
In this tutorial, you will implement a CNN using Python and Keras. We’ll start with a quick review of Keras configurations you should keep in mind when constructing and training your own CNNs.

We’ll then implement ShallowNet, which as the name suggests, is a very shallow CNN with only a single CONV layer. However, don’t let the simplicity of this network fool you — as our results will demonstrate, ShallowNet is capable of obtaining higher classification accuracy on both CIFAR-10 and the Animals dataset than many other methods.
Note: This tutorial requires you to download the Animals dataset.
Keras Configurations and Converting Images to Arrays
Before we can implement ShallowNet, we first need to review the keras.json configuration file and how the settings inside this file will influence how you implement your own CNNs. We’ll also implement a second image preprocessor called ImageToArrayPreprocessor, which accepts an input image and then converts it to a NumPy array that Keras can work with.
Having problems configuring your development environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
The Image to Array Preprocessor
As I mentioned above, the Keras library provides the img_to_array function that accepts an input image and then properly orders the channels based on our image_data_format setting. We are going to wrap this function inside a new class named ImageToArrayPreprocessor. Creating a class with a special preprocess function will allow us to create “chains” of preprocessors to efficiently prepare images for training and testing.
To create our image-to-array preprocessor, create a new file named imagetoarraypreprocessor.py inside the preprocessing sub-module of pyimagesearch:
|--- pyimagesearch | |--- __init__.py | |--- datasets | | |--- __init__.py | | |--- simpledatasetloader.py | |--- preprocessing | | |--- __init__.py | | |--- imagetoarraypreprocessor.py | | |--- simplepreprocessor.py
From there, open the file and insert the following code:
# import the necessary packages from tensorflow.keras.preprocessing.image import img_to_array class ImageToArrayPreprocessor: def __init__(self, dataFormat=None): # store the image data format self.dataFormat = dataFormat def preprocess(self, image): # apply the Keras utility function that correctly rearranges # the dimensions of the image return img_to_array(image, data_format=self.dataFormat)
Line 2 imports the img_to_array function from Keras.
We then define the constructor to our ImageToArrayPreprocessor class on Lines 5-7. The constructor accepts an optional parameter named dataFormat. This value defaults to None, which indicates that the setting inside keras.json should be used. We could also explicitly supply a channels_first or channels_last string, but it’s best to let Keras choose which image dimension ordering to be used based on the configuration file.
Finally, we have the preprocess function on Lines 9-12. This method:
- Accepts an
imageas input. - Calls
img_to_arrayon theimage, ordering the channels based on our configuration file/the value ofdataFormat. - Returns a new NumPy array with the channels properly ordered.
The benefit of defining a class to handle this type of image preprocessing rather than simply calling img_to_array on every single image is that we can now chain preprocessors together as we load datasets from disk.
For example, let’s suppose we wished to resize all input images to a fixed size of 32×32 pixels. To accomplish this, we would need to initialize a SimplePreprocessor:
sp = SimplePreprocessor(32, 32)
After the image is resized, we then need to apply the proper channel ordering — this can be accomplished using our ImageToArrayPreprocessor above:
iap = ImageToArrayPreprocessor()
Now, suppose we wished to load an image dataset from disk and prepare all images in the dataset for training. Using a SimpleDatasetLoader, our task becomes very easy:
sdl = SimpleDatasetLoader(preprocessors=[sp, iap]) (data, labels) = sdl.load(imagePaths, verbose=500)
Notice how our image preprocessors are chained together and will be applied in sequential order. For every image in our dataset, we’ll first apply the SimplePreprocessor to resize it to 32×32 pixels. Once the image is resized, the ImageToArrayPreprocessor is applied to handle ordering the channels of the image. This image processing pipeline can be visualized in Figure 2.

Chaining simple preprocessors together in this manner, where each preprocessor is responsible for one, small job, is an easy way to build an extendable deep learning library dedicated to classifying images.
ShallowNet
Today, we’ll implement the ShallowNet architecture. As the name suggests, the ShallowNet architecture contains only a few layers — the entire network architecture can be summarized as: INPUT => CONV => RELU => FC
This simple network architecture will allow us to get our feet wet by implementing Convolutional Neural Networks using the Keras library. After implementing ShallowNet, I’ll apply it to the Animals and CIFAR-10 datasets. As our results will demonstrate, CNNs are able to dramatically outperform many other image classification methods.
