dimensions for fine-tuning with Keras
2020-06-04 Update: This blog post is now TensorFlow 2+ compatible!
In the first part of this tutorial, we’ll discuss the concept of an input shape tensor and the role it plays with input image dimensions to a CNN.
From there we’ll discuss the example dataset we’ll be using in this blog post. I’ll then show you how to:
- Update the input image dimensions to pre-trained CNN using Keras.
- Fine-tune the updated CNN. Let’s get started!
What is an input shape tensor?

When working with Keras and deep learning, you’ve probably either utilized or run into code that loads a pre-trained network via:
model = VGG16(weights="imagenet")
The code above is initializing the VGG16 architecture and then loading the weights for the model (pre-trained on ImageNet).
We would typically use this code when our project needs to classify input images that have class labels inside ImageNet (as this tutorial demonstrates).
When performing transfer learning or fine-tuning you may use the following code to leave off the fully-connected (FC) layer heads:
model = VGG16(weights="imagenet", include_top=False)
We’re still indicating that the pre-trained ImageNet weights should be used, but now we’re setting include_top=False , indicating that the FC head should not be loaded.
This code would typically be utilized when you’re performing transfer learning either via feature extraction or fine-tuning.
Finally, we can update our code to include an input_tensor dimension:
model = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
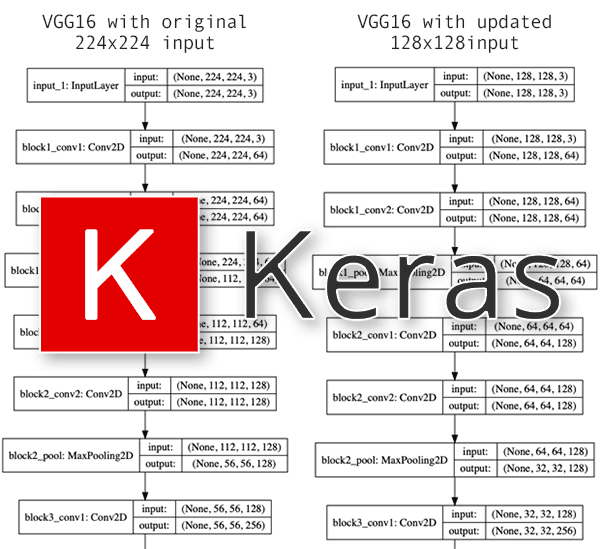
We’re still loading VGG16 with weights pre-trained on ImageNet and we’re still leaving off the FC layer heads…but now we’re specifying an input shape of 224×224x3 (which are the input image dimensions that VGG16 was originally trained on, as seen in Figure 1, left).
That’s all fine and good — but what if we now wanted to fine-tune our model on 128×128px images?
That’s actually just a simple update to our model initialization:
model = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(128, 128, 3)))
Figure 1 (right) provides a visualization of the network updating the input tensor dimensions — notice how the input volume is now 128x128x3 (our updated, smaller dimensions) versus the previous 224x224x3 (the original, larger dimensions).
Updating the input shape dimensions of a CNN via Keras is that simple!
But there are a few caveats to look out for.
Can I make the input dimensions anything I want?
There are limits to how much you can update the image dimensions, both from an accuracy/loss perspective and from limitations of the network itself.
Consider the fact that CNNs reduce volume dimensions via two methods:
- Pooling (such as max-pooling in VGG16)
- Strided convolutions (such as in ResNet)
If your input image dimensions are too small then the CNN will naturally reduce volume dimensions during the forward propagation and then effectively “run out” of data.
In that case your input dimensions are too small.
I’ve included an error of what happens during that scenario below when, for example, when using 48×48 input images, I received this error message:
ValueError: Negative dimension size caused by subtracting 4 from 1 for 'average_pooling2d_1/AvgPool' (op: 'AvgPool') with input shapes: [?,1,1,512].
Notice how Keras is complaining that our volume is too small. You will encounter similar errors for other pre-trained networks as well. When you see this type of error, you know you need to increase your input image dimensions.
You can also make your input dimensions too large.
