
In this tutorial you will learn how to use dlib’s find_min_global function to optimize the options and hyperparameters to dlib’s shape predictor, yielding a more accurate model.
A few weeks ago I published a two-part series on using dlib to train custom shape predictors:
- Part one: Training a custom dlib shape predictor
- Part two: Tuning dlib shape predictor hyperparameters to balance speed, accuracy, and model size
When I announced the first post on social media, Davis King, the creator of dlib, chimed in and suggested that I demonstrate how to use dlib’s find_min_global function to optimize the shape predictor hyperparameters:
find_min_global.I loved the idea and immediately began writing code and gathering results.
Today I’m pleased to share the bonus guide on training dlib shape predictors and optimizing their hyperparameters.
I hope you enjoy it!
To learn how to use dlib’s find_min_global function to optimize shape predictor hyperparameters, just keep reading!
Optimizing dlib shape predictor accuracy with find_min_global
In the first part of this tutorial, we’ll discuss dlib’s find_min_global function and how it can be used to optimize the options/hyperparameters to a shape predictor.
We’ll also compare and contrast find_min_global to a standard grid search.
Next, we’ll discuss the dataset we’ll be using for this tutorial, including reviewing our directory structure for the project.
We’ll then open up our code editor and get our hands dirty by implementing three Python scripts including:
- A configuration file.
- A script used to optimize hyperparameters via
find_min_global. - A script used to take the best hyperparameters found via
find_min_globaland then train an optimal shape predictor using these values.
We’ll wrap up the post with a short discussion on when you should be using find_min_global versus performing a standard grid hyperparameter search.
Let’s get started!
What does dlib’s find_min_global function do? And how can we use it to tune shape predictor options?

Video Source: A Global Optimization Algorithm Worth Using by Davis King
A few weeks ago you learned how to tune dlib’s shape predictor options using a systematic grid search.
That method worked well enough, but the problem is a grid search isn’t a true optimizer!
Instead, we hardcoded hyperparameter values we want to explore, the grid search computes all possible combinations of these values, and then explores them one-by-one.
Grid searches are computationally wasteful as the algorithm spends precious time and CPU cycles exploring hyperparameter combinations that will never yield the best possible results.
Wouldn’t it be more advantageous if we could instead iteratively tune our options, ensuring that with each iteration we are incrementally improving our model?
In fact, that’s exactly what dlib find_min_global function does!
Davis King, the creator of the dlib library, documented his struggle with hyperparameter tuning algorithms, including:
- Guess and check: An expert uses his gut instinct and previous experience to manually set hyperparameters, run the algorithm, inspect the results, and then use the results to make an educated guess as to what the next set of hyperparameters to explore will be.
- Grid search: Hardcode all possible hyperparameter values you want to test, compute all possible combinations of these hyperparameters, and then let the computer test them all, one-by-one.
- Random search: Hardcode upper and lower limits/ranges on the hyperparamters you want to explore and then allow the computer to randomly sample the hyperparameter values within those ranges.
- Bayesian optimization: A global optimization strategy for black-box algorithms. This method often has more hyperparameters to tune than the original algorithm itself. Comparatively, you are better off using a “guess and check” strategy or throwing hardware at the problem via grid searching or random searching.
- Local optimization with a good initial guess: This method is good, but is limited to finding local optima with no guarantee it will find the global optima.
Eventually, Davis came across Malherbe and Vayatis’s 2017 paper, Global optimization of Lipschitz functions, which he then implemented into the dlib library via the find_min_global function.
Unlike Bayesian methods, which are near impossible to tune, and local optimization methods, which place no guarantees on a globally optimal solution, the Malherbe and Vayatis method is parameter-free and provably correct for finding a set of values that maximizes/minimizes a particular function.
Davis has written extensively on the optimization method in the following blog post — I suggest you give it a read if you are interested in the mathematics behind the optimization method.
The iBUG-300W dataset

find_min_global optimization method, we will optimize an eyes-only shape predictor.To find the optimal dlib shape predictor hyperparameters, we’ll be using the iBUG 300-W dataset, the same dataset we used for previous our two-part series on shape predictors.