Implementing ShallowNet
To keep our pyimagesearch package tidy, let’s create a new sub-module inside nn named conv, where all our CNN implementations will live:
--- pyimagesearch | |--- __init__.py | |--- datasets | |--- nn | | |--- __init__.py ... | | |--- conv | | | |--- __init__.py | | | |--- shallownet.py | |--- preprocessing
Inside the conv sub-module, create a new file named shallownet.py to store our ShallowNet architecture implementation. From there, open the file and insert the following code:
# import the necessary packages from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import Activation from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense from tensorflow.keras import backend as K
Lines 2-7 import our required Python packages. The Conv2D class is the Keras implementation of the convolutional layer. We then have the Activation class, which as the name suggests, handles applying an activation function to an input. The Flatten classes take our multi-dimensional volume and “flattens” it into a 1D array prior to feeding the inputs into the Dense (i.e., fully connected) layers.
When implementing network architectures, I prefer to define them inside a class to keep the code organized — we’ll do the same here:
class ShallowNet: @staticmethod def build(width, height, depth, classes): # initialize the model along with the input shape to be # "channels last" model = Sequential() inputShape = (height, width, depth) # if we are using "channels first", update the input shape if K.image_data_format() == "channels_first": inputShape = (depth, height, width)
On Line 9, we define the ShallowNet class and then define a build method on Line 11. Every CNN that we implement inside this book will have a build method — this function will accept a number of parameters, construct the network architecture, and then return it to the calling function. In this case, our build method requires four parameters:
width: The width of the input images that will be used to train the network (i.e., number of columns in the matrix).height: The height of our input images (i.e., the number of rows in the matrix)depth: The number of channels in the input image.classes: The total number of classes that our network should learn to predict. For Animals,classes=3and for CIFAR-10,classes=10.
We then initialize the inputShape to the network on Line 15 assuming “channels last” ordering. Lines 18 and 19 make a check to see if the Keras backend is set to “channels first,” and if so, we update the inputShape. It’s common practice to include Lines 15-19 for nearly every CNN that you build, thereby ensuring that your network will work regardless of how a user is ordering the channels of their image.
Now that our inputShape is defined, we can start to build the ShallowNet architecture:
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
On Line 22, we define the first (and only) convolutional layer. This layer will have 32 filters (K) each of which are 3×3 (i.e., square F×F filters). We’ll apply same padding to ensure the size of output of the convolution operation matches the input (using same padding isn’t strictly necessary for this example, but it’s a good habit to start forming now). After the convolution we apply an ReLU activation on Line 24.
Let’s finish building ShallowNet:
# softmax classifier
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
To apply our fully connected layer, we first need to flatten the multi-dimensional representation into a 1D list. The flattening operation is handled by the Flatten call on Line 27. Then, a Dense layer is created using the same number of nodes as our output class labels (Line 28). Line 29 applies a softmax activation function which will give us the class label probabilities for each class. The ShallowNet architecture is returned to the calling function on Line 32.
Now that ShallowNet has been defined, we can move on to creating the actual “driver scripts” used to load a dataset, preprocess it, and then train the network. We’ll look at two examples that leverage ShallowNet — Animals and CIFAR-10.
ShallowNet on Animals
To train ShallowNet on the Animals dataset, we need to create a separate Python file. Open your favorite IDE, create a new file named shallownet_animals.py, ensuring that it is in the same directory level as our pyimagesearch module (or you have added pyimagesearch to the list of paths your Python interpreter/IDE will check when running a script).
From there, we can get to work:
# import the necessary packages from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from pyimagesearch.preprocessing import ImageToArrayPreprocessor from pyimagesearch.preprocessing import SimplePreprocessor from pyimagesearch.datasets import SimpleDatasetLoader from pyimagesearch.nn.conv import ShallowNet from tensorflow.keras.optimizers import SGD from imutils import paths import matplotlib.pyplot as plt import numpy as np import argparse
Lines 2-13 import our required Python packages. Most of these imports you’ve seen from previous examples, but I do want to call your attention to Lines 5-7 where we import our ImageToArrayPreprocessor, SimplePreprocessor, and SimpleDatasetLoader — these classes will form the actual pipeline used to process images before passing them through our network. We then import ShallowNet on Line 8 along with SGD on Line 9 — we’ll be using Stochastic Gradient Descent to train ShallowNet.