You won’t run into any errors per se, but you may see your network fail to obtain reasonable accuracy due to the fact that there are not enough layers in the network to:
- Learn robust, discriminative filters.
- Naturally reduce volume size via pooling or strided convolution.
If that happens, you have a few options:
- Explore other (pre-trained) network architectures that are trained on larger input dimensions.
- Tune your hyperparameters exhaustively, focusing first on learning rate.
- Add additional layers to the network. For VGG16 you’ll use 3×3 CONV layers and max-pooling. For ResNet you’ll include residual layers with strided convolution.
The final suggestion will require you to update the network architecture and then perform fine-tuning on the newly initialized layers.
To learn more about fine-tuning and and transfer learning, along with my tips, suggestions, and best practices when training networks, make sure you refer to my book, Deep Learning for Computer Vision with Python.
Our example dataset

The dataset we’ll be using here today is a small subset of Kaggle’s Dogs vs. Cats dataset.
We also use this dataset inside Deep Learning for Computer Vision with Python to teach the fundamentals of training networks, ensuring that readers with either CPUs or GPUs can follow along and learn best practices when training models.
The dataset itself contains 2,000 images belonging to 2 classes (“cat” and dog”):
- Cat: 1,000 images
- Dog: 1,000 images
A visualization of the dataset can be seen in Figure 3 above.
In the remainder of this tutorial you’ll learn how to take this dataset and:
- Update the input shape dimensions for a pre-trained CNN.
- Fine-tune the CNN with the smaller image dimensions.
Configuring your development environment
To configure your system for this tutorial, I first recommend following either of these tutorials:
Either tutorial will help you configure you system with all the necessary software for this blog post in a convenient Python virtual environment.
Please note that PyImageSearch does not recommend or support Windows for CV/DL projects.
Project structure
Go ahead and grab the code + dataset from the “Downloads“ section of today’s blog post.
Once you’ve extracted the .zip archive, you may inspect the project structure using the tree command:
$ tree --dirsfirst --filelimit 10 . ├── dogs_vs_cats_small │ ├── cats [1000 entries] │ └── dogs [1000 entries] ├── plot.png └── train.py 3 directories, 2 files
Our dataset is contained within the dogs_vs_cats_small/ directory. The two subdirectories contain images of our classes. If you’re working with a different dataset be sure the structure is <dataset>/<class_name> .
Today we’ll be reviewing the train.py script. The training script generates plot.png containing our accuracy/loss curves.
Updating the input shape dimensions with Keras
It’s now time to update our input image dimensions with Keras and a pre-trained CNN.
Open up the train.py file in your project structure and insert the following code:
# import the necessary packages from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.layers import AveragePooling2D from tensorflow.keras.applications import VGG16 from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import Adam from tensorflow.keras.utils import to_categorical from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from imutils import paths import matplotlib.pyplot as plt import numpy as np import argparse import cv2 import os
Lines 2-20 import required packages:
tensorflow.kerasandsklearnare for deep learning/machine learning. Be sure to refer to my extensive deep learning book, Deep Learning for Computer Vision with Python, to become more familiar with the classes and functions we use from these tools.pathsfrom imutils traverses a directory and enables us to list all images in a directory.matplotlibwill allow us to plot our training accuracy/loss history.numpyis a Python package for numerical operations; one of the ways we’ll put it to work is for “mean subtraction”, a scaling/normalization technique.cv2is OpenCV.argparsewill be used to read and parse command line arguments.
Let’s go ahead and parse the command line arguments now:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-e", "--epochs", type=int, default=25,
help="# of epochs to train our network for")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
Our script accepts three command line arguments via Lines 23-30:
--dataset: The path to our input dataset. We’re using a condensed version of Dogs vs. Cats, but you could use other binary, 2-class datasets with little or no modification as well (provided they follow a similar structure).--epochs: The number of times we’ll pass our data through the network during training; by default, we’ll train for25epochs unless a different value is supplied.--plot: The path to our output accuracy/loss plot. Unless otherwise specified, the file will be namedplot.pngand placed in the project directory. If you are conducting multiple experiments, be sure to give your plots a different name each time for future comparison purposes.