The iBUG 300-W dataset is perfect for training facial landmark predictors to localize the individual structures of the face, including:
- Eyebrows
- Eyes
- Nose
- Mouth
- Jawline
Shape predictor data files can become quite large. To combat this, we’ll be training our shape predictor to localize only the eyes rather than all face landmarks. You could just as easily train a shape predictor to recognize only the mouth, etc.
Configuring your dlib development environment
To follow along with today’s tutorial, you will need a virtual environment with the following packages installed:
- dlib
- OpenCV
- imutils
- scikit-learn
Luckily, each of these packages is pip-installable. That said, there are a handful of prerequisites (including Python virtual environments). Be sure to follow these two guides for additional information in configuring your development environment:
The pip install commands include:
$ workon <env-name> $ pip install dlib $ pip install opencv-contrib-python $ pip install imutils $ pip install scikit-learn
The workon command becomes available once you install virtualenv and virtualenvwrapper per either my dlib or OpenCV installation guides.
Downloading the iBUG-300W dataset
To follow along with this tutorial, you will need to download the iBUG 300-W dataset (~1.7GB):
http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
While the dataset is downloading, you should also use the “Downloads” section of this tutorial to download the source code.
You can either (1) use the hyperlink above, or (2) use wget to download the dataset. Let’s cover both methods so that your project is organized just like my own.
Option 1: Use the hyperlink above to download the dataset and then place the iBug 300-W dataset into the folder associated with the download of this tutorial like this:
$ unzip tune-dlib-shape-predictor.zip ... $ cd tune-dlib-shape-predictor $ mv ~/Downloads/ibug_300W_large_face_landmark_dataset.tar.gz . $ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz ...
Option 2: Rather than clicking the hyperlink above, use wget in your terminal to download the dataset directly:
$ unzip tune-dlib-shape-predictor.zip ... $ cd tune-dlib-shape-predictor $ wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz $ tar -xvf ibug_300W_large_face_landmark_dataset.tar.gz ...
You’re now ready to follow along with the rest of the tutorial.
Project structure
Be sure to follow the previous section to both (1) download today’s .zip from the “Downloads” section, and (2) download the iBug 300-W dataset into today’s project.
From there, go ahead and execute the tree command to see our project structure:
% tree --dirsfirst --filelimit 10 . ├── ibug_300W_large_face_landmark_dataset │ ├── afw [1011 entries] │ ├── helen │ │ ├── testset [990 entries] │ │ └── trainset [6000 entries] │ ├── ibug [405 entries] │ ├── lfpw │ │ ├── testset [672 entries] │ │ └── trainset [2433 entries] │ ├── image_metadata_stylesheet.xsl │ ├── labels_ibug_300W.xml │ ├── labels_ibug_300W_test.xml │ └── labels_ibug_300W_train.xml ├── pyimagesearch │ ├── __init__.py │ └── config.py ├── best_predictor.dat ├── ibug_300W_large_face_landmark_dataset.tar.gz ├── parse_xml.py ├── predict_eyes.py ├── shape_predictor_tuner.py └── train_best_predictor.py 10 directories, 11 files
As you can see, our dataset has been extracted into the ibug_300W_large_face_landmark_dataset/ directory following the instructions in the previous section.
Our configuration is housed in the pyimagesearch module.
Our Python scripts consist of:
parse_xml.py: First, you need to prepare and extract eyes-only landmarks from the iBug 300-W dataset, resulting in smaller XML files. We’ll review how to use the script in the next section, but we won’t review the script itself as it was covered in a previous tutorial.shape_predictor_tuner.py: This script takes advantage of dlib’sfind_min_globalmethod to find the best shape predictor. We will review this script in detail today. This script will take significant time to execute (multiple days).train_best_predictor.py: After the shape predictor is tuned, we’ll update our shape predictor options and start the training process.predict_eys.py: Loads the serialized model, finds landmarks, and annotates them on a real-time video stream. We won’t cover this script today as we have covered it previously.