Next, we need to parse our command line arguments and grab our image paths:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
# grab the list of images that we'll be describing
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
Our script requires only a single switch here, --dataset, which is the path to the directory containing our Animals dataset. Line 23 then grabs the file paths to all 3,000 images inside Animals.
Remember how I was talking about creating a pipeline to load and process our dataset? Let’s see how that is done now:
# initialize the image preprocessors
sp = SimplePreprocessor(32, 32)
iap = ImageToArrayPreprocessor()
# load the dataset from disk then scale the raw pixel intensities
# to the range [0, 1]
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.astype("float") / 255.0
Line 26 defines the SimplePreprocessor used to resize input images to 32×32 pixels. The ImageToArrayPreprocessor is then instantiated on Line 27 to handle channel ordering.
We combine these preprocessors together on Line 31, where we initialize the SimpleDatasetLoader. Take a look at the preprocessors parameter of the constructor — we are supplying a list of preprocessors that will be applied in sequential order. First, a given input image will be resized to 32×32 pixels. Then, the resized image will behave its channels ordered according to our keras.json configuration file. Line 32 loads the images (applying the preprocessors) and the class labels. We then scale the images to the range [0, 1].
Now that the data and labels are loaded, we can perform our training and testing split, along with one-hot encoding the labels:
# partition the data into training and testing splits using 75% of # the data for training and the remaining 25% for testing (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42) # convert the labels from integers to vectors trainY = LabelBinarizer().fit_transform(trainY) testY = LabelBinarizer().fit_transform(testY)
Here, we are using 75% of our data for training and 25% for testing.
The next step is to instantiate ShallowNet, followed by training the network itself:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=3)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=100, verbose=1)
We initialize the SGD optimizer on Line 46 using a learning rate of 0.005. The ShallowNet architecture is instantiated on Line 47, supplying a width and height of 32 pixels along with a depth of 3 — this implies that our input images are 32×32 pixels with three channels. Since the Animals dataset has three class labels, we set classes=3.
The model is then compiled on Lines 48 and 49, where we’ll use cross-entropy as our loss function and SGD as our optimizer. To train the network, we make a call to the .fit method of model on Lines 53 and 54. The .fit method requires us to pass in the training and testing data. We’ll also supply our testing data so we can evaluate the performance of ShallowNet after each epoch. The network will be trained for 100 epochs using mini-batch sizes of 32 (meaning that 32 images will be presented to the network at a time, and a full forward and backward pass will be done to update the parameters of the network).
After training our network, we can evaluate its performance:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=["cat", "dog", "panda"]))
To obtain the output predictions on our testing data, we call .predict of the model. A nicely formatted classification report is displayed on our screen on Lines 59-61.
Our final code block handles plotting the accuracy and loss over time for both the training and testing data:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
To train ShallowNet on the Animals dataset, just execute the following command:
$ python shallownet_animals.py --dataset ../datasets/animals
Training should be quite fast as the network is very shallow and our image dataset is relatively small:
[INFO] loading images...
[INFO] processed 500/3000
[INFO] processed 1000/3000
[INFO] processed 1500/3000
[INFO] processed 2000/3000
[INFO] processed 2500/3000
[INFO] processed 3000/3000
[INFO] compiling model...
[INFO] training network...
Train on 2250 samples, validate on 750 samples
Epoch 1/100
0s - loss: 1.0290 - acc: 0.4560 - val_loss: 0.9602 - val_acc: 0.5160
Epoch 2/100
0s - loss: 0.9289 - acc: 0.5431 - val_loss: 1.0345 - val_acc: 0.4933
...