Next, we will load and preprocess our images:
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths:
# extract the class label from the filename
label = imagePath.split(os.path.sep)[-2]
# load the image, swap color channels, and resize it to be a fixed
# 128x128 pixels while ignoring aspect ratio
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (128, 128))
# update the data and labels lists, respectively
data.append(image)
labels.append(label)
First, we grab our imagePaths on Line 35 and then initialize our data and labels (Lines 36 and 37).
Lines 40-52 loop over the imagePaths while first extracting the labels. Each image is loaded, the color channels are swapped, and the image is resized. The images and labels are added to the data and labels lists respectively.
VGG16 was trained on 224×224px images; however, I’d like to draw your attention to Line 48. Notice how we’ve resized our images to 128×128px. This resizing is an example of applying transfer learning on images with different dimensions.
Although Line 48 doesn’t fully answer Francesca Maepa’s question yet, we’re getting close.
Let’s go ahead and one-hot encode our labels as well as split our data:
# convert the data and labels to NumPy arrays data = np.array(data) labels = np.array(labels) # perform one-hot encoding on the labels lb = LabelBinarizer() labels = lb.fit_transform(labels) labels = to_categorical(labels) # partition the data into training and testing splits using 75% of # the data for training and the remaining 25% for testing (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, stratify=labels, random_state=42)
Lines 55 and 56 convert our data and labels to NumPy array format.
Then, Lines 59-61 perform one-hot encoding on our labels. Essentially, this process converts our two labels (“cat” and “dog”) to arrays indicating which label is active/hot. If a training image is representative of a dog, then the value would be [0, 1] where “dog” is hot. Otherwise, for a “cat”, the value would be [1, 0] .
To reinforce the point, if for example, we had 5 classes of data, a one-hot encoded array may look like [0, 0, 0, 1, 0] where the 4th element is hot indicating that the image is from the 4th class. For further details, please refer to Deep Learning for Computer Vision with Python.
Lines 65 and 66 mark 75% of our data for training and the remaining 25% for testing via the train_test_split function.
Let’s now initialize our data augmentation generator. We’ll also establish our ImageNet mean for mean subtraction:
# initialize the training data augmentation object trainAug = ImageDataGenerator( rotation_range=30, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest") # initialize the validation/testing data augmentation object (which # we'll be adding mean subtraction to) valAug = ImageDataGenerator() # define the ImageNet mean subtraction (in RGB order) and set the # the mean subtraction value for each of the data augmentation # objects mean = np.array([123.68, 116.779, 103.939], dtype="float32") trainAug.mean = mean valAug.mean = mean
Lines 69-76 initialize a data augmentation object for performing random manipulations on our input images during training.
Line 80 also takes advantage of the ImageDataGenerator class for validation, but without any parameters — we won’t manipulate validation images with the exception of performing mean subtraction.
Both training and validation/testing generators will conduct mean subtraction. Mean subtraction is a scaling/normalization technique proven to increase accuracy. Line 85 contains the mean for each respective RGB channel while Lines 86 and 87 are then populated with the value. Later, our data generators will automatically perform the mean subtraction on our training/validation data.
Note: I’ve covered data augmentation in detail in this blog post as well as in the Practitioner Bundle of Deep Learning for Computer Vision with Python. Scaling and normalization techniques such as mean subtraction are covered in DL4CV as well.
We’re performing transfer learning with VGG16. Let’s initialize the base model now:
# load VGG16, ensuring the head FC layer sets are left off, while at
# the same time adjusting the size of the input image tensor to the
# network
baseModel = VGG16(weights="imagenet", include_top=False,
input_tensor=Input(shape=(128, 128, 3)))
# show a summary of the base model
print("[INFO] summary for base model...")
print(baseModel.summary())
Lines 92 and 93 load VGG16 with an input shape dimension of 128×128 using 3 channels.
Remember, VGG16 was originally trained on 224×224 images — now we’re updating the input shape dimensions to handle 128×128 images.
Effectively, we have now fully answered Francesca Maepa’s question! We accomplished changing the input dimensions via two steps:
- We resized all of our input images to 128×128.
- Then we set the input
shape=(128, 128, 3).