Let’s get started!
Preparing the iBUG-300W dataset

find_min_global.As previously mentioned in the “The iBUG-300W dataset” section above, we will be training our dlib shape predictor on solely the eyes (i.e., not the eyebrows, nose, mouth or jawline).
In order to do so, we’ll first parse out any facial structures we are not interested in from the iBUG 300-W training/testing XML files.
At this point, ensure that you have:
- Used the “Downloads” section of this tutorial to download the source code.
- Used the “Downloading the iBUG-300W dataset” section above to download the iBUG-300W dataset.
- Reviewed the “Project structure” section so that you are familiar with the files and folders.
Inside your directory structure there is a script named parse_xml.py — this script handles parsing out just the eye locations from the XML files.
We reviewed this file in detail in my previous Training a Custom dlib Shape Predictor tutorial. We will not review the file again, so be sure to review it in the first tutorial of this series.
Before you continue on with the rest of this tutorial you’ll need to execute the following command to prepare our “eyes only” training and testing XML files:
$ python parse_xml.py \ --input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml \ --output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train_eyes.xml [INFO] parsing data split XML file... $ python parse_xml.py \ --input ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test.xml \ --output ibug_300W_large_face_landmark_dataset/labels_ibug_300W_test_eyes.xml [INFO] parsing data split XML file...
Now let’s verify that the training/testing files have been created. You should check your iBUG-300W root dataset directory for the labels_ibug_300W_train_eyes.xml and labels_ibug_300W_test_eyes.xml files as shown:
$ cd ibug_300W_large_face_landmark_dataset $ ls -lh *.xml -rw-r--r--@ 1 adrian staff 21M Aug 16 2014 labels_ibug_300W.xml -rw-r--r--@ 1 adrian staff 2.8M Aug 16 2014 labels_ibug_300W_test.xml -rw-r--r-- 1 adrian staff 602K Dec 12 12:54 labels_ibug_300W_test_eyes.xml -rw-r--r--@ 1 adrian staff 18M Aug 16 2014 labels_ibug_300W_train.xml -rw-r--r-- 1 adrian staff 3.9M Dec 12 12:54 labels_ibug_300W_train_eyes.xml $ cd ..
Notice that our *_eyes.xml files are highlighted. These files are significantly smaller in filesize than their original, non-parsed counterparts.
Our configuration file
Before we can use find_min_global to tune our hyperparameters, we first need to create a configuration file that will store all our important variables, ensuring we can use them and access them across multiple Python scripts.
Open up the config.py file in your pyimagesearch module (following the project structure above) and insert the following code:
# import the necessary packages
import os
# define the path to the training and testing XML files
TRAIN_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_train_eyes.xml")
TEST_PATH = os.path.join("ibug_300W_large_face_landmark_dataset",
"labels_ibug_300W_test_eyes.xml")
The os module (Line 2) allows our configuration script to join filepaths.
Lines 5-8 join our training and testing XML landmark files.
Let’s define our training parameters:
# define the path to the temporary model file TEMP_MODEL_PATH = "temp.dat" # define the number of threads/cores we'll be using when trianing our # shape predictor models PROCS = -1 # define the maximum number of trials we'll be performing when tuning # our shape predictor hyperparameters MAX_FUNC_CALLS = 100
Here you will find:
- The path to the temporary model file (Line 11).
- The number of threads/cores to use when training (Line 15). A value of
-1indicates that all processor cores on your machine will be utilized. - The maximum number of function calls that
find_min_globalwill use when attempting to optimize our hyperparameters (Line 19). Smaller values will enable our tuning script to complete faster, but could lead to hyperparameters that are “less optimal”. Larger values will take the tuning script significantly longer to run, but could lead to hyperparameters that are “more optimal”.
Implementing the dlib shape predictor and find_min_global training script
Now that we’ve reviewed our configuration file, we can move on to tuning our shape predictor hyperparameters using find_min_global.
