Revised and updated 4/10/2023

Table of Contents
What Is Deep Learning?
It’s a fine Friday. You have just returned home from work and are choosing to relax by watching an Arnold Schwarzenegger Classic, The Terminator, a movie about sentient Artificial Intelligence (AI) that will take over the world soon.

While it remains a true classic, this makes you wonder if AI’s ever-growing evolution will lead to a frightening future like that. Can AI truly reach a state where it learns and makes decisions on its own like a human being?
The human brain works in ingenious ways to learn new information. However, machines are electrical boxes that do what they are programmed to do. While you can automate machines to do many tasks, they won’t “understand” how an image of a dog differs from an image of a cat, as we do.
So this begs the question: How do you “teach” information to a machine?
To answer this question, we turn toward a subset of Artificial Intelligence: Deep Learning.
There is no doubt that the importance of AI in today’s technological sphere is undeniable and unparalleled. With the advent of deep learning (DL), a subfield of AI, machines can now learn and improve on their own through experience. This has paved the way for groundbreaking innovations in various industries (e.g., healthcare, finance, and transportation).
Deep learning has also led to the development of intelligent virtual assistants, facial recognition technology, and even self-driving cars. In this blog post, we will explore the concept of DL, how it works, and its real-world applications.
This tutorial will provide a brief overview of deep learning.
To learn how to start your journey into the world of deep learning, just keep reading.
What Is Deep Learning?
Topic Description
Nowadays, whenever we talk about Deep Learning, the image that comes to mind is a dense connection of stacked nodes (Figure 1).
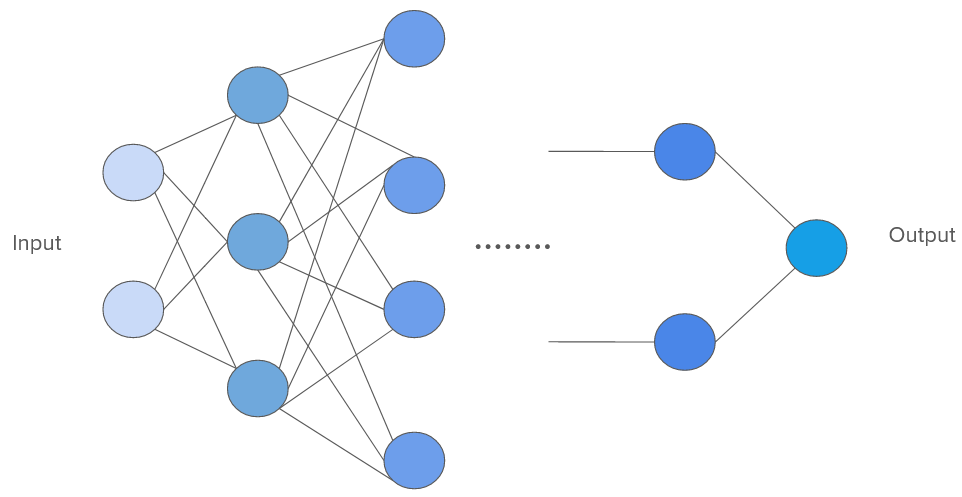
A dense connection of several neurons stacked together is inspired by how the human brain works. Each node embodies a neuron and is connected to all the neurons in the subsequent layer. This signifies how information is shared between the neurons.
But let’s move on to a more formal definition first.
Deep learning is a type of machine learning (ML) that involves training artificial neural networks with large amounts of data to recognize patterns and make predictions or decisions. It is a powerful tool for solving complex problems in various fields, including computer vision, natural language processing, speech recognition, and autonomous vehicles.
For example, deep learning algorithms in healthcare have been used to analyze medical images (e.g., X-rays, CT scans, and MRIs) to help doctors diagnose and treat diseases more accurately and quickly. For example, a DL model can be trained to detect cancerous tumors in medical images with high accuracy, potentially saving lives by catching the disease early.
Another example is in the field of autonomous vehicles. Deep learning algorithms can help self-driving cars navigate complex environments and make decisions based on real-time data from sensors and cameras. By training neural networks with large amounts of data from various driving scenarios, autonomous vehicles can learn to recognize objects (e.g., pedestrians, other cars, and traffic lights) and make decisions on navigating safely.
But before we dive further into the intricacies of DL, we should have a general understanding of what ML is.
A Brief Overview of Machine Learning
Time and time again, we come across this illustration explaining the relationship between Artificial Intelligence, Machine Learning, and Deep Learning (Figure 2).