Line 97 will print a model summary in our terminal so that we can inspect it. Alternatively, you may visualize the model graphically by studying Chapter 19 “Visualizing Network Architectures” of Deep Learning for Computer Vision with Python.
Since we’re performing transfer learning, the include_top parameter is set to False (Line 92) — we chopped off the head!
Now we’re going to perform surgery by erecting a new head and suturing it onto the CNN:
# construct the head of the model that will be placed on top of the # the base model headModel = baseModel.output headModel = AveragePooling2D(pool_size=(4, 4))(headModel) headModel = Flatten(name="flatten")(headModel) headModel = Dense(128, activation="relu")(headModel) headModel = Dropout(0.5)(headModel) headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become # the actual model we will train) model = Model(inputs=baseModel.input, outputs=headModel) # loop over all layers in the base model and freeze them so they will # *not* be updated during the first training process for layer in baseModel.layers: layer.trainable = False
Line 101 takes the output from the baseModel and sets it as input to the headModel .
From there, Lines 102-106 construct the rest of the head.
The baseModel is already initialized with ImageNet weights per Line 92. On Lines 114 and 115, we set the base layers in VGG16 as not trainable (i.e., they will not be updated during the backpropagation phase). Be sure to read my previous fine-tuning tutorial for further explanation.
We’re now ready to compile and train the model with our data:
# compile our model (this needs to be done after our setting our
# layers to being non-trainable)
print("[INFO] compiling model...")
opt = Adam(lr=1e-4)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network for a few epochs (all other layers
# are frozen) -- this will allow the new FC layers to start to become
# initialized with actual "learned" values versus pure random
print("[INFO] training head...")
H = model.fit(
x=trainAug.flow(trainX, trainY, batch_size=32),
steps_per_epoch=len(trainX) // 32,
validation_data=valAug.flow(testX, testY),
validation_steps=len(testX) // 32,
epochs=args["epochs"])
2020-06-04 Update: Formerly, TensorFlow/Keras required use of a method called .fit_generator in order to accomplish data augmentation. Now, the .fit method can handle data augmentation as well, making for more-consistent code. This also applies to the migration from .predict_generator to .predict. Be sure to check out my articles about fit and fit_generator as well as data augmentation.
Our model is compiled with the Adam optimizer and a 1e-4 learning rate (Lines 120-122).
We use "binary_crossentropy" for 2-class classification. If you have more than two classes of data, be sure to use "categorical_crossentropy" .
Lines 128-133 then train our transfer learning network. Our training and validation generators are put to work in the process.
Upon training completion, we’ll evaluate the network and plot the training history:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX.astype("float32"), batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = args["epochs"]
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
2020-06-04 Update: In order for this plotting snippet to be TensorFlow 2+ compatible the H.history dictionary keys are updated to fully spell out “accuracy” sans “acc” (i.e., H.history["val_accuracy"] and H.history["accuracy"]). It is semi-confusing that “val” is not spelled out as “validation”; we have to learn to love and live with the API and always remember that it is a work in progress that many developers around the world contribute to.
Lines 137-139 evaluate our model and print a classification report for statistical analysis.
We then employ matplotlib to plot our accuracy and loss history during training (Lines 142-152). The plot figure is saved to disk via Line 153.
Fine-tuning a CNN using the updated input dimensions

To fine-tune our CNN using the updated input dimensions first make sure you’ve used the “Downloads” section of this guide to download the (1) source code and (2) example dataset.
From there, open up a terminal and execute the following command:
$ python train.py --dataset dogs_vs_cats_small --epochs 25 Using TensorFlow backend. [INFO] loading images... [INFO] summary for base model... Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 128, 128, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 8, 8, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0
Our first set of output shows our updated input shape dimensions.
Notice how our input_1 (i.e., the InputLayer) has input dimensions of 128x128x3 versus the normal 224x224x3 for VGG16.
The input image will then forward propagate through the network until the final MaxPooling2D layer (i.e., block5_pool).
At this point, our output volume has dimensions of 4x4x512 (for reference, VGG16 with a 224x224x3 input volume would have the shape 7x7x512 after this layer).