Open up the shape_predictor_tuner.py file in your project structure and insert the following code:
# import the necessary packages from pyimagesearch import config from collections import OrderedDict import multiprocessing import dlib import sys import os # determine the number of processes/threads to use procs = multiprocessing.cpu_count() procs = config.PROCS if config.PROCS > 0 else procs
Lines 2-7 import our necessary packages, namely our config and dlib . We will use the multiprocessing module to grab the number of CPUs/cores our system has (Lines 10 and 11). An OrderedDict will contain all of our dlib shape predictor options.
Now let’s define a function responsible for the heart of shape predictor tuning with dlib:
def test_shape_predictor_params(treeDepth, nu, cascadeDepth, featurePoolSize, numTestSplits, oversamplingAmount, oversamplingTransJitter, padding, lambdaParam): # grab the default options for dlib's shape predictor and then # set the values based on our current hyperparameter values, # casting to ints when appropriate options = dlib.shape_predictor_training_options() options.tree_depth = int(treeDepth) options.nu = nu options.cascade_depth = int(cascadeDepth) options.feature_pool_size = int(featurePoolSize) options.num_test_splits = int(numTestSplits) options.oversampling_amount = int(oversamplingAmount) options.oversampling_translation_jitter = oversamplingTransJitter options.feature_pool_region_padding = padding options.lambda_param = lambdaParam # tell dlib to be verbose when training and utilize our supplied # number of threads when training options.be_verbose = True options.num_threads = procs
The test_shape_predictor_params function:
- Accepts an input set of hyperparameters.
- Trains a dlib shape predictor using those hyperparameters.
- Computes the predictor loss/error on our testing set.
- Returns the error to the
find_min_globalfunction. - The
find_min_globalfunction will then take the returned error and use it to adjust the optimal hyperparameters found thus far in an iterative fashion.
As you can see, the test_shape_predictor_params function accepts nine parameters, each of which are dlib shape predictor hyperparameters that we’ll be optimizing.
Lines 19-28 set the hyperparameter values from the parameters (casting to integers when appropriate).
Lines 32 and 33 instruct dlib to be verbose with output and to utilize the supplied number of threads/processes for training.
Let’s finish coding the test_shape_predictor_params function:
# display the current set of options to our terminal
print("[INFO] starting training...")
print(options)
sys.stdout.flush()
# train the model using the current set of hyperparameters
dlib.train_shape_predictor(config.TRAIN_PATH,
config.TEMP_MODEL_PATH, options)
# take the newly trained shape predictor model and evaluate it on
# both our training and testing set
trainingError = dlib.test_shape_predictor(config.TRAIN_PATH,
config.TEMP_MODEL_PATH)
testingError = dlib.test_shape_predictor(config.TEST_PATH,
config.TEMP_MODEL_PATH)
# display the training and testing errors for the current trial
print("[INFO] train error: {}".format(trainingError))
print("[INFO] test error: {}".format(testingError))
sys.stdout.flush()
# return the error on the testing set
return testingError
Lines 41 and 42 train the dlib shape predictor using the current set of hyperparameters.
From there, Lines 46-49 evaluate the newly trained shape predictor on training and testing set.
Lines 52-54 print training and testing errors for the current trial before Line 57 returns the testingError to the calling function.
Let’s define our set of shape predictor hyperparameters:
# define the hyperparameters to dlib's shape predictor that we are
# going to explore/tune where the key to the dictionary is the
# hyperparameter name and the value is a 3-tuple consisting of the
# lower range, upper range, and is/is not integer boolean,
# respectively
params = OrderedDict([
("tree_depth", (2, 5, True)),
("nu", (0.001, 0.2, False)),
("cascade_depth", (4, 25, True)),
("feature_pool_size", (100, 1000, True)),
("num_test_splits", (20, 300, True)),
("oversampling_amount", (1, 40, True)),
("oversampling_translation_jitter", (0.0, 0.3, False)),
("feature_pool_region_padding", (-0.2, 0.2, False)),
("lambda_param", (0.01, 0.99, False))
])
Each value in the OrderedDict is a 3-tuple consisting of:
- The lower bound on the hyperparameter value.