Epoch 100/100
0s - loss: 0.3442 - acc: 0.8707 - val_loss: 0.6890 - val_acc: 0.6947
[INFO] evaluating network...
precision recall f1-score support
cat 0.58 0.77 0.67 239
dog 0.75 0.40 0.52 249
panda 0.79 0.90 0.84 262
avg / total 0.71 0.69 0.68 750
Due to the small amount of training data, epochs were quite speedy, taking less than one second on both my CPU and GPU.
As you can see from the output above, ShallowNet obtained 71% classification accuracy on our testing data, a massive improvement from our previous best of 59% using simple feedforward neural networks. Using more advanced training networks, as well as a more powerful architecture, we’ll be able to boost classification accuracy even higher.
The loss and accuracy plotted over time is displayed in Figure 3. On the x-axis, we have our epoch number and on the y-axis, we have our loss and accuracy. Examining this figure, we can see that learning is a bit volatile with large spikes in loss around epoch 20 and epoch 60 — this result is likely due to our learning rate being too high.
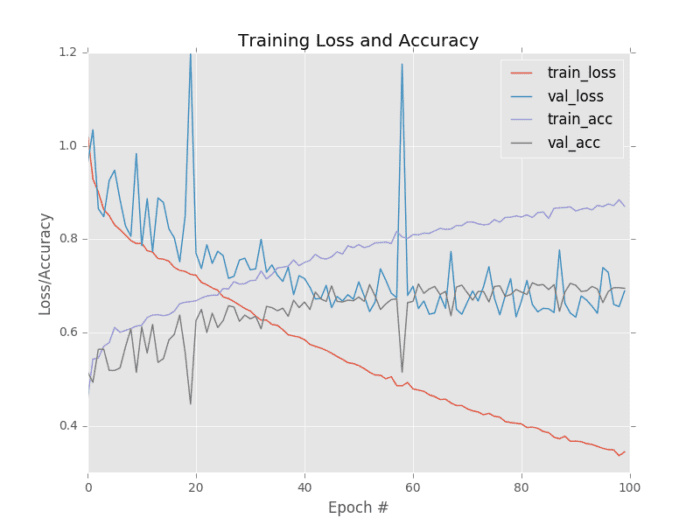
Also take note that the training and testing loss diverge heavily past epoch 30, which implies that our network is modeling the training data too closely and overfitting. We can remedy this issue by obtaining more data or applying techniques like data augmentation.
Around epoch 60 our testing accuracy saturates — we are unable to get past ≈70% classification accuracy, meanwhile our training accuracy continues to climb to over 85%. Again, gathering more training data, applying data augmentation, and taking more care to tune our learning rate will help us improve our results in the future.
The key point here is that an extremely simple Convolutional Neural Network was able to obtain 71% classification accuracy on the Animals dataset where our previous best was only 59% — that’s an improvement of over 12%!
ShallowNet on CIFAR-10
Let’s also apply the ShallowNet architecture to the CIFAR-10 dataset to see if we can improve our results. Open a new file, name it shallownet_cifar10.py, and insert the following code:
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from pyimagesearch.nn.conv import ShallowNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
Lines 2-8 import our required Python packages. We then load the CIFAR-10 dataset (pre-split into training and testing sets), followed by scaling the image pixel intensities to the range [0, 1]. Since the CIFAR-10 images are preprocessed and the channel ordering is handled automatically inside of cifar10.load_data, we do not need to apply any of our custom preprocessing classes.
Our labels are then one-hot encoded to vectors on Lines 18-20. We also initialize the label names for the CIFAR-10 dataset on Lines 23 and 24.
Now that our data is prepared, we can train ShallowNet:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=40, verbose=1)
Line 28 initializes the SGD optimizer with a learning rate of 0.01. ShallowNet is then constructed on Line 29 using a width of 32, a height of 32, a depth of 3 (since CIFAR-10 images have three channels). We set classes=10 since, as the name suggests, there are ten classes in the CIFAR-10 dataset. The model is compiled on Lines 30 and 31 then trained on Lines 35 and 36 over the course of 40 epochs.
Evaluating ShallowNet is done in the exact same manner as our previous example with the Animals dataset:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
We’ll also plot the loss and accuracy over time so we can get an idea how our network is performing:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
To train ShallowNet on CIFAR-10, simply execute the following command:
$ python shallownet_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] training network...