Note: If your input image dimensions are too small then you risk the model, effectively, reducing the tensor volume into “nothing” and then running out of data, leading to an error. See the “Can I make the input dimensions anything I want?” section of this post for more details.
We then flatten that volume and apply the FC layers from the headModel , ultimately leading to our final classification.
Once our model is constructed we can then fine-tune it:
_________________________________________________________________
None
[INFO] compiling model...
[INFO] training head...
Epoch 1/25
46/46 [==============================] - 4s 94ms/step - loss: 4.8791 - accuracy: 0.5334 - val_loss: 2.3190 - val_accuracy: 0.6854
Epoch 2/25
46/46 [==============================] - 3s 73ms/step - loss: 3.3768 - accuracy: 0.6274 - val_loss: 1.2106 - val_accuracy: 0.8167
Epoch 3/25
46/46 [==============================] - 3s 76ms/step - loss: 2.7036 - accuracy: 0.6887 - val_loss: 0.9802 - val_accuracy: 0.8333
Epoch 4/25
46/46 [==============================] - 3s 73ms/step - loss: 2.1932 - accuracy: 0.7105 - val_loss: 0.8585 - val_accuracy: 0.8583
Epoch 5/25
46/46 [==============================] - 3s 73ms/step - loss: 1.9197 - accuracy: 0.7425 - val_loss: 0.6756 - val_accuracy: 0.9021
...
46/46 [==============================] - 3s 76ms/step - loss: 0.6613 - accuracy: 0.8495 - val_loss: 0.4479 - val_accuracy: 0.9083
Epoch 21/25
46/46 [==============================] - 3s 74ms/step - loss: 0.6561 - accuracy: 0.8413 - val_loss: 0.4484 - val_accuracy: 0.9000
Epoch 22/25
46/46 [==============================] - 4s 95ms/step - loss: 0.5216 - accuracy: 0.8508 - val_loss: 0.4476 - val_accuracy: 0.9021
Epoch 23/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5484 - accuracy: 0.8488 - val_loss: 0.4420 - val_accuracy: 0.9021
Epoch 24/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5658 - accuracy: 0.8492 - val_loss: 0.4504 - val_accuracy: 0.8938
Epoch 25/25
46/46 [==============================] - 3s 70ms/step - loss: 0.5334 - accuracy: 0.8529 - val_loss: 0.4096 - val_accuracy: 0.8979
[INFO] evaluating network...
precision recall f1-score support
cats 0.91 0.88 0.89 250
dogs 0.89 0.91 0.90 250
accuracy 0.90 500
macro avg 0.90 0.90 0.90 500
weighted avg 0.90 0.90 0.90 500
At the end of fine-tuning we see that our model has obtained 90% accuracy, respectable given our small image dataset.
As Figure 4 demonstrates, our training is also quite stable as well with no signs of overfitting.
More importantly, you now know how to change the input image shape dimensions of a pre-trained network and then apply feature extraction/fine-tuning using Keras!
Be sure to use this tutorial as a template for whenever you need to apply transfer learning to a pre-trained network with different image dimensions than what it was originally trained on.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to change input shape dimensions for fine-tuning with Keras.
We typically perform such an operation when we want to apply transfer learning, including both feature extraction and fine-tuning.
Using the methods in this guide, you can update your input image dimensions for your pre-trained CNN and then perform transfer learning; however, there are two caveats you need to look out for:
- If your input images are too small, Keras will error out.
- If your input images are too large, you may not obtain your desired accuracy.
Be sure to refer to the “Can I make the input dimensions anything I want?” section of this post for more details on these caveats, including suggestions on how to solve them.
I hope you enjoyed this tutorial!
To download the source code to this post, and be notified when future tutorials are published here on PyImageSearch, just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Adrian,
Thanks for the extremely cool post.
Thanks David, I’m glad you liked it!
This is interesting, I’ve not gotten into training or re-training models yet, but I’ve quite a lot of experience using the MobileNet-SSD and MobileNet-SSD-V2 models from your OpenVINO and Coral tutorials on 1920×1080 and 1280×720 images from real security cameras for “person detection” — in real world varying lighting and weather conditions.