- The upper bound on the hyperparameter value.
- A boolean indicating whether the hyperparameter is an integer or not.
For a full review of the hyperparameters, be sure to refer to my previous post.
From here, we’ll extract our upper and lower bounds as well as whether a hyperparameter is an integer:
# use our ordered dictionary to easily extract the lower and upper # boundaries of the hyperparamter range, include whether or not the # parameter is an integer or not lower = [v[0] for (k, v) in params.items()] upper = [v[1] for (k, v) in params.items()] isint = [v[2] for (k, v) in params.items()]
Lines 79-81 extract the lower , upper , and isint boolean from our params dictionary.
Now that we have the setup taken care of, let’s optimize our shape predictor hyperparameters using dlib’s find_min_global method:
# utilize dlib to optimize our shape predictor hyperparameters
(bestParams, bestLoss) = dlib.find_min_global(
test_shape_predictor_params,
bound1=lower,
bound2=upper,
is_integer_variable=isint,
num_function_calls=config.MAX_FUNC_CALLS)
# display the optimal hyperparameters so we can reuse them in our
# training script
print("[INFO] optimal parameters: {}".format(bestParams))
print("[INFO] optimal error: {}".format(bestLoss))
# delete the temporary model file
os.remove(config.TEMP_MODEL_PATH)
Lines 84-89 start the optimization process.
Lines 93 and 94 display the optimal parameters before Line 97 deletes the temporary model file.
Tuning shape predictor options with find_min_global
To use find_min_global to tune the hyperparameters to our dlib shape predictor, make sure you have:
- Used the “Downloads” section of this tutorial to download the source code.
- Downloaded the iBUG-300W dataset using the “Downloading the iBUG-300W dataset” section above.
- Executed the
parse_xml.pyfor both the training and testing XML files in the “Preparing the iBUG-300W dataset” section.
Provided you have accomplished each of these three steps, you can now execute the shape_predictor_tune.py script:
$ time python shape_predictor_tune.py [INFO] starting training... shape_predictor_training_options(be_verbose=1, cascade_depth=15, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1005, oversampling_amount=21, oversampling_translation_jitter=0.15, feature_pool_size=550, lambda_param=0.5, num_test_splits=160, feature_pool_region_padding=0, random_seed=, num_threads=20, landmark_relative_padding_mode=1) Training with cascade depth: 15 Training with tree depth: 4 Training with 500 trees per cascade level. Training with nu: 0.1005 Training with random seed: Training with oversampling amount: 21 Training with oversampling translation jitter: 0.15 Training with landmark_relative_padding_mode: 1 Training with feature pool size: 550 Training with feature pool region padding: 0 Training with 20 threads. Training with lambda_param: 0.5 Training with 160 split tests. Fitting trees... Training complete Training complete, saved predictor to file temp.dat [INFO] train error: 5.518466441668642 [INFO] test error: 6.977162396336371 [INFO] optimal inputs: [4.0, 0.1005, 15.0, 550.0, 160.0, 21.0, 0.15, 0.0, 0.5] [INFO] optimal output: 6.977162396336371 ... [INFO] starting training... shape_predictor_training_options(be_verbose=1, cascade_depth=20, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1033, oversampling_amount=29, oversampling_translation_jitter=0, feature_pool_size=677, lambda_param=0.0250546, num_test_splits=295, feature_pool_region_padding=0.0974774, random_seed=, num_threads=20, landmark_relative_padding_mode=1) Training with cascade depth: 20 Training with tree depth: 4 Training with 500 trees per cascade level. Training with nu: 0.1033 Training with random seed: Training with oversampling amount: 29 Training with oversampling translation jitter: 0 Training with landmark_relative_padding_mode: 1 Training with feature pool size: 677 Training with feature pool region padding: 0.0974774 Training with 20 threads. Training with lambda_param: 0.0250546 Training with 295 split tests. Fitting trees... Training complete Training complete, saved predictor to file temp.dat [INFO] train error: 2.1037606164427904 [INFO] test error: 4.225682000183475 [INFO] optimal parameters: [4.0, 0.10329967171060293, 20.0, 677.0, 295.0, 29.0, 0.0, 0.09747738830224817, 0.025054553453757795] [INFO] optimal error: 4.225682000183475 real 8047m24.389s user 98916m15.646s sys 464m33.139s
On my iMac Pro with a 3 GHz Intel Xeon W processor with 20 cores, running a total of 100 MAX_TRIALS took ~8047m24s, or ~5.6 days. If you don’t have a powerful computer, I would recommend running this procedure on a powerful cloud instance.