Train on 50000 samples, validate on 10000 samples
Epoch 1/40
5s - loss: 1.8087 - acc: 0.3653 - val_loss: 1.6558 - val_acc: 0.4282
Epoch 2/40
5s - loss: 1.5669 - acc: 0.4583 - val_loss: 1.4903 - val_acc: 0.4724
...
Epoch 40/40
5s - loss: 0.6768 - acc: 0.7685 - val_loss: 1.2418 - val_acc: 0.5890
[INFO] evaluating network...
precision recall f1-score support
airplane 0.62 0.68 0.65 1000
automobile 0.79 0.64 0.71 1000
bird 0.43 0.46 0.44 1000
cat 0.42 0.38 0.40 1000
deer 0.52 0.51 0.52 1000
dog 0.44 0.57 0.50 1000
frog 0.74 0.61 0.67 1000
horse 0.71 0.61 0.66 1000
ship 0.65 0.77 0.70 1000
truck 0.67 0.66 0.66 1000
avg / total 0.60 0.59 0.59 10000
Again, epochs are quite fast due to the shallow network architecture and relatively small dataset. Using my GPU, I obtained 5-second epochs while my CPU took 22 seconds for each epoch.
After 40 epochs ShallowNet is evaluated and we find that it obtains 60% accuracy on the testing set, an increase from the previous 57% accuracy using simple neural networks.
More importantly, plotting our loss and accuracy in Figure 4 gives us some insight to the training process demonstrates that our validation loss does not skyrocket. Our training and testing loss/accuracy start to diverge past epoch 10. Again, this can be attributed to a larger learning rate and the fact we aren’t using methods to help combat overfitting (regularization parameters, dropout, data augmentation, etc.).
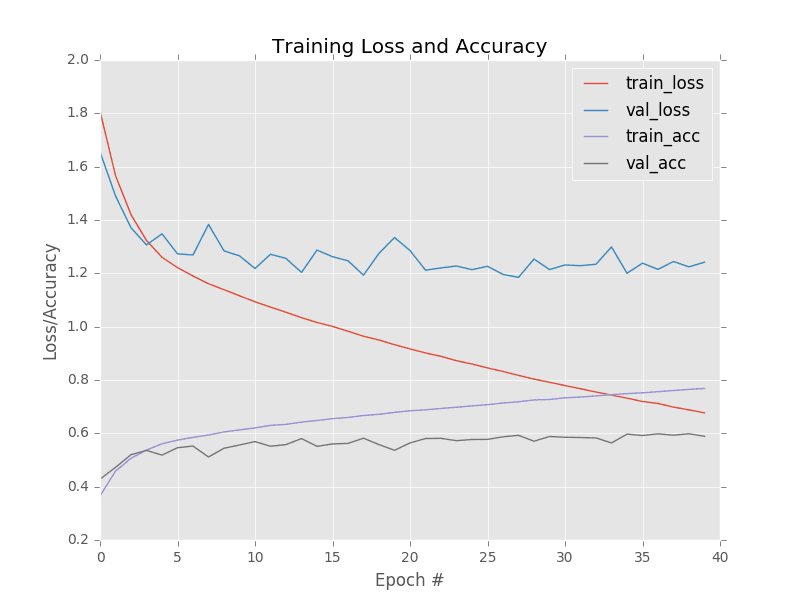
It is also notoriously easy to overfit on the CIFAR-10 dataset due to the limited number of low-resolution training samples. As we become more comfortable building and training our own custom Convolutional Neural Networks, we’ll discover methods to boost classification accuracy on CIFAR-10 while simultaneously reducing overfitting.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we implemented our first Convolutional Neural Network architecture, ShallowNet, and trained it on the Animals and CIFAR-10 dataset. ShallowNet obtained 71% classification accuracy on Animals, an increase of 12% from our previous best using simple feedforward neural networks.
When applied to CIFAR-10, ShallowNet reached 60% accuracy, an increase of the previous best of 57% using simple multi-layer NNs (and without the significant overfitting).
ShallowNet is an extremely simple CNN that uses only one CONV layer — further accuracy can be obtained by training deeper networks with multiple sets of CONV => RELU => POOL operations.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.