I’m amazed how well they both detect when a 1920×1080 image is resized to 300×300 for the inference. OTOH 4K (3840×2160) is definitely too much resolution.
My goal for security system purposes is to make the false detection rate be as close to zero as possible, false negatives are of little consequence if the frame rate is decent as the person will be detected as they move to more “favorable” locations or orientations within the frame.
My most successful approach so far has been to run with a fairly low initial detection confidence (~0.65) and then crop the full image to the detection box (startX, startY, endX, endY) and rerun the inference requiring a higher confidience (~0.75) to verify.
I’m currently testing in 15 camera rtsp streams with the images pushed to the AI as mqtt buffers to two simultaneously running systems (so each system gets the “same” images) one using MobileNet-SSDv2 on the Coral TPH the other using NCS2 with MobileNet-SSD
So far I’ve got the false detection rate well below 1 per million and getting lower as more images continue to be processes without a false positive on either system!
Debugging code I’ve inserted shows the Coco trained MobileNetSSDv2 is significantly better in both initial detection sensitivity and verification (many fewer detections are “wrongly” rejected because the zoomed image failed to increase the confidence). Reduction of confidence on zoomed false detections (plants, bushes, trees, background clutter, vehicles etc.) has been the key to the system improvement. On balance I’d say the lowering of the initial confidence threshold has more than made up for the “true detecitons” lost from failure to gain enough confidence when zoomed for verification.
So to modify he question of this topic, given a better model for a different tensor processor architecture now feasible is it to convert to an other tesnor coprocessor? We have NCS2, Coral TPH and Jetson Nano at present with more expected on the market soon.
Thanks for detailing your project, Wally!
As for converting to different coprocessors it’s a bit too early to say there. I’ve been doing work with the NCS, Coral, and Nano but I haven’t found an easy way to convert between their own optimized versions.
I have a question about the other end. I have a nicely trained network that extracts features from an image. I also have observations that are the xyz velocities of my robot. I’d like to combine the outputs from the network and the velocities to use as input to a couple fully connected layers. Then train from the output of the fully connected layers.
I have this currently working by using openCV to extract features (e.g., green balls and red balls), outputting the size and pixel coordinates of the largest red ball and the largest green ball. I take those values along with the robot velocities, normalize each one, then use that as input to two fully connected layers and output a selected action for the robot (e.g., move forward, turn right,..).
Is there someway to back propagate the fully connected layers up into a CNN, so that I can train the CNN to recognize whatever features are important, rather than having to pick my own features and use openCV to find them?
My current thought is to just have some extra outputs from the CNN that I then ignore, substituting the velocities for those values as inputs to the fully connected layers, but this is clearly a kludge.
So if I understand correctly, you:
1. Have some various data points collected from a different sensor.
2. Are using a CNN for feature extraction
And then you want to combine the data points from the sensors with the CNN features and then train a separate model which could be Logistic Regression, SVM, or another NN?
I guess I would tell you not to limit yourself to a NN. Why not something more straight forward? If you think that the dimensionality of the features from the CNN might be an issue you should consider applying feature selection on the extracted features (scikit-learn can help with that).
That’s a good point. Something like a decision tree model may work well. But for now, I have a framework that is working really well and I’m hoping to slightly generalize it by substituting a CNN for the openCV part. Is there some way to combine outputs from a CNN and another sensor (e.g., velocities), feed that combination to a network, and then be able to backpropigate from the bottom back up through the CNN?
Trying to do that with Tensorflow has me in “placeholder hell.” Specifically, I tried to take the outputs from the CNN and add three more nodes for normalized velocities, and put all that as input to a fully connected net, then run the entire thing. Couldn’t get it to go.
My next thought is to use the velocities as bias inputs to the last three output nodes of the CNN. Basically, force those nodes to be zero, then the velocities go in as biases, and the whole thing will train. But this seems likely to fail, as it implies that pixel images have some spatial relationship (it is a CNN) to the velocities, when they really don’t.
You could do something like multi-input and multiple outputs but I really think it’s overkill and not the way to go.
I agree that for this particular project, it’s overkill, but in the future when there are many different types of inputs, it could be very useful.