While AI can be called the study of using machines to mimic human behavior, ML is a subset of AI that involves training algorithms to make predictions or decisions based on input data. The algorithms “learn” from the data, improving accuracy over time without being explicitly programmed.
At its heart, ML is nothing but simple linear algebra and a bit of calculus (Figure 3).

In machine learning, an algorithm is trained on a dataset that consists of input data and corresponding output labels. The algorithm learns to recognize patterns in the data and can then make predictions or decisions on new, unseen data. Machine learning aims to develop models that generalize to recent data and make accurate predictions or decisions.
There are three main types of machine learning:
- supervised learning
- unsupervised learning
- reinforcement learning
The algorithm is trained on labeled data in supervised learning, where the output labels are known. The algorithm learns to map input data to output labels and can then make predictions on new data.
In unsupervised learning, the algorithm is trained on unlabeled data and must find patterns or structures in the data independently. This type of learning is often used for clustering or dimensionality reduction tasks.
In reinforcement learning, the algorithm learns through trial and error by receiving feedback as rewards or penalties for its actions. This type of learning is often used for tasks (e.g., game playing or robotics).
There are innumerable ways in which machine learning has helped progress technology, but we are interested in a specific subset of ML, which is DL. Next, we will review the building block of DL, a simple neural network.
The Basics of Neural Networks
Previously, we looked at the image of densely connected neurons. But what is the magic that happens inside a single neuron?
Let’s take a look at Figure 4.
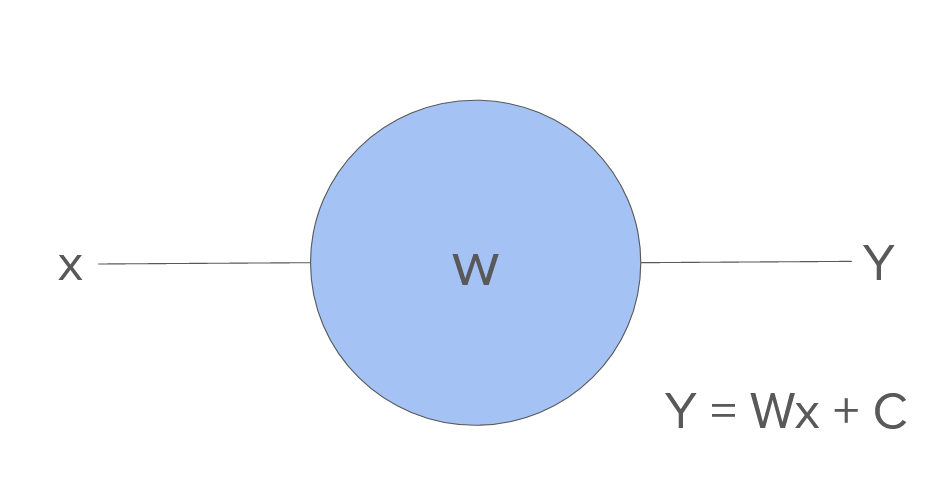
Does this equation seem familiar to you?
This is similar to the straight-line equation,  .
.
 and
and  remain the same in both cases (i.e., the output and the input)
remain the same in both cases (i.e., the output and the input) becomes
becomes  , which is called the weight of the neuron. This value is adjusted each time the neuron network “learns” more.
, which is called the weight of the neuron. This value is adjusted each time the neuron network “learns” more.  becomes , the bias, and serves to offset the result. This is also a trainable parameter, along with the weight.
becomes , the bias, and serves to offset the result. This is also a trainable parameter, along with the weight.
 and
and  remain the same in both cases (i.e., the output and the input)
remain the same in both cases (i.e., the output and the input) becomes
becomes  , which is called the weight of the neuron. This value is adjusted each time the neuron network “learns” more.
, which is called the weight of the neuron. This value is adjusted each time the neuron network “learns” more.  becomes
becomes  , the bias, and serves to offset the result. This is also a trainable parameter, along with the weight.
, the bias, and serves to offset the result. This is also a trainable parameter, along with the weight. Several neurons make up a Neural Network. As your network is exposed to the data, it learns patterns in your data, and the weights of all the neurons get adjusted accordingly. Once the training procedure is complete, a well-trained neural network will have learned the necessary intricacies of the dataset it was trained on.
The vertical stack of neurons you see in Figure 1 is called layers. The term “deep” neural networks comes from when there are several stacks of neurons (called layers) between the input and output. Given an objective function (e.g., predictions of the network being compared to the given data labels), these layers progressively learn more and more about a given data.
We understand the magic behind a neuron, but how do deep neural networks differ from traditional ML algorithms?
Deep Learning vs. Traditional Machine Learning
At its core, both Deep Learning and Traditional Machine Learning are ways to learn the underlying patterns of the data and solve problems.
Traditional machine learning is a subset of AI that builds algorithms to learn from and predict data. These algorithms are typically based on statistical models and can be trained on labeled data, which means already classified or categorized data. Examples of traditional ML algorithms include decision trees, random forests, and support vector machines.
Conversely, deep learning is a subset of machine learning that uses artificial neural networks to learn from and predict data. The structure of the human brain inspires these networks and consists of layers of interconnected nodes that hierarchically process data. Deep learning algorithms can be trained on large amounts of raw labeled or unlabeled data to learn complex patterns and relationships.
One of the main advantages of DL is its ability to automatically learn features from raw data, which can be a time-consuming and difficult task in traditional ML. Deep learning models are also highly scalable and can handle large datasets with high dimensionality, making them well-suited for image and speech recognition tasks.
