
In today’s blog post, I interview Dr. Paul Lee, a PyImageSearch reader and interventional cardiologist affiliated with NY Mount Sinai School of Medicine.
Dr. Lee recently presented his research at the prestigious American Heart Association Scientific Session in Philadelphia, PA where he demonstrated how Convolutional Neural Networks can:
- Automatically analyze and interpret coronary angiograms
- Detect blockages in patient arteries
- And ultimately help reduce and prevent heart attacks
Furthermore, Dr. Lee has demonstrated that the automatic angiogram analysis can be deployed to a smartphone, making it easier than ever for doctors and technicians to analyze, interpret, and understand heart attack risk factors.
Dr. Lee’s work is truly remarkable and paves the way for Computer Vision and Deep Learning algorithms to help reduce and prevent heart attacks.
Let’s give a warm welcome to Dr. Lee as he shares his research.
An interview with Paul Lee – Doctor, Cardiologist and Deep Learning Researcher
Adrian: Hi Paul! Thank you for doing this interview. It’s a pleasure to have you on the PyImageSearch blog.
Paul: Thank you for inviting me.

Adrian: Tell us a bit about yourself — where do you work and what is your job?
Paul: I am an interventional cardiologist affiliated with NY Mount Sinai School of Medicine. I have a private practice in Brooklyn.

Adrian: How did you first become interested in computer vision and deep learning?
Paul: In a New Yorker magazine’s 2017 article titled A.I. Versus M.D. What happens when diagnosis is automated?, George Hinton commented that “they should stop training radiologists now”. I realized that one day AI will replace me. I wanted to be the person controlling the AI, not the one being replaced.
Adrian: You recently presented your work automatic cardiac coronary angiogram analysis at the American Heart association. Can you tell us about it?
Paul: After starting your course two years ago, I became comfortable with computer vision technique. I decided to apply what you taught to cardiology.
As a cardiologist, I perform coronary angiography to diagnose whether my patients have blockages in their arteries in the heart that can cause heart attack. I wondered whether I can apply AI to interpret coronary angiograms.
Despite many difficulties, thanks to your ongoing support, the neural networks learned to interpret these images reliably.
I was invited to present my research at American Heart Association Scientific Session in Philadelphia this year. This is the most important research conference for cardiologists. My poster is titled Convolutional Neural Networks for Interpretation of Coronary Angiography (CathNet).
(Circulation. 2019;140:A12950; https://ahajournals.org/doi/10.1161/circ.140.suppl_1.12950) ; the poster is available here: https://github.com/AICardiologist/Poster-for-AHA-2019)
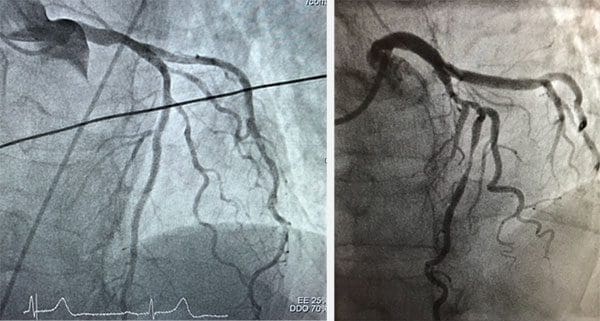
Adrian: Can you tell us a bit more about cardiac coronary angiograms? How are these images captured and how can computer vision/deep learning algorithms better/more efficiently analyze these images (as compared to humans)?
Paul: For definitive diagnosis and treatment of coronary artery disease (for example, during heart attack), cardiologists perform coronary angiogram to determine the anatomy and the extent of the stenosis. During the procedure, cardiologists put a narrow catheter from the wrist or the leg. Through the catheter, we inject contrast into the coronary arteries and the images are captured by X-ray. However, the interpretation of the angiogram is sometimes difficult: computer vision has the potential to make these determinations more objective and accurate.
Figure 3 (left) shows a normal coronary angiogram while Figure 3 (right) shows a stenotic coronary artery.
Adrian: What was the most difficult aspect of your research and why?
Paul: I only had around 5000 images.
At first, we did not know why we had so much trouble getting high accuracy. We thought our images were not preprocessed properly, or some of the images were blurry.
Later, we realized there was nothing wrong with our images: the problem was that ConvNets require lots of data to learn something simple to our human eyes.
Determining whether there is a stenosis in a coronary arterial tree in an image is computationally complex. Since sample size depends on classification complexity, we struggled. We had to find a way to train ConvNets with very limited samples.
Adrian: How long did it take for you to train your models and perform your research?
Paul: It took more than one year. Half the time was spent on gathering and preprocessing data, half the time on training and tuning the model. I would gather data, train and tune my models, gather more data or process the data differently, and improve my previous models, and keep repeating this circle.
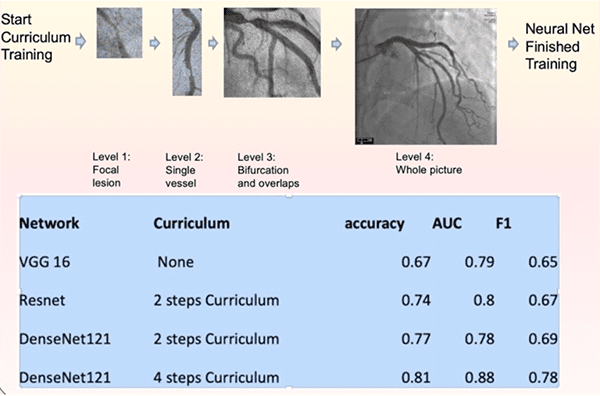
Adrian: If you had to pick the most important technique you applied during your research, what would it be?
Paul: I scoured PyImageSearch for technical tips to train ConvNets with small sample number of samples: transfer learning, image augmentation, using SGD instead of Adam, learning rate schedule, early stopping.
Every technique contributes to small improvement in F1 score, but I only reached about 65% accuracy.
I looked at Kaggle contest solutions to look for technical tips. The biggest breakthrough was from a technique called “curriculum learning.” I first trained DenseNet to interpret something very simple: “is there a narrowing in that short straight segment of artery?” That only took around a hundred sample.
Then I trained this pre-trained network with longer segments of arteries with more branches. The curriculum gradually build complexity until it learns to interpret the stenosis in the context of complicated figures. This approach dramatically improved our test accuracy to 82%. Perhaps the pre-training steps reduced computational complexity by priming information into the neural network.
“Curriculum learning” in the literature actually means something different: it generally refers to splitting their training samples based on error rates, and then sequencing the training data batches based on increasing error rate. In contrast, I actually created learning materials for the ConvNet to learn, not just re-arrange the batches based on error rate. I got this idea from my experience of learning foreign language, not from the computer literature. At the beginning, I struggled to understand newspaper articles written in Japanese. As I progressed through beginner, then to intermediate, and finally to advanced level Japanese curriculum, I could finally understand these articles.

Adrian: What are your computer vision and deep learning tools, libraries, and packages of choice?
Paul: I am using standard packages: Keras, Tensorflow, OpenCV 4.
I use Photoshop to cleanup the images and to create curriculums.
Initially I was using cloud instances [for training], but I found that my RTX 2080 Ti x 4 Workstation is much more cost effective. The “global warming” from the GPUs killed my wife’s plants, but it dramatically speeded up model iteration.
We converted our Tensorflow models into an iPhone app using Core ML just like what you did for your Pokemon identification app.
Our demonstration video for our app is here:
Adrian: What advice would you give to someone who wants to perform computer vision/deep learning research but doesn’t know how to get started?
Paul: When I first started two years ago, I did not even know Python. After completing a beginner Python course, I jumped into Andrew Ng’s deep learning course. Because I needed more training, I began PyImageSearch guru course. The materials from Stanford CS231n are great for surveying the “big picture” but PyImageSearch course materials are immediately actionable for someone like me without computer science background.
Adrian: How did the PyImageSearch Gurus course and Deep Learning for Computer Vision with Python book prepare you for your research?
Paul: PyImageSearch course and books armed me with OpenCV and TensorFlow skills. I continuously return to the materials for technical tips and updates. Your advice really motivated me to push forward despite obstacles.
Adrian: Would you recommend the PyImageSearch Gurus course or Deep Learning for Computer Vision with Python to other budding researchers, students, or developers trying to learn computer vision + deep learning?
Paul: Without reservation. The course converted me from a Python beginner to a published computer vision practitioner. If you are looking for the most cost- and time-efficient way to learn Computer Vision, and if you are really serious, I wholeheartedly recommend PyImageSearch courses.
Adrian: What’s next for your research?
Paul: My next project is to bring computer vision to the bedside. Currently, clinicians are spending too much time on their desktop computer during office visit and hospital rounds. I hope our project will empower clinicians to do what they do best: spending time at the bedside caring for patients.
Adrian: If a PyImageSearch reader wants to chat about your work and research, what is the best place to connect with you?
Paul: I can be reached at my LinkedIn account and I look forward to hearing from your readers.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post, we interviewed Dr. Paul Lee (MD), an interventional cardiologist and Computer Vision/Deep Learning practitioner.
Dr. Lee recently presented a poster at the prestigious American Heart Association Scientific Session in Philadelphia, PA where he demonstrated how Convolutional Neural Networks can:
- Automatically analyze and interpret coronary angiograms
- Detect blockages in patient arteries
- Help reduce and prevent heart attacks
The primary motivation for Dr. Lee’s work was that he understood that one day radiologists would one day be replaceable by Artificial Intelligence.
Instead of simply accepting that fate, Dr. Lee decided to take matters in his own hands — he strove to be the person building that AI, not the one being replaced by it.
Dr. Lee not only achieved his goal, but was able to publish his work at a distinguished conference, proof that dedication, a strong will, and the proper education is all you need to be successful in Computer Vision and Deep Learning.
If you want to follow in Dr. Lee’s footsteps, be sure to pick up a copy of Deep Learning for Computer Vision with Python (DL4CV) and join the PyImageSearch Gurus course.
Using these resources you can:
I hope you’ll join myself, Dr. Lee, and thousands of other PyImageSearch readers who have not only mastered computer vision and deep learning, but have taken that knowledge and used it to change their lives.
I’ll see you on the other side.
To be notified when future blog posts and interviews are published here on PyImageSearch, just be sure to enter your email address in the form below, and I’ll be sure to keep you in the loop.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