The post you referenced is exactly what I was looking for.
Thanks once again for the outstanding guidance!
Hi Adrain ,
Thanks for great post.
One thing I would like to ask.While working with satellite image classification(sat-4 and sat-6 dataset) I was stuck with similar issue as number of channel are 4(in my case).
Is there a way around to number of channels?
Thanks
Binary_classification. We may prefer last layer is Dense(1, activation =’sigmoid’) instead of Dense(2, activaiton =’softmax’) .
Thanks Adrian for this very good explanation. you use transfer learning for fine-tune the pre-trained model but what if I want to use the pretrained model as feature extractor to the target domain and the target domain images with different dimensions? There will be a problem in CNN dimensions since the target domain images need to propagate forward in the pretrained model.
Why not just resize your input images to a fixed, known size and then forward propagate for feature extraction? That will ensure the output volumes are the same size.
Hi Mr. Adrian, really thank you for you tutorial. this was a thing that wasn’t in the book and it was very important, so I’m very happy about it. It is possible that you do a tutorial on how to do this but with images larger than 224×224, that which you said: “images are high resolution and contain small objects that are hard to detect”, is exactly what happens to me in eye fundus images, it would be a great help to me, thank you.
Hey Victor — would you be able to share your dataset with myself and others? If so, I can take a look and potentially it could be made into a blog post.
Hey Adrian,
Thanks a lot for your great post. I have a trained/fine-tune a model using transfer learning and my base model is vgg16 with input shape of 224×224. If I increase my input size does this help the model to generalize better? My input images are definitely larger than 224×224.
You would need to run that as an experiment and verify. Every dataset is different so it’s hard for me to provide that level of general advice.
I been trying to use VGGFace16(weights=”imagenet”, include_top=False,input_tensor=Input(shape=(128, 128, 3))) with smaller side that 197x197x3 but it does no allow me, what can I do?
Thanks.
Hey Oscar — I replied to your thread in the PyImageSearch Gurus forums, can you check there instead? Thanks!
Hi Adrian,
Can I use asymmetric shape input in a ResNet model? The shape could be 256×128?
Yes, you can use asymmetric shape, provided that you don’t run into the dimension issues highlighted in the post.
Hey Adrian,
Thanks a lot for your great post, I want to How to change the input layer size of a pre_trained vgg16 from 227x227x3 to 32x32x1? i want to chande the chanel of the input of CNN. how can i do this?
You cannot do that. Just expand your input image to 3 channels:
image = np.dstack([image] * 3)That will create a 3 channel image out of a 1 channel image.
Hi, Adrian!
Thank you for the post.
I didn’t understand what happening with the weights in the network when we resize the input?
It is clear to me that if we change the head – then the output adjusted to the problem.
If we change the input – how does the network still works?
Weights are averaging or smth. else?
Best regards,
Evgeny
We’re fine-tuning the network. If you’re new to fine-tuning refer to this tutorial or Deep Learning for Computer Vision with Python.
Hi Adrian,
Thank you for your great post.
I am not sure if you are familiar with progressive resizing. I knew that fastai library implemented this method to train CNN from a small input size to a larger input size step-by-step. I hope you could write a post about this using Keras.
I have heard of progressive resizing before and used it before. I’m debating on whether I want to write a tutorial on it. I’ll definitely let you know if I do!
Hi Adrian,
Thanks for the excellent post on learning how to change the input shape tensor dimensions for fine-tuning using Keras.
Kindly look at the following paper which looks at scaling the Width, height and resolution “simultaneously” and shed light/or tutorial blog on its implementation.
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
authored by Mingxing Tan and Quoc V. Le.
Bro can you explain me implementation of ssd (single shot multibox detector) from scratch it’s really helpful for me..
I cover Single Shot Detectors in detail inside Deep Learning for Computer Vision with Python.
Can you please explain me the parameters “step_per_epoch” and “validation_steps” in fit or fit_generator method in keras.
The “steps_per_epoch” is the number of batches per epoch, meaning how many batches of data are there per epoch. You determine the steps per epoch by dividing the total number of training images by the batch size (same goes for the validation steps). To learn more about these values you should read Deep Learning for Computer Vision with Python.