However, deep learning models can also be more complex and computationally intensive than traditional machine learning models and may require more training data and specialized hardware. In addition, DL models can be more difficult to interpret, making it challenging to understand how they make predictions.
That being said, let’s take a broader look at some limitations and challenges deep learning faces.
Challenges and Limitations of Deep Learning
While deep learning has undeniably made significant strides in various fields (e.g., computer vision, natural language processing, and speech recognition), researchers and practitioners face several challenges and limitations. Some of the more prominent ones are the following.
Data Requirements
Deep learning models require a vast amount of labeled data to train accurately. This can be a significant challenge in domains where data is scarce or expensive (e.g., in medical sub-domains).
Interpretability
Deep learning models can be challenging to interpret, making it difficult to understand how they make decisions. This can be particularly problematic in domains where transparency is crucial (e.g., healthcare and finance).
Overfitting
A deep learning model is prone to overfitting, where it learns the training data too well and does not generalize well to new data. This can be addressed by using regularization techniques and larger datasets.
Computationally Expensive
Deep learning models are computationally expensive and require significant processing power to train and run. This can be a limitation for smaller organizations or individuals without access to powerful computing resources.
Lack of Robustness
Deep learning models can be sensitive to changes in the input data, leading to reduced robustness. In addition, adversarial attacks can exploit these vulnerabilities, leading to incorrect predictions.
Transfer Learning Limitations
While transfer learning has been successful in some domains, it has limitations in others. For example, transfer learning assumes that the underlying data distribution is similar between the source and target domains.
Bias and Fairness
Deep learning models can be biased if the training data does not represent the real-world population. This can lead to unfair predictions and perpetuate societal inequalities.
Researchers are continually working on mitigating these issues. New architectures, optimization techniques, data processing techniques, etc., are published yearly, which opens up several new possibilities for future research.
So what lies ahead?
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Future of Deep Learning
The future of deep learning is promising, as it continues to be one of the most rapidly evolving areas of AI research. Consequently, we may see several potential future advancements, including improved interpretability of DL models, enhanced transfer learning, increased efficiency, multimodal learning, reinforcement learning, and edge computing.
One of the primary challenges of deep learning models is the need for interpretability, which makes it difficult to understand how they make decisions. As a result, researchers are developing more interpretable DL models to increase transparency and trust in these systems. This will help address concerns around the “black-box” nature of DL models.
Enhanced transfer learning is another area of potential advancement. Transfer learning has succeeded in some domains, but researchers are improving its scalability and applicability to other areas. This will enable deep learning models to learn from more diverse and smaller datasets, reducing the need for large amounts of labeled data.
Efficiency is another area of focus for future advancements in deep learning. Continued improvements in hardware and software, such as specialized hardware for DL and more efficient algorithms, will help reduce the computational requirements of DL models. This will make them more accessible and scalable, allowing for wider adoption.
Multimodal learning is another area that shows great potential for the future of deep learning. This approach involves DL models that can simultaneously learn from multiple data modalities (e.g., audio, text, and images). This will enable more sophisticated and comprehensive AI applications.
Reinforcement learning is another area of deep learning that has shown great promise in domains (e.g., robotics and gaming). Continued research may lead to more powerful and versatile AI systems.
Finally, edge computing is an emerging trend that enables computations to be performed on devices at the network’s edge. This will allow more efficient and low-latency deep learning applications, particularly in IoT (Internet of Things) and autonomous systems.
Overall, deep learning is a rapidly evolving field with many exciting possibilities for the future. Continued research and development will enable the creation of more efficient, interpretable, and versatile DL models that can address a broader range of real-world problems.

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.