Looking at the output you can see that the find_min_global function found the following optimal shape predictor hyperparameters:
tree_depth: 4nu: 0.1033cascade_depth: 20feature_pool_size: 677num_test_splits: 295oversampling_amount: 29oversampling_translation_jitter: 0feature_pool_region_padding: 0.0975lambda_param: 0.0251
In the next section we’ll take these values and update our train_best_predictor.py script to include them.
Updating our shape predictor options using the results from find_min_global
At this point we know the best possible shape predictor hyperparameter values, but we still need to train our final shape predictor using these values.
To do make, open up the train_best_predictor.py file and insert the following code:
# import the necessary packages
from pyimagesearch import config
import multiprocessing
import argparse
import dlib
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path serialized dlib shape predictor model")
args = vars(ap.parse_args())
# determine the number of processes/threads to use
procs = multiprocessing.cpu_count()
procs = config.PROCS if config.PROCS > 0 else procs
# grab the default options for dlib's shape predictor
print("[INFO] setting shape predictor options...")
options = dlib.shape_predictor_training_options()
# update our hyperparameters
options.tree_depth = 4
options.nu = 0.1033
options.cascade_depth = 20
options.feature_pool_size = 677
options.num_test_splits = 295
options.oversampling_amount = 29
options.oversampling_translation_jitter = 0
options.feature_pool_region_padding = 0.0975
options.lambda_param = 0.0251
# tell the dlib shape predictor to be verbose and print out status
# messages our model trains
options.be_verbose = True
# number of threads/CPU cores to be used when training -- we default
# this value to the number of available cores on the system, but you
# can supply an integer value here if you would like
options.num_threads = procs
# log our training options to the terminal
print("[INFO] shape predictor options:")
print(options)
# train the shape predictor
print("[INFO] training shape predictor...")
dlib.train_shape_predictor(config.TRAIN_PATH, args["model"], options)
Lines 2-5 import our config , multiprocessing , argparse , and dlib .
From there, we set the shape predictor options (Lines 14-39) using the optimal values we found from the previous section.
And finally, Line 47 trains and exports the model.
For a more detailed review of this script, be sure to refer to my previous tutorial.
Training the final shape predictor
The final step is to execute our train_best_predictor.py file which will train a dlib shape predictor using our best hyperparameter values found via find_min_global:
$ time python train_best_predictor.py --model best_predictor.dat [INFO] setting shape predictor options... [INFO] shape predictor options: shape_predictor_training_options(be_verbose=1, cascade_depth=20, tree_depth=4, num_trees_per_cascade_level=500, nu=0.1033, oversampling_amount=29, oversampling_translation_jitter=0, feature_pool_size=677, lambda_param=0.0251, num_test_splits=295, feature_pool_region_padding=0.0975, random_seed=, num_threads=20, landmark_relative_padding_mode=1) [INFO] training shape predictor... Training with cascade depth: 20 Training with tree depth: 4 Training with 500 trees per cascade level. Training with nu: 0.1033 Training with random seed: Training with oversampling amount: 29 Training with oversampling translation jitter: 0 Training with landmark_relative_padding_mode: 1 Training with feature pool size: 677 Training with feature pool region padding: 0.0975 Training with 20 threads. Training with lambda_param: 0.0251 Training with 295 split tests. Fitting trees... Training complete Training complete, saved predictor to file best_predictor.dat real 111m46.444s user 1492m29.777s sys 5m39.150s
After the command finishes executing you should have a file named best_predictor.dat in your local directory structure:
$ ls -lh *.dat -rw-r--r--@ 1 adrian staff 24M Dec 22 12:02 best_predictor.dat
You can then take this predictor and use it to localize eyes in real-time video using the predict_eyes.py script:
$ python predict_eyes.py --shape-predictor best_predictor.dat [INFO] loading facial landmark predictor... [INFO] camera sensor warming up...
When should I use dlib’s find_min_global function?
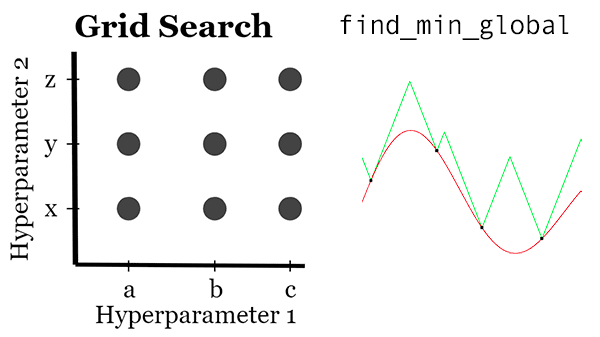
find_min_global method to optimize a custom dlib shape predictor can take significant processing time. Be sure to review this section for general rules of thumb including guidance on when to use a Grid Search method to find a shape predictor model.Unlike a standard grid search for tuning hyperparameters, which blindly explores sets of hyperparameters, the find_min_global function is a true optimizer, enabling it to iteratively explore the hyperparameter space, choosing options that maximize our accuracy and minimize our loss/error.
However, one of the downsides of find_min_global is that it cannot be made parallel in an easy fashion.
A standard grid search, on the other hand, can be made parallel by:
- Dividing all combinations of hyperparameters into N size chunks
- And then distributing each of the chunks across M systems
Doing so would lead to faster hyperparameter space exploration than using find_min_global.
The downside is that you may not have the “true” best choices of hyperparameters since a grid search can only explore values that you have hardcoded.
Therefore, I recommend the following rule of thumb:
If you have multiple machines, use a standard grid search and distribute the work across the machines. After the grid search completes, take the best values found and then use them as inputs to dlib’s find_min_global to find your best hyperparameters.
If you have a single machine use dlib’s find_min_global, making sure to trim down the ranges of hyperparameters you want to explore. For instance, if you know you want a small, fast model, you should cap the upper range limit of tree_depth, preventing your ERTs from becoming too deep (and therefore slower).
While dlib’s find_min_global function is quite powerful, it can also be slow, so make sure you take care to think ahead and plan out which hyperparameters are truly important for your application.
You should also read my previous tutorial on training a custom dlib shape predictor for a detailed review of what each of the hyperparameters controls and how they can be used to balance speed, accuracy, and model size.
Use these recommendations and you’ll be able to successfully tune and optimize your dlib shape predictors.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial you learned how to use dlib’s find_min_global function to optimize options/hyperparameters when training a custom shape predictor.
The function is incredibly easy to use and makes it dead simple to tune the hyperparameters to your dlib shape predictor.
I would also recommend you use my previous tutorial on tuning dlib shape predictor options via a grid search — combining a grid search (using multiple machines) with find_min_global can lead to a superior shape predictor.
I hope you enjoyed this blog post!
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

mr.adrian cool tutorial as always !!
I just want to say that is this possible to use on any model or is it specific to only shape predictors
Thanks, I’m glad you enjoyed the tutorial.
As for find_min_global, that function will work with ANY model that returns a score that should be minimized (i.e., it’s not limited to just shape predictors).
Was a complete and interesting tutorial. Congratulations!
I’m not sure of what is the basis algorithm, I mean is it similar to active shape models because of the landmarks but not sure. Do you know where can I get the theoretical basis of the this topic?
Refer to this tutorial for more information on the algorithm used.