Hellow sir Adrian,
Thank you very much.. this makes my project complete…
Congrats on completing your project!
Hi adrian,
Do you also have some tips on how to change input shape dimensions for fine-tuning with pytorch. For my case, the trained network is based on 224×224 but my image input is 64×64. Thus, how do we adjust the weight for fine tuning? Hope you can share some tips.
thank you in advance.
Sorry, I don’t have any guides on PyTorch.
Hello, thanks for this cool tutorial!
One question:
Can i just load a pre trained model on imagenet like vgg16, train it with my dataset but with shape=128, and then use transfer learning with my same model but with input shape=224? and re train it?
thank you!
Does this work if the image dimension is 64x64x1? Basically, there is only one channel rather than 3 channels.
Just stack your 1 channel image to from a 3 channel image:
output = np.stack([image] * 3)Hi Adrian,
Nice tutorial.
I just have one question. When we implement transfer learning on a dataset with a smaller shape than the pre-trained model, we are actually creating a new network model with a different shape. I just don’t understand how the weights are initialized then. How did keras map the original weights of the pre-trained model to the weights of the new model which have a different shape?
Thanks,
You’re creating a new Model object, but internally the CONV filters are the same. As long as the input dimensions are large enough CONV filters don’t care — they’ll apply the filters to the input just fine 🙂
Thanks Adrian!
Makes sense. The feature maps have different shapes but the filters are the same. I don’t know how I missed that. Thanks Again.
Hello,
Thank you for guiding nicely.
Problem: When I change the input tensor shape before performing fine tuning, few final layers don’t show up with model summary (the dense layers are removed and final layer is max pooling). Why are final layers removed when input shape of image is changed? What is the solution for this?
Please guide me on this. Thank you!
It sounds like you:
1. Loaded your model without the FC head
2. Did not add a new FC head (assuming you are applying fine-tuning)
You should go back and double-check your code.
Hi Adrian,
Nice tutorial.
Can you explain in little more detail how keras handle this input shape change?
For VGG16 the original input is 224×224 so all the kernels size(and hence the weights) will be different as compared to when we change the input to let’s say 128×128.
How these kernels size(and hence the weights) are managed inside the entire networkswhen we load it with different image sizes but with imagenet weights?
Thanks,
Ankit
No, the kernels and weights will not be different. They will have the same dimensions and the same values. The kernels don’t care how large/small the input image is, the convolution will be applied just to same provided that:
1. The image + network can fit into memory
2. The image isn’t so small that there isn’t enough data for the convolution to happen, resulting in an error.
Hi everyone,
thanks Adrian for this amazing post.
I’ve been searching how to train a network with 2D images of variable size, but I couldn’t find a material well explained as you usually do in your posts.
In particular, my network is a U-Net that has conv2D(), maxpooling2D() operation. And when I use Input((None, None, 1)) some of these operation can’t calculate the tensor shape, so I get some errors.
Would you like to make a post with this subject?
Everybody help is welcome also. Thanks in advance.
Hey Adrian,
thanks for the great tutorial – as always 🙂
I have one question though:
How does one find out the image size a model was originally trained with?
1. Take a look at the original input shape of the model.
2. Refer to the documentation associated with the model.
3. Read the academic paper associated with the model.
Thanks for the post, this is extremely useful. However, in case we have input images of very large size, say 4000 * 4000, can we have few pooling layers BEFORE the input layer, so as to read the 4000 * 4000 images and bring it down to 224 * 224 * 3 matrix, which can then be fed as input to the pre-trained model?
No, the input layer must always be the first layer to the network. It’s impossible to have any layers prior to the input layer (the input has to come from somewhere).
Thank you for the post. very interesting. I have one question, I have the input image with size 48 * 48 * 1 matrix, if it is good to use VGG16?
That question can easily be tested by running the example in this blog post. I suggest you learn by doing. Download the code, roll up your sleeves, and run some experiments. The best way to learn is to learn by doing.
is resizing the image necessary or will keras automatically resize the image to the fixed size of the input shape
Keras will not resize the image for you. You need to resize the image or use an ImageDataGenerator to do it